
Managing data science projects
A recent study from MIT concluded that while most enterprises expect artificial intelligence (AI) to be provided a competitive advantage, few of them have been able to incorporate it into anything they do. Only 20 percent of enterprises have any real AI work happening, and just a fraction of those have it deployed extensively.
Enterprises recognize the need for data science, but they don’t see the path to get there. Many have incorrect assumptions about what data science is and limited understanding how to support it. Some think that because data scientists work in code (usually R or Python), the same methodology that works for building software will work for building models. However, models are different, and the wrong approach leads to trouble.
The key to succeeding with data science is understanding that software engineering processes don’t work for data science. Data science requires its own lifecycle and methodology: A defined process for choosing projects, managing them through deployment, and maintaining models post-deployment.
Data science project lifecycle and methodology
This guide synthesizes the successful project practices from dozens of leading data science organizations spanning many sizes and industries. Its goal is to provide data science leaders with actionable insights for their own organizations.
The approach can be summarized as: Imagine your ideal process for a single data science project, then consider how to manage a portfolio of those projects, and then think about the types of people, tools and organization structure you need to best achieve your goals.
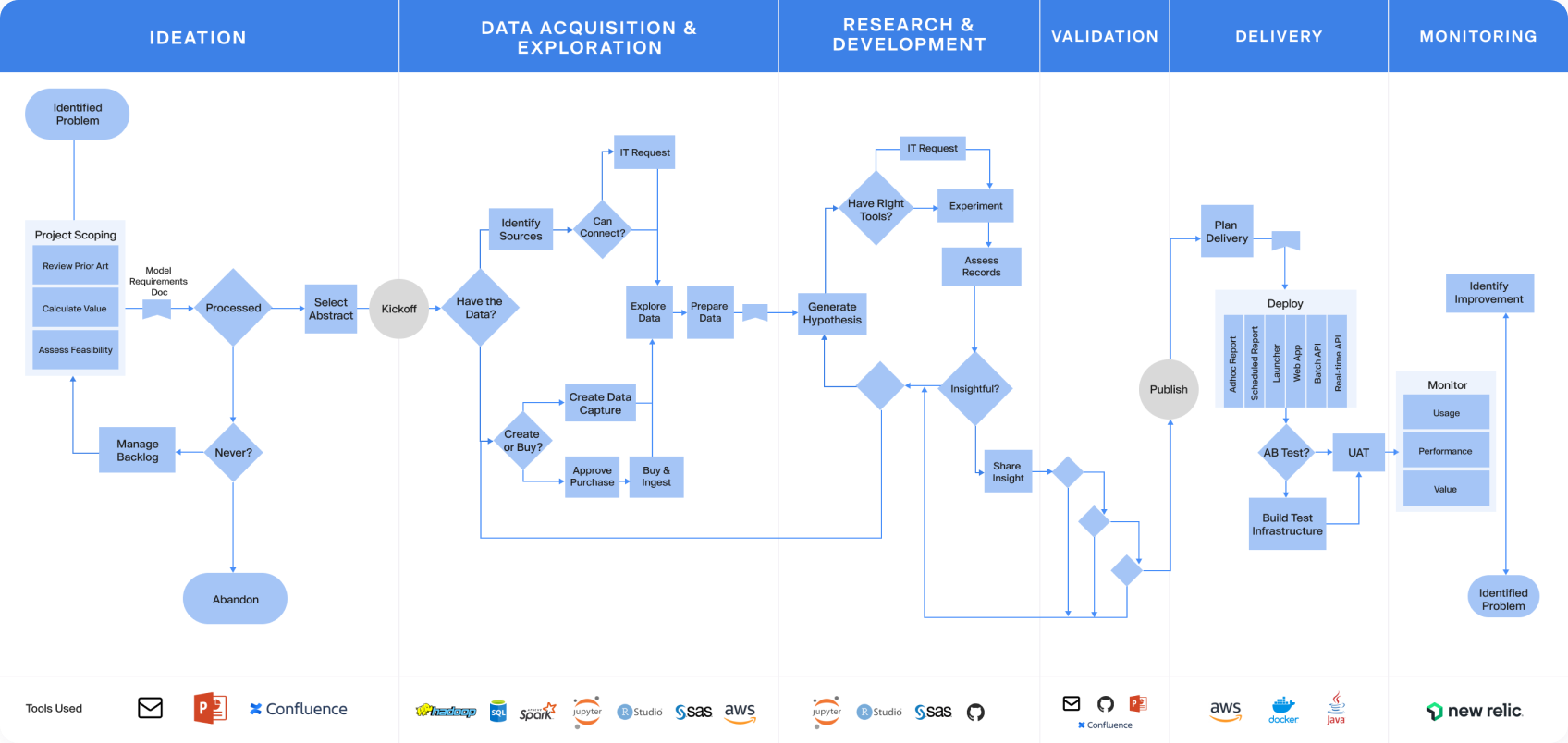
(Click to enlarge. Find the full lifecycle map inside our Practical Guide to Managing Data Science at Scale.)
What follows is inspired by CRISP-DM and other frameworks, but based more on practical realities we’ve seen with leading data science organizations, like Allstate, Monsanto, and Moody’s. We step through the key stages that we’ve seen consistently emerge across many organizations’ data science lifecycle: ideation, artifact selection, data acquisition and exploration, research and development, validation, delivery, and monitoring. However, the methodology and best practices here are broader than the process to manage a single project.
Overall lifecycle principles
Before jumping into the specifics of each project stage, below are a few guiding principles.
Expect and embrace iteration. The flow of a project is highly iterative, but, by and large, nearly all projects pass through these stages at one point or another. It is normal for a project to get to validation and then need to go back to data acquisition. It is also normal for a single project to open 10 additional avenues of future exploration. What separates leading organizations is their ability to prevent iterations from meaningfully delaying projects, or distracting them from the goal at hand. One leading organization includes an “areas for future exploration” in all project deliverables and has educated business stakeholders in “lunch-and-learns” to expect many loops through the process.
Enable compounding collaboration. High-performing data science teams realize they work best when they stand on the shoulders of those before them and work in synch with other aspects of the business. One data science leader even goes so far as to track component reuse as a KPI. Data scientists who create widely used components (e.g. a great dataset diagnostic tool) are given visibility and credit for their contributions to the community’s success. A data science project is only as strong as its weakest link, so ensure each team in a project is well represented and accounted for. Below is a diagram of each respective player in a large scale project and their role within the project.

Anticipate auditability needs. As more and more critical processes incorporate data science results, it is essential to be able to audit and inspect the rationale behind the model. The financial industry is formally regulated under “model risk management.” Yet other industries are also taking proactive steps to build model risk expertise and preserve all relevant artifacts associated with the development and deployment of a model. More recently, there is speculation that technology firms could follow suit to preserve model integrity.
Stage 1: Ideation
Some of the most important work in the overall lifecycle happens before a line of code is written. If done well, the ideation stage dramatically de-risks a project by driving alignment across stakeholders. This is where the business objective is identified, success criteria laid out, prior art is reviewed, and initial ROI calculations are performed. Ideation is when feasibility is assessed, both in terms of “Does the data even exist?” and “Can we realistically change how the business process works?” It is also where prioritization happens relative to other potential projects. Below are some best practices observed that get to the root of many of the problems discussed earlier.
Problem first, not data first
Many organizations start with the data and look for something “interesting” rather than building a deep understanding of the existing business process and then pinpointing the decision point that can be augmented or automated. The genesis of a project need not only come from the business, but it should be tailored to a specific business problem.
Map existing processes
Leading organizations map existing business processes in tools like Vizio, PPT, or LucidChart and then circle on that map the exact points that data science could drive business impact. Doing so ensures they aren’t missing the opportunity to target more impactful parts of the process. It also ensures they’re speaking the language of their stakeholders throughout the lifecycle to minimize change management down the road.
Practice and master order of magnitude ROI math
The ability to estimate the potential business impact of a change in a statistical measure is one of the best predictors of success for a data science team. However, despite much mathematical prowess, data science teams often shy away from back-of-the-envelope calculations. The point is not precision to hit some CFO-mandated internal hurdle rate, but rather to aid in the prioritization process. For example, a large insurer asked, “If we reduce fraudulent insurance claims by 1%, how much would we save?” They then asked, “What is a conservative estimate of how much improvement we can expect by the data scientist’s efforts?”
At the same time, they considered all of the project costs: time spent by the data science team, potential data acquisition costs (e.g., either from a vendor or internal instrumentation costs), computing resources, implementation time for IT, and training/adjustment time for stakeholders. Finally, they settled on a rough number based on past experiences but erring on the conservative side. The table below captures two useful dimensions for this exercise.
Maintain a hub of past work with business domain and technical experts
As teams grow, no one person can be an expert in everything. It’s critical to have a way to search to see who is most familiar with the latest version of TensorFlow or who has done the most work in the marketing attribution space. Even better than search is the ability to reproduce this work (e.g., data, packages, code, results, discussions) which will give a substantial head start in subsequent steps. In one large tech organization, this hub also provides information into downstream consumption of work product to help assess quality. For example, a project that feeds an internal application with thousands of internal users is likely more trustworthy than a prototype that hasn’t been used in months.
Create and enforce templates for model requirements documents
Documentation is often viewed as a chore, but high-performing organizations find that documentation upfront saves heartache down the road. Create a template for 80% of cases, knowing there will always be exceptions. Keep track of who is using the templates to see if it leads to productivity lift over time.
Ideally, bake this into your actual infrastructure rather than in disparate systems which often fall out of sync (“the curse of Sharepoint”). Key components of a good Market Requirements Document (MRD) include: problem statement and objective, target KPIs, estimated ROI, target data sources, known risks, relevant stakeholders, prior art (with links), and a stakeholder-centric timeline.
Maintain a stakeholder-driven backlog
Your stakeholders should always be able to see what’s in flight and what’s been put in the backlog. Like any product org, they don’t necessarily get to change it. Yet, you should have recurring check-ins with stakeholders to ensure priorities or constraints haven’t shifted.
Create multiple mock-ups of different deliverable types
A leading e-commerce company creates 3-5 mocks for every data science project they take on, even bringing in a designer to make it feel real. For example, they discovered exposing their model as a HipChat bot was the most user-friendly way to leverage the model. By iterating on design possibilities before they get data, they ensure they’ve surfaced any previously undiscovered requirements and maximize their odds of adoption.
Bring IT and engineering stakeholders in early
A model may work spectacularly in the lab, but not have any hope of ever working in production the way envisioned by the business. IT and engineering stakeholders need a seat at the table this early in order to identify constraints like, “We only backfill that data monthly from the vendor, so we can’t do a real-time scoring engine.”
Consider creating synthetic data with baseline models
Some organizations even create synthetic data and naive baseline models to show how the model would impact existing business processes. A leading agriculture company devotes an entire team to creating synthetic “perfect” data (e.g., no nulls, full history, realistic distribution) to establish potential value with the business before they go contract with expensive satellite data providers to get “real” data.
Stage 2: Data Acquisition and Prep
Data is rarely collected with future modeling projects in mind. Understanding what data is available, where it’s located, and the trade-offs between ease of availability and cost of acquisition, can impact the overall design of solutions. Teams often need to loop back to artifact selection if they discover a new wrinkle in data availability.
Extracting the most analytical value from the available data elements is an iterative process and usually proceeds in tandem with data understanding. Below are some best practices we’ve seen streamline an often painful process.
Check stakeholder intuition
Stakeholders often have solid intuition about what features matter and in what direction. Many high-performing teams extract this intuition to help point them to relevant data and jump start the feature engineering process.
Datasets as a reusable component
Given the time spent acquiring and cleaning data, it’s critical that output becomes reusable by others. Many organizations create analytical or modeling datasets as key entities which are shared, meaning that they only need to interpolate nulls and exclude outliers once. Some organizations are starting to move towards feature stores to ensure people can build on past work. Regardless of the title, the work of creating these datasets should be interrogable and auditable for future research and also streamlines eventual production pipelines.
Track downstream consumption of data
Many organizations spend significant funds to acquire external data or devote internal resources to collect data without knowing if it’s useful. A leading credit ratings agency tracks how many projects and business-facing apps utilize each external dataset to help guide their data investment decisions.
Develop a “play” for evaluating and incorporating external data
Increasingly teams are turning to alternative datasets to better understand their customers, whether it be social data, location data, or many other types. Organizations that have streamlined the process of vendor selection, data evaluation, procurement, and ingestion eliminate a key bottleneck. This often requires coordination with procurement, legal, IT, and the business to agree on a process. One hedge fund has reduced its evaluation/ ingestion time from months to weeks, helping maintain its edge in a highly competitive space.
Stage 3: Research and Development
This is the perceived heart of the data science process and there are numerous guides on technical best practices. Below are a number of best practices that address many of the key reasons data science organizations struggle.
Build simple models first
Resist the temptation to use 500 features. One company spent weeks engineering the features and tuning the hyperparameters. Then they learned that many of them were either a) not collected in real time so couldn’t be used in the target use case or b) not allowed for compliance reasons. They ended up using a simple five features model and then worked with their IT team to capture other data in real time for the next iteration.
Set a cadence for delivering insights
As discussed earlier, one of the most common failure modes is when data science teams deliver results that are either too late or don’t fit into how the business works today. Share insights early and often. For example, one leading tech company has their data scientists share an insight every 3-4 days. If they can’t publish a short post on incremental findings in business-friendly language, then chances are they are down a rabbit hole. The insight can be as simple as “this experimental path didn’t pan out.” This lets the manager coach more junior team members, plus gives an easily consumable medium for business stakeholders to offer feedback, spark new ideas, and gauge progress.
Ensure business KPIs are tracked consistently over time
Too often, data science teams lose sight of the business KPI they are trying to affect and instead focus on a narrow statistical measure. Leading teams ensure that the relevant KPI is never far from their experimental flows. One hedge fund tracks the overall performance of its simulated investment portfolio across hundreds of experiments and then shows this to its Investment Committee as proof of data science progress.
Establish standard hardware & software configurations, but balance the flexibility to experiment
Data scientists can often spend the first eight weeks on the job configuring their workstations, rather than exploring existing work and understanding their stakeholder’s priorities. Having a few standard environments gets people onboarded faster. Yet, it’s important they retain flexibility to try new tools and techniques given the breakneck pace of innovation. Cloud computing resources and container technology are well-suited to address these demands without compromising on governance.
Stage 4: Validation
Validation is more than just code review. Rigorous evaluation of the data assumptions, code base, model performance, and prediction results provide confidence that we can reliably improve business performance through data science. Validating results and engaging with stakeholders are equally important in this phase. Ultimately receiving sign-off from stakeholders is the goal: the business, any separate model validation team, IT, and, increasingly, legal or compliance.
Ensure reproducibility and clear lineage of project
Quality validation entails dissecting a model and checking assumptions and sensitivities from the initial sampling all the way to the hyper-parameters and front-end implementation. This is nearly impossible if a validator spends 90% of their time just gathering documentation and trying to recreate environments. Leading organizations capture the full experimental record, not just the code. One large enterprise customer captured this well in the following diagram
Use automated validation checks to support human inspection
While data science’s non-deterministic nature means that unit testing does not directly apply, there are often repeated steps in a validation process that can be automated. That may be a set of summary statistics and charts, a portfolio backtest, or any other step that could turned into an automated diagnostic. This lets human validators focus on the critical gray areas.
Maintain record of discussion in context
The model development process often requires subjective choices about data cleansing, feature generation, and many other steps. For example, when building a home price forecasting model, the feature “proximity to a liquor store” could increase predictive power. However, it may necessitate significant debate amongst multiple stakeholders about how to calculate it and if it was permitted from a compliance perspective. Leading organizations have set up their infrastructure and process to capture these comments and discussions and preserve them in context rather than scattered across countless email chains.
Preserve null results
Even if a project yields no material uplift and doesn’t get deployed into production, it’s critical to document it and preserve it in the central knowledge library. Too often, we hear that data scientists are re-doing work someone explored without knowledge of previous inquiries.
Stage 5: Delivery
The delivery path taken depends on the initial artifact type determined. This is when a mathematical result becomes a “product.” Deploying into production can be as simple as publishing the results as reports or dashboards, incorporating the modeling pipeline into batch processes (e.g., new direct marketing campaigns), or deploying models into production systems for automated decision making (e.g., online credit decisions or product recommendations).
Preserve links between deliverable artifacts
While real-time scoring gets all the glory, the vast majority of models will at one time or another be reports, prototype apps, dashboards, or batch scoring engines. It’s important to keep a link between all those deliverables because it saves time and avoids risk that key feedback is lost if something goes awry.
Enforce a promote-to-production workflow
As a result of incentive structure and responsibility alignment, data science teams often stumble in the last mile. If you establish the workflow ahead of time, you reduce the bottlenecks for delivery without adding operational risk. For example, pre-determine which packages and tools are permitted in critical path production workflows and ensure consistency of results relative to a dev environment result. Determine if and how much human inspection of early results is necessary in staging as automated testing may not be sufficient.
Flag upstream and downstream dependencies
A model is at its most risky when it finally makes it to production. Ensure that you know the upstream dependencies: what training data was used, what transformations were done with what tools, what modeling packages were used, etc. Also make sure you know the downstream dependencies (e.g., this nightly batch model is stacked on another model).
Anticipate risk and change management burdens
High-performing teams anticipate the human component and proactively address it with training. One leading insurer has a dedicated role that helps train business units on how a model works, why they did it, and acts as a single point of feedback for future iterations on the model. This has dramatically increased adoption across non-technical stakeholders like claims adjusters.
Stage 6: Monitoring
Models are at their most impactful when they are actually “live” and affecting people’s behavior, whether internal workflows or customer engagement. Given the non-deterministic nature of data science “success”, it’s critical to have a rich monitoring suite that takes into account the semantic and statistical measures in addition to traditional system measures covered by application performance management (APM) tools like New Relic.
Consider control groups in production
While it is hard to convince business stakeholders that the fantastic model you’ve just completed shouldn’t be applied universally, it’s often critical for long-term success. One leading organization established a global holdout group from all of their customer segmentation and price elasticity models. After a year, they compared the average revenue from the holdout group to the customers whose experiences were guided by the predictive models. The overall lift was more than $1 billion, which gave them the credibility to dramatically expand the team and push models into more steps of the customer journey.
Require monitoring plans for proactive alerting, acceptable uses, and notification thresholds
The data scientist who created the model is the person best positioned to know what risks are inherent from their approach. Rather than wait for the business to notice something is wrong or a metric to drift, codify that knowledge into your monitoring system. Do you expect certain input types and ranges? If it’s outside of those, what should you do? Rollback? Stop serving predictions? What if someone in a totally different department starts consuming the model in a way that may be risky or outright wrong? Working collaboratively with IT or engineering, data scientists can put the appropriate guardrails on their creations.
Integrate monitