LLMOps in Domino - integrating LLMs with model registry and Domino Model API
Author
Sameer Wadkar
Principal Solution Architect
Article topics
MLOps, LLMOps, LLM Serving, Finetuned LLM Serving, Model Registry for LLMOps
Intended audiences
Domino Administrators, Data Scientists
Overview and goals
Using Domino for Large Language Models (LLMs) has been a common request from customers. Customers want to be able to download LLMs, fine tune LLMs, reliably register these LLMs to model registry and use them for inference in batch mode as well as via model endpoints.
Managing the LLM lifecycle in Domino, especially those deployed as endpoints, presents a few challenges:
- Size of LLM binaries whether downloaded or fine-tuned tend to be in the order of GBs.
- If you register the LLM binaries as model artifacts and try to deploy them as model endpoints, you will end up with a model image with size in GB scale.
- This makes it expensive to store in the Docker registry and takes long waiting times for the mode API endpoint to start.
- Furthermore, if you have multiple replicas of the endpoint, each endpoint downloads the model API image if these are deployed on different underlying instances.
- Storing multiple copies of model API images can get expensive.
Using the standard model deployment lifecycle for LLMs in Domino incurs both financial and performance cost. This article will review how we can avoid these pitfalls while still taking advantage of Domino features like Domino Model Registry and Domino Model Endpoints.
When should you consider using the approach outlined in this document?
- Download and optionally fine tune LLMs in Domino
- Deploy these LLMs to Domino Model endpoints
- Ensure that all the check and balances provided by Domino for model management and deployment are respected for LLMOps
- Leverage LLMOps for Model endpoints in a performant and cost-effective manner
Why does the LLMOps approach outlined in this document help achieve the above goals?
You want to deploy LLMs to model endpoints without incurring the operational and financial costs of storing and downloading massive model images repeatedly. While you still want to use Domino as the System of Record, the goal is to register tested LLMs in the Experiment Manager and Model Registry without embedding the full model binaries into the model image.
The approach outlined below allows Domino users to store LLM artifacts in the Experiment Manager while bypassing the need to package them directly into the model image. Instead, the LLM binaries are copied to a well-known path in a predefined dataset, which is then referenced by the registered model. This eliminates the need to include large binaries as part of the model image.
As a result:
- The model image remains lightweight.
- Endpoint startup times improve.
- Storage and compute costs are significantly reduced.
In other words, operationally and cost efficient LLM deployment to a model endpoint is made possible through secure dataset sharing between Domino workloads (such as Workspaces and Jobs) and model endpoints.
How to deploy LLM as endpoints in Domino
In this section, you’ll discover how to achieve the goals outlined above. Bear in mind that this is only a reference for implementation. While it works, you may need to customize it to suit your specific requirements.
There are two prerequisites for using this approach:
- Create users who will logically belong to one of two mutually exclusive roles:
