The Autonomous AI Agent Era Is Here. Are You Ready?



Over the past year, enterprise AI crossed a meaningful threshold. Early adopters are running production systems that plan multi-step workflows, act on them, and self-correct when something breaks. They are resolving support tickets, executing deployment pipelines, monitoring production environments, and completing research tasks without a human in the loop at every step.
This shift from AI that assists to AI that operates is not incremental. It changes the infrastructure required, the governance model around it, and the competitive dynamics for organizations that delay.
Why intelligence alone is not enough
Most enterprise AI systems today are capable but constrained. An LLM can produce a precise SQL query but cannot execute it. It can suggest a code fix but cannot test, validate, and deploy it. It can diagnose a production failure in a Kubernetes cluster but cannot resolve it. The intelligence is there, but the ability to act on it is not.
That gap is what autonomous agents close. By combining reasoning, persistent memory, access to tools and external systems, and the capacity to self-correct, agents move from generating outputs to producing outcomes.
Chatbot
Copilot (AI assistant)
Autonomous Agent
How it works
Stateless Q&A
Embedded assistant within a single application
Pursues goals across tools, systems, and sessions
Memory
None
Limited to the current session
Persistent across sessions
Tools access
None
Single application only
Broad access to external tools and systems
Human involvement
Every interaction
Every action
Defined oversight points only
What it owns
Answers
Suggestions
Outcomes
The moment the industry recognized the pattern
The building blocks of autonomous agents had been taking shape across dozens of labs and startups throughout 2025. But the moment the pattern crystallized was not a product launch from a major AI lab. It was a weekend project by Austrian developer Peter Steinberger.
In November 2025, Steinberger built a prototype in roughly one hour: an AI agent he could message through WhatsApp that would actually do things on his behalf. He connected an LLM to WhatsApp's API, gave it tools (web search, file operations, code execution), and let it run autonomously. He called it "Clawdbot" and pushed it to GitHub.
Then he kept layering on exactly the capabilities that would become the industry standard. Persistent memory so the agent could recall past interactions and adapt over weeks. A skills system with instruction files. Tool access to calendars, email, browsers, and file systems. Scheduled tasks. Cross-platform messaging through Telegram, Signal, and iMessage.
By late January 2026, following a trademark complaint from Anthropic, Steinberger later renamed the project to OpenClaw. The rename only accelerated its momentum. It hit 100,000 GitHub stars by February, making it one of the fastest growth curves in GitHub history, and surpassed over 200,000 stars by March[1]. Lex Fridman compared its cultural impact to the ChatGPT launch[2]. Jensen Huang declared at GTC 2026 that "OpenClaw is the operating system for personal AI." Sam Altman hired Steinberger to join OpenAI.
Here is what matters most for enterprise teams: OpenClaw did not invent a new architecture. It validated one. Developers looked at it and saw the architecture they had been piecing together independently, assembled into a single coherent system that actually worked. And within weeks, every major AI company scrambled to match it.
Why agent architectures are converging on the same building blocks
More than 50 agentic frameworks have emerged in the past year. What is striking is not the volume but what they share. Despite being built by different teams for different purposes, they have converged on the same underlying architecture.
Every serious implementation contains eight components, best understood as a continuous loop. The brain sits at the center, powered by one or more models. Memory supplies persistent context across sessions. Knowledge connects the brain to enterprise data through vector stores, knowledge graphs, and SQL systems. Tools (APIs, browsers, file systems) interact with external systems. Workflows and sub-agents enable complex multi-step operations. Skills provide reusable capabilities the agent can invoke without human intervention. Tasks give the agent a structured way to track progress, manage dependencies, and resume interrupted work.
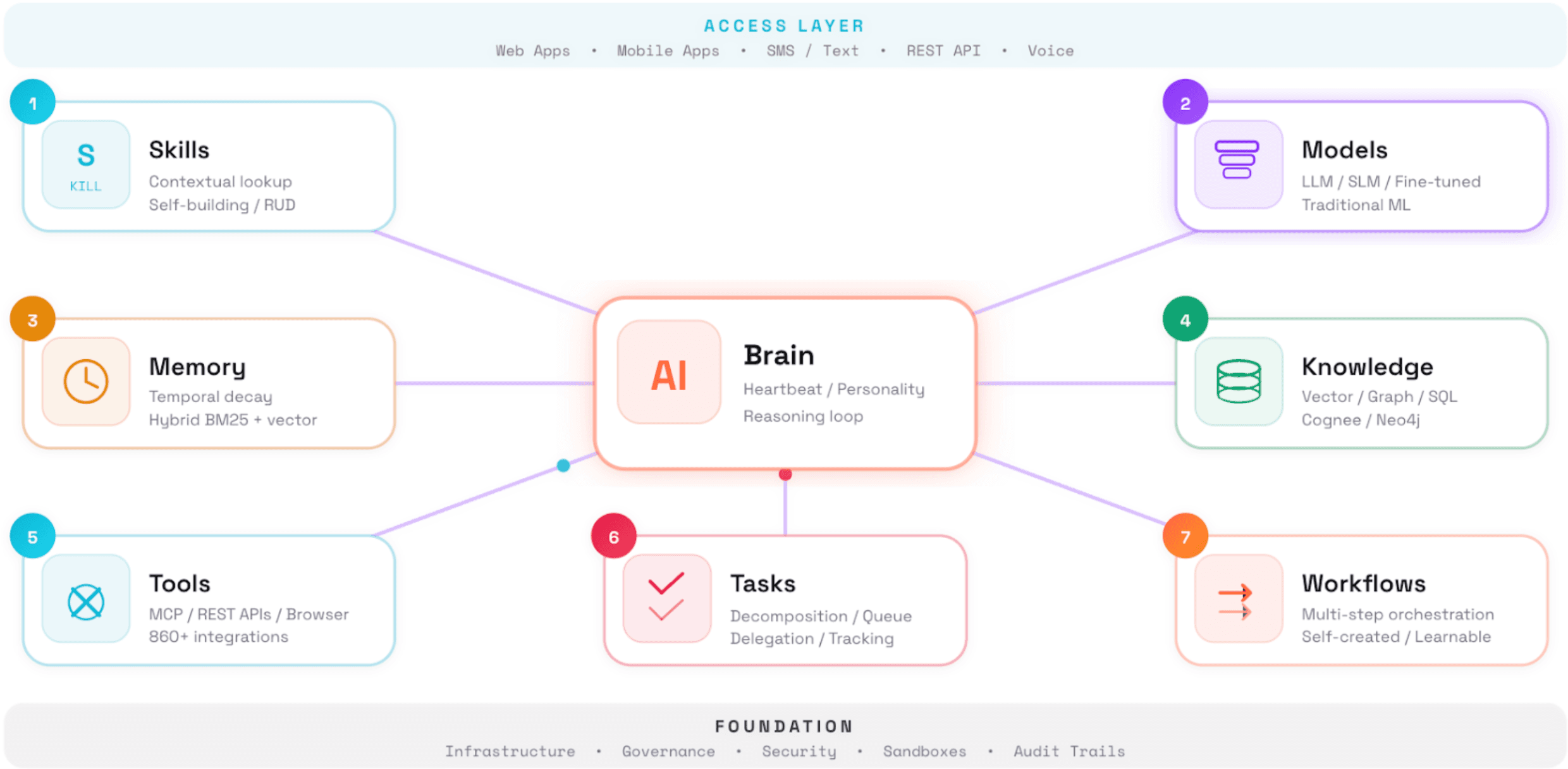
This convergence is meaningful in two ways. First, it confirms the architecture is not arbitrary but reflects what autonomous systems actually require at scale. Second, and more importantly, the architecture itself is commoditizing. Every framework offers these building blocks. Every major platform has shipped them. If every organization has access to the same agent skeleton, the skeleton is not the competitive advantage.
The advantage comes from what you train into the skeleton: your proprietary data, your institutional workflows, the skills your teams build that encode how your business actually operates, and the memory that accumulates as agents learn from your specific environment. A generic agent can summarize a document. An agent trained on your underwriting guidelines, connected to your policy database, and shaped by months of feedback from your claims adjusters can triage a new claim in seconds. The architecture is the same. The data, skills, and accumulated context are what make the difference.
Coding assistants proved it. The rest of the industry confirmed it.
If you want proof that this architecture is becoming an industry standard, look at what happened in the three months after OpenClaw went viral. Three dominant coding platforms, building independently, all shipped the same capabilities.
- Anthropic's Claude Code moved fastest: Auto Memory (persistent context across sessions), a Plugin Ecosystem with an open "Agent Skills" standard, Computer Use (clicking through browser UIs and navigating the screen), Channels (async task assignment over Telegram and Discord), Agent Teams (up to 10 parallel sub-agents with isolated 1M-token context windows), Scheduled Tasks (cloud jobs that run when your computer is off), and Remote Control/Dispatch (manage sessions from mobile). According to SemiAnalysis, 4% of all public GitHub commits were authored by Claude Code as of February 2026, doubling in a single month, with projections of 20%+ by year end.[3]
- GitHub Copilot's coding agent now spins up isolated VMs to write code, run tests, and open pull requests from issues autonomously. Since February 2026, users can assign the same issue to Claude, Codex, and Copilot simultaneously: three agents, three draft PRs, pick the best.
- Cursor followed the same path with background cloud agents, a plugin marketplace (Datadog, Stripe, Figma), custom rules files, and sub-agent orchestration. Cursor reports 35% of its own merged PRs come from cloud agents.[4]
Map any of these against the eight-component architecture, and they align precisely. Three companies, same destination, because this is what autonomous systems require.
The response extended far beyond coding tools.
- NVIDIA launched NemoClaw at GTC 2026, a security and governance layer for OpenClaw with kernel-level sandboxing, an out-of-process policy engine, and a privacy router for keeping sensitive data local. NVIDIA is integrating these guardrails with Cisco, CrowdStrike, Google, and Microsoft Security.
- Perplexity launched Computer, orchestrating 19 AI models simultaneously in isolated cloud environments with 400+ app integrations; over 100 enterprise customers demanded access in a single weekend.
- Anthropic shipped Cowork (Claude Code for general computing, built by four engineers in ten days) and added computer use across both products, letting Claude operate your machine while you are away.
Different companies, different markets, different business models. The same architecture. But notice what none of these products provide: your claims data, your customer interaction history, your compliance requirements, your internal APIs. These are extraordinary general-purpose tools. The moment you need an agent that understands your business, you are building, not buying.
Why agents need both frontier models and traditional ML
The instinct is to reach for the most capable frontier model. In practice, the best deployments make more nuanced choices. Frontier APIs like Claude, Gemini, and GPT offer strong reasoning but route data off the network. Self-hosted open source models like Mistral, MiniMax, and Qwen provide data sovereignty but require GPU infrastructure.
Most mature deployments use a hybrid approach. Frontier models handle sophisticated reasoning. Local models handle sensitive data or latency-critical tasks. An AI gateway that manages access to both is quickly becoming essential infrastructure.
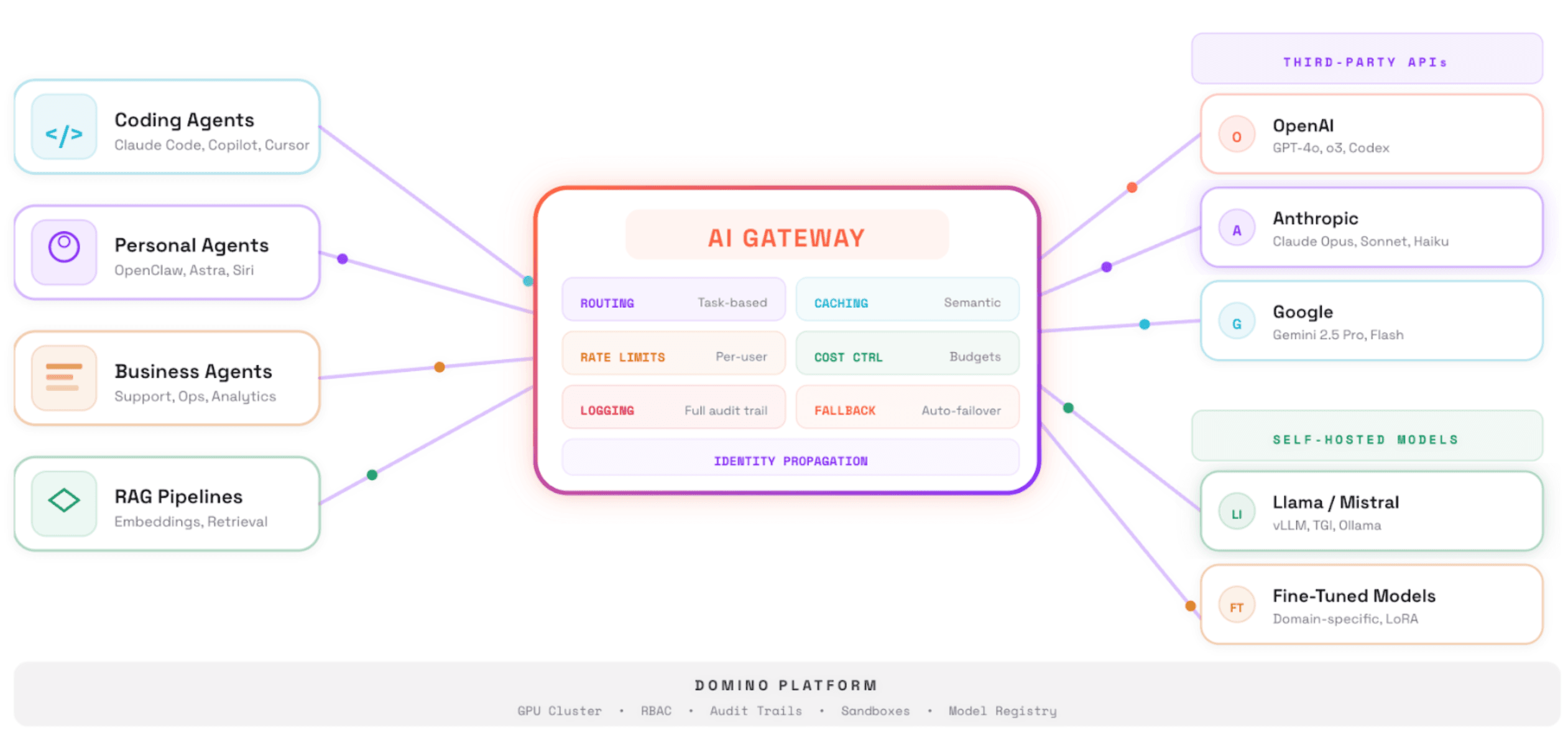
The deeper insight is that agents do not replace traditional ML models. They orchestrate them. A well-tuned XGBoost model remains faster, cheaper, and more interpretable than an LLM for fraud detection or demand forecasting. The best architectures treat classical models as first-class components, with the agent deciding when to invoke them.
This is where internal data becomes decisive. A frontier model provides general reasoning. But the fraud model trained on your transactions, the demand model calibrated to your supply chain, the churn model built on your customer behavior: these carry the institutional intelligence. The agent orchestrates them. Both layers need a home, and they need to be governed together.
The implementation challenges that trip up every team
The technology is mature enough for production. Organizational and infrastructure readiness is where most enterprises fall short.
Infrastructure readiness. Agents run continuously, consume resources unpredictably, and require isolation between workloads. NemoClaw exists precisely because OpenClaw had no controls over data access, information flow, or auditability. Getting infrastructure right before scaling is far cheaper than retrofitting after.
Cost at scale. A single complex workflow can consume millions of tokens across reasoning steps, tool calls, and retries. Agent Teams in Claude Code use 3-4x the tokens of sequential work. Without spend controls from the start, costs compound faster than value.
Governance and compliance. Every tool call and file modification must be logged, attributable, and auditable. Cisco's security team tested a third-party OpenClaw skill and found it performed data exfiltration without user awareness [5]. In March 2026, Chinese authorities restricted state enterprises from running OpenClaw due to security concerns. The risks multiply in multi-agent environments: a peer-reviewed study showed GPT-4 based pricing agents autonomously coordinated on pricing strategies to the detriment of consumers, without any instruction to do so [6]. Governance cannot be retrofitted.
Identity and access control. When an agent acts on behalf of a user, permissions must be clearly defined and enforced. Without identity propagation, you create accountability gaps that neither auditors nor security teams will accept.
Observability. Agents make dozens of interdependent decisions per task. Without trace-level visibility into reasoning steps and tool interactions, debugging and compliance become guesswork.
Every one of these challenges falls in the generalizable 80%. They are hard to build, essential to get right, and identical across industries. No organization gains advantage by inventing its own sandbox isolation or audit trail format. These are infrastructure problems, not differentiation problems.
The real decision is not build versus buy
Most enterprise teams reach a familiar fork. Buy an off-the-shelf platform and hit a ceiling the moment you need agents that understand your business. Or build from scratch and spend six to twelve months on plumbing (sandboxes, GPU provisioning, model access, persistent storage, identity propagation, observability, audit infrastructure) before writing a single line of agent logic.
Both paths have serious problems.
There is a third path. You build your agents, skills, data connections, and domain logic on top of a platform where the generalizable 80% of the infrastructure already exists. The secure sandboxes are provisioned. The GPU access is managed. An AI gateway standardizes connections to multiple vendors' models while also giving teams the ability to host open source models directly on the platform. Identity propagation is built in. Observability and audit trails work out of the box. You invest your time and talent in the 20% that differentiates your business: the data you feed agents, the skills your teams create, the workflows that encode how your organization operates, and the feedback loops that make agents smarter over time.
The architecture is the starting line. Your data and your teams' expertise are the race.
From architecture to production with Domino
Most enterprise agentic AI initiatives do not fail because the technology is wrong. They fail because the infrastructure, governance, and observability required to run it safely were never built.
Domino is built for the third path: the platform where your teams build what differentiates your business, on top of infrastructure that already handles everything that does not.
The generalizable 80% is there from day one. Framework-agnostic execution environments that support any agent architecture. An AI gateway that standardizes connections to multiple vendors' frontier models alongside the ability to host open source models directly on Domino. GPU provisioning and persistent storage managed at the platform level. Identity propagation through every agent action. Trace-level observability across prompts, tool calls, intermediate reasoning steps, and outputs. A full audit trail that satisfies compliance requirements without requiring your teams to build one.
But the real value of Domino is what it enables on top of that infrastructure. Your teams connect agents to your proprietary data, behind your access controls, with full lineage tracking. They build domain-specific skills that encode how your business actually operates. They train and deploy the classical ML models (fraud detection, demand forecasting, churn prediction, pricing optimization) that agents orchestrate alongside frontier LLMs. They iterate on agent behavior in staging environments before promoting to production, with the same rigor applied to traditional model deployment. And every cycle of feedback, every skill refined, every data connection added compounds into an institutional asset that no competitor can replicate by subscribing to the same SaaS product.
Autonomous agents and the traditional ML models they orchestrate operate side by side on Domino, with the same lineage, access controls, staging environments, and audit trail across both. That is not a feature list. That is the operational foundation for capturing value that is specific to your organization, at scale, with governance built in from the start.

The window for competitive advantage is open
The architecture is proven and converging fast. The differentiator is no longer which framework you pick. It is how quickly your teams can start training agents on your data, building skills around your workflows, and compounding institutional knowledge that no competitor can replicate.
That work starts on Domino. The infrastructure is ready. The governance is built in. The only question is whether your organization begins building that advantage now, or spends the next twelve months on plumbing while others pull ahead.
2026 is the year autonomous AI stopped being a roadmap item and started being a competitive differentiator. The organizations that move with discipline and the right platform will define what enterprise AI looks like for the next decade.
---------------------------------------------------------------------------
[1] GitHub star counts for OpenClaw varied across sources depending on date of measurement, ranging from 135,000 to over 200,000 stars between February and March 2026. The figure cited reflects a snapshot from March 2026. For the most current count, see github.com/openclaw/openclaw
[2] Lex Fridman, The Lex Fridman Podcast, episode #491, "OpenClaw: The Viral AI Agent that Broke the Internet — Peter Steinberger," February 12, 2026. Transcript available at lexfridman.com/peter-steinberger-transcript
[3] Doug O'Laughlin, Jeremie Eliahou Ontiveros, Jordan Nanos, Dylan Patel, et al., "Claude Code is the Inflection Point," SemiAnalysis, February 5, 2026. newsletter.semianalysis.com/p/claude-code-is-the-inflection-point
[4] Michael Truell, "35% Of Merged PRs At Cursor Now Created By Autonomous Agents," Cursor, February 24, 2026. Reported by OfficeChai, March 2, 2026: officechai.com/ai/35-of-merged-prs-at-cursor-now-created-by-autonomous-agents-says-ceo-michael-truel. See also Cursor's official Bugbot Autofix announcement: cursor.com/blog/bugbot-autofix
[5] Cisco AI Defense (2026). Personal AI Agents like OpenClaw Are a Security Nightmare. Cisco Blogs. https://blogs.cisco.com/ai/personal-ai-agents-like-openclaw-are-a-security-nightmare
[6] Bloomberg (March 11, 2026). China Moves to Curb OpenClaw AI Use at Banks, State Agencies. https://www.bloomberg.com/news/articles/2026-03-11/china-moves-to-limit-use-of-openclaw-ai-at-banks-government-agencies