AI governance is breaking at scale. Five moves to fix it now.




The same failure, twice
AI governance frameworks built for single models are failing at scale because they cannot define what a model is, what counts as a change, or how a modification in one component propagates through a pipeline.
In January 2012, JPMorgan's Chief Investment Office replaced its Value-at-Risk model with a new one. The new model immediately halved the reported risk on a $50 billion synthetic credit portfolio. No one recorded the swap as a model change. No one measured how much the outputs shifted. No one reviewed why the change was made. The reduced risk figure emboldened traders to triple the portfolio to $157 billion in notional value. Total losses reached $6.2 billion.
Nearly a decade later, Zillow's home-buying algorithm was purchasing roughly 7,000 homes based on automated price predictions. The model depended heavily on housing market conditions that were shifting rapidly as pandemic-era demand cooled. No one was systematically measuring how sensitive predictions were to those environmental shifts. Every pricing error turned into a real financial commitment. Zillow wrote down over $500 million, shut down the Offers business, and laid off 2,000 employees.
Different industries. Different models. Different eras. The root cause was the same: no formal definition of what the model was, what constituted a change, or how to measure the downstream impact. Governance ran on judgment calls. Those judgment calls failed at scale.
The next one of these won't be a history lesson. The question is whether it happens to you, and whether you'll be ready when it does.

What the new regulatory landscape requires and where it leaves gaps
On April 17, 2026, the Federal Reserve, OCC, and FDIC jointly issued SR 26-2, replacing SR 11-7 as the foundational model risk management guidance for U.S. banking. SR 11-7 had directed institutions to validate their models for 15 years, but it never formally defined what a model is as a computational object. It could not specify what counts as a change, how to measure the magnitude of that change, or how a modification in one component propagates through a pipeline of interconnected models.
SR 26-2 takes a different approach — and in some ways makes the governance problem harder, not easier. It replaces prescriptive rules with principles, explicitly stating that non-compliance will not result in supervisory criticism. But it also preserves regulators' "unsafe and unsound practices" authority. The practical effect: the burden of proving your governance posture was defensible has shifted entirely onto each institution. There is no longer a checklist to point at. There is only the evidence your organization has built.
Critically, SR 26-2 explicitly carved out generative AI and agentic AI from its scope, characterizing them as "novel and rapidly evolving." This creates a governance gap at exactly the wrong moment. Institutions deploying LLMs, retrieval-augmented generation systems, and agentic pipelines now operate without a domestic federal framework for those systems — while the EU AI Act, Colorado AI Act, NAIC model bulletin language (adopted in 24+ states), and Canada's OSFI E-23 all apply to AI.
Now is the moment for banks to get this right, not just because of SR 26-2, but because the regulatory perimeter is fragmenting globally. The EU AI Act introduces new obligations for high-risk AI systems taking effect August 2, 2026. Providers must complete conformity assessments, finalize technical documentation, and establish continuous monitoring. Many U.S. firms operating globally are already building to it because it remains the most concrete AI governance standard that exists at scale. The EU AI Act requires organizations to assess "substantial modifications" to their AI systems, yet does not define "substantial" with enough precision to automate the determination.
Without a formal definition of model identity — for traditional ML models under SR 26-2 and for GenAI systems operating in the regulatory gap — institutions cannot distinguish a substantial modification from a routine update except through expert judgment. That is the same failure mode that enabled the London Whale losses in 2012.
Why this is getting harder, not easier
The governance surface area has expanded dramatically since SR 11-7 was issued — and SR 26-2, while lighter in prescription, doesn't shrink the underlying operational complexity. Modern AI systems are not single models. They are pipelines, ensembles, and agentic architectures where multiple models call each other, share data sources, and make routing decisions dynamically. Third-party model APIs can change without the consuming organization's knowledge. System prompts, data feeds, and configuration thresholds can shift model behavior without any version change on record.
The result: a gap now exists between what banks built under SR 11-7 and what they need to operate defensibly under SR 26-2 — and separately, what they need to self-govern the GenAI and agentic systems the new guidance deliberately left out of scope. We've condensed this knowledge gap down to five questions that every governance framework should be able to answer, and currently cannot. These are not edge cases. They are the core of how modern AI systems actually operate.
Five moves to make to fix AI governance before the August 2026 deadline
Each of these moves directly addresses one of those unanswerable questions and converts a judgment call into a computation.
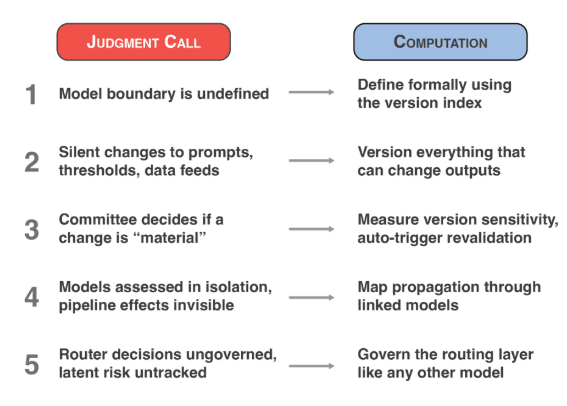
1. Define the model boundary formally
The model boundary is the line between what is versioned as part of the model and what belongs to the operating environment: data sources, compute infrastructure, and configuration settings such as thresholds and system prompts.
Ask yourself: What is inside the model, and what is part of the operating environment? The answer is the version index. Everything versioned together under a single version number is the model. Everything else is the environment: data sources, compute infrastructure, and configuration settings such as thresholds and system prompts. If an organization cannot draw this line consistently, it cannot determine whether something changed inside the model or around it. Most institutions today cannot draw this line.
2. Version everything that can change outputs
Every component that can change model outputs (including approval thresholds, system prompts, and data feeds) requires a version number and a change log. Model weights are only one of many components that affect what a model produces. The approval threshold on a credit model is a configuration setting that can flip decisions without any retraining. A rewritten system prompt on a customer-facing LLM can change behavior overnight. A refreshed data feed can shift outputs across the portfolio. If a component can change the output, it needs a version number and a log. Otherwise, the organization is in the same position as JPMorgan in 2012: something changed, and no one recorded it.
3. Measure version sensitivity before deploying any model change
Before deploying any model change, measure the magnitude of the output shift across a representative population and set a threshold tied to business materiality. When a model is retrained or a component is updated, institutions should measure the magnitude of the output shift across a representative population before deployment. Set a threshold tied to business materiality. If the shift exceeds the threshold, trigger revalidation automatically. Not by committee. JPMorgan's VaR model swap produced a 50% output shift overnight. If that number had been measured and compared against a threshold, mandatory review would have been triggered before the portfolio tripled.
4. Map risk propagation through pipelines, not just model by model
A small change at the front of a pipeline can amplify as it moves through downstream models. Institutions that evaluate models in isolation miss the compounding effects that drive the largest losses.
A data feed update that shifts feature values by a fraction of a percent can, after passing through a prediction model and a decision engine, flip real decisions for a meaningful share of the population. SR 26-2 acknowledges aggregate risk, but gives institutions a single paragraph and no framework for measuring it. Enterprise-level model risk assessment is now each institution's problem to solve. Organizations that evaluate models in isolation are missing the compounding effects that drive the largest losses.
5. Establish governance for the routing layer in agentic systems
In agentic AI systems, the routing layer, the component that decides which tool to call or which sub-model to invoke, carries governance risk and requires the same treatment as the models it chooses between.
When an LLM decides which tool to call, which sub-model to invoke, or which branch of a pipeline to execute, the routing decision itself carries risk. An agent that nearly selected a different tool is carrying latent risk that no traditional governance framework accounts for. If an organization is deploying agentic AI, the router needs the same governance treatment as the models it chooses between: versioned, monitored, and subject to sensitivity analysis.
The formal foundation exists today
These five moves are grounded in a formal framework I developed in a recent paper, "The Model Operator: Formal Foundations for Model Governance". The paper defines a model as a versioned, typed operator with a formally separable runtime environment. From that single definition, the model boundary, version sensitivity, propagation calculus, and risk functional all follow.
None of this is aspirational. It is computable. Institutions that operationalize these five moves now will be ahead of both the August 2026 deadline and the next governance failure at scale.
Moving forward
SR 26-2 replaced the SR 11-7 rulebook with a principles-based framework and handed the burden of proof to each institution. That makes the operational infrastructure for governance more important, not less. For organizations looking to put these principles into practice, Domino Data Lab provides the enterprise AI platform that supports governed model development, deployment, and monitoring across the full model lifecycle. Domino's governance capabilities, including model inventory, reproducibility controls, lineage tracking, and approval workflows, provide the operational infrastructure these formal principles require, for both SR 26-2 in-scope models and the GenAI and agentic systems operating in the governance gap the new guidance left open.
If you work in model risk, AI governance, or regulatory compliance, I welcome the conversation.
Rev New York on May 19 is the perfect venue to start taking action: keynoted by SR 11-7 architect David Palmer, it will also feature a panel I'll lead about this topic with model risk management leaders who have experience at Capital One, TIAA, and New York Life. Register now.
You can also reach me on LinkedIn or through Domino Data Lab.