- Data scientist
- Endpoint deployer
- Create two datasets:
domino-models-dev– Accessible to both user roles listed abovedomino-models-prod– Accessible only to the “endpoint deployer” role
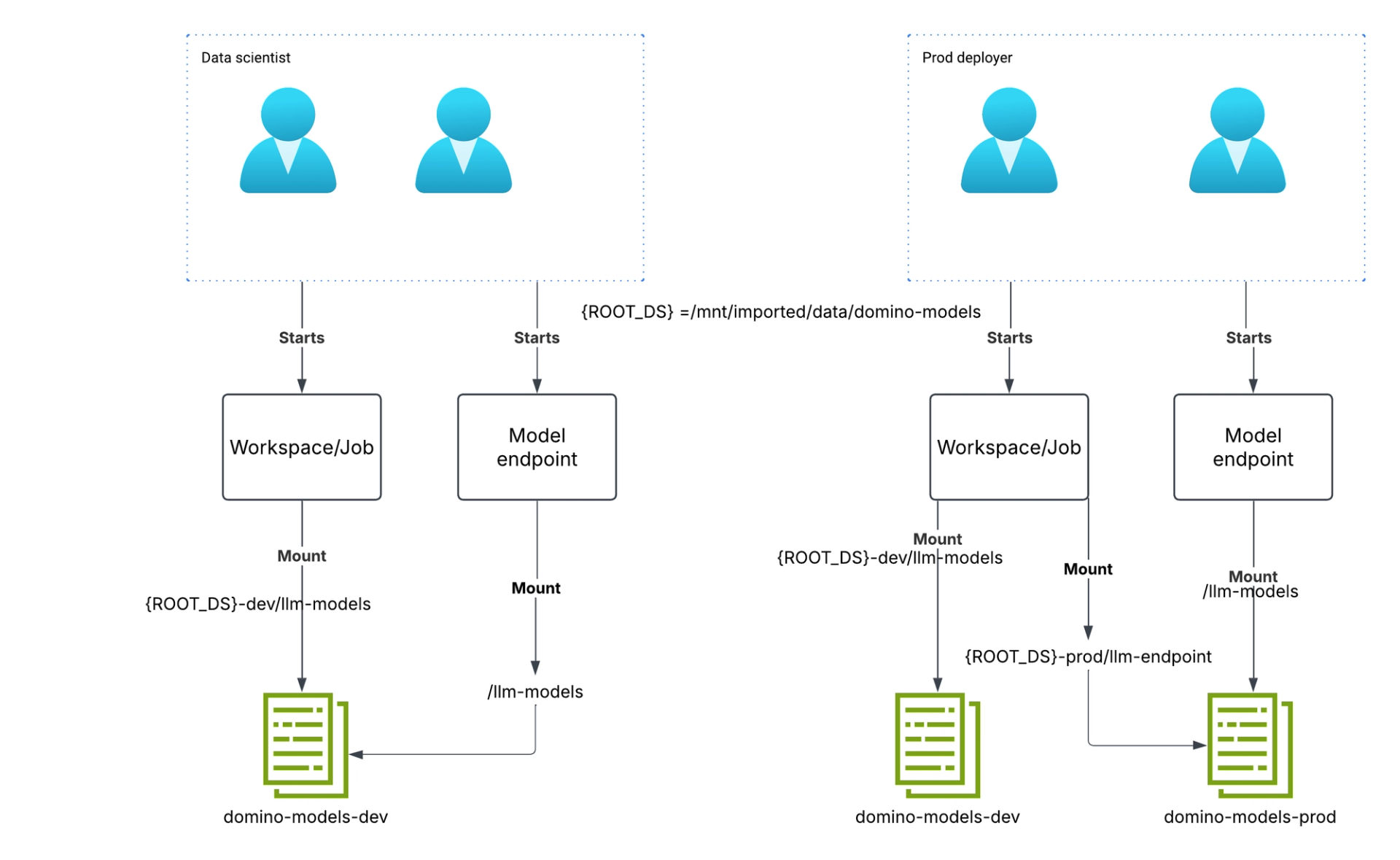
The figure below illustrates this.


The user roles are mutually exclusive. If you want a user in the “prod deployer” role to also function as a data scientist, we recommend creating a Domino Service Account and assigning it the “prod deployer” role. As mentioned earlier, it is possible to support users being in multiple roles by introducing more complexity into the design. However, for the purposes of this illustration, let’s stick to mutually exclusive roles to keep the approach simple.
The end result for workloads and model endpoints started by “data scientist” users is the following mount structure. The convention is to store model binaries in the llm-endpoint subfolder of the dataset. The folder structure shown below applies to a workload in a Git-based project. However, the same mechanism works for a Domino File System (DFS)-based project as well — in that case, the mount path would be: /domino/datasets/domino-models-dev/llm-models.
Dataset
Workload mount
Model API mount
domino-models-dev
/mnt/imported/data/domino-models-dev/llm-models
/llm-models
domino-models-prod
NOT MOUNTED
NOT MOUNTED
The same result when the workload and Model endpoint is launched by a “prod deployer”.
Dataset
Workload mount
Model API mount
domino-models-dev
/mnt/imported/data/domino-models-dev/llm-models
NOT MOUNTED
domino-models-prod
/mnt/imported/data/domino-models-prod/llm-models
/llm-models
The datasets are mounted into the workloads simply by giving the users the appropriate read-write access to the users and by adding the above datasets to the project of interest. For the model endpoints, the mounts are added via Domsed mutation. An example definition of the mutation can be seen here. Details around how the mutation works can be found in the Github repository at this location. The datasets and the mounts for workloads and model endpoints started by each user are illustrated in the figure below.
We are now ready to illustrate the process of downloading, fine-tuning, and deploying LLMs as model endpoints in Domino. This will be done in a way that is both operationally and cost-efficient, without sacrificing Domino’s critical role as a system of record.
The process begins with a user in the “data scientist” role. When the user starts a workspace in this project, the dataset domino-models-dev is mounted automatically.
To illustrate this process, we will use a smaller model — TinyLlama. This choice enables testing without the need for expensive GPU resources. The hardware tier where this code was tested had 4 cores and 15GB RAM. You can instead test with a larger model (true LLM) with a hardware tier with a GPU and more memory.
First, download the TinyLlama model locally into the /home/ubuntu folder of the workspace. For larger models, download them into a dataset instead — use the project’s local dataset as scratch space, not the shared datasets mentioned earlier. Follow the instructions in the notebook local_download.ipynb to download and test the TinyLlama model locally.
The end result of running this notebook will be:
- TinyLlama model downloaded to folder
/home/ubuntu/TinyLlama - A simple Python program tests the model locally by loading it from this folder and invoking it with a test prompt.
Next, as a data scientist, you are ready to test this model by wrapping it in the mlflow.pyfunc.PythonModel class. In the same workspace, run the notebook register_and_test_model.ipynb to:
- Define the model class
- Register it to MLflow without uploading the model binary artifacts
- Test it locally
- Finally, test it as a model endpoint
This is the key aspect of the design, enabled by setting the environment variable ONLY_LOCAL_TESTING=True in the notebook before publishing the model to the model registry.
The key idea here is to use the MLflow technique of nested runs. A parent run is used to publish the model binaries to MLflow, while a child run references the parent run ID in the model context. The model is then registered from the child run. This enables deployment as a Domino Model Endpoint without bundling the model binaries with the registered model. Instead, the registered model context references the parent run ID, which contains the actual binaries.
This is the model registration code executed from inside the child MLflow run:
model_context = {
"run_id":parent_run_id
}
config_path = "/tmp/model_context.json"
with open(config_path, "w") as f:
json.dump(model_context, f)
model_info = mlflow.pyfunc.log_model(
artifact_path="",
python_model=LLMModel(),
artifacts={"model_context": config_path},
pip_requirements=[
f"torch=={torch_version}",
f"transformers=={transformers.__version__}",
f"accelerate=={accelerate.__version__}"
]
)Earlier in the parent run, the model binaries are written to the mounted dev dataset as follows:
parent-run-id=...
LOCAL_MODEL_FOLDER=”/home/ubuntu/TinyLlamagpt2”
target_local_dir=f”/domino/datasets/domino-models-dev/llm-models/{parent-run-id}”
shutil.copytree(LOCAL_MODEL_FOLDER, target_local_dir, dirs_exist_ok=True)
#KEY DESIGN. THESE BINARIES CAN BE LARGE, YOU DO NOT PUBLISH THEM UNTIL YOU ARE CONFIDENT THE MODEL WORKS
if not ONLY_LOCAL_TESTING:
mlflow.log_artifacts(target_local_dir,artifact_path="model")
When the “data scientist” deploys the model the domino-models-dev location is mounted into the model at the location: /llm-models
Next the model is registered to Domino Model Registry and deployed as a model endpoint. The model finds the associated model binaries from the dataset location as illustrated in the code below.
class LLMModel(mlflow.pyfunc.PythonModel):
def load_context(self, context):
root_path = os.environ.get("LOCAL_ROOT_FOLDER","/")
model_path = "llm-models"
#Read parent run-id from model context as registered
with open(context.artifacts["model_context"], "r") as f:
cfg = json.load(f)
self.mlflow_run_id = cfg["run_id"]
#Discover Local Model Path
self.absolute_model_path = os.path.join(root_path,model_path,self.mlflow_run_id)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Load from the Model Path
model = AutoModelForCausalLM.from_pretrained(self.absolute_model_path,
torch_dtype=torch.float16,
device_map=device)
tokenizer = AutoTokenizer.from_pretrained(self.absolute_model_path)
self.text_generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
def predict(self, context, model_input, params=None):
prompt = model_input["prompt"]
#Predict
output = self.text_generator(prompt, max_length=50, do_sample=True)
return {'text_from_llm': output}Now that the model is tested and the “data scientist” is satisfied, they rerun the notebook with the environment variable ONLY_LOCAL_TESTING=False.
This publishes the model binaries to MLflow under the parent run ID, enabling Domino to function as a system of record.
The next step illustrates the core idea: a user in the “prod-deployer” role uses an IRSA (see AWS S3 bucket policy and trust policies here) based workspace (we assume AWS-based deployments, but the same applies to Azure or GCP using workload identity) to download the model binaries directly from the MLflow artifacts of the specified parent run ID. These binaries are then written to the dataset path:
/mnt/imported/data/domino-models-prod/llm-models/{parent-run-id} That is all you need. The user in the “prod-deployer” role then restarts the model endpoint originally started by the “data scientist.” This restart action switches the /llm-models mount from the domino-models-dev dataset to the domino-models-prod dataset. The Domsed mutation decides which dataset to mount based on the role of the user starting the model endpoint.
The entire process is illustrated by the notebook deploy_llm_to_prod.ipynb. The diagram below illustrates the process:

This process enables us to run LLMs as model endpoints in Domino from a shared dataset while still ensuring Domino behaves like a system of record.
Check out the GitHub repo


Sameer Wadkar
Principal solution architect

I work closely with enterprise customers to deeply understand their environments and enable successful adoption of the Domino platform. I've designed and delivered solutions that address real-world challenges, with several becoming part of the core product. My focus is on scalable infrastructure for LLM inference, distributed training, and secure cloud-to-edge deployments, bridging advanced machine learning with operational needs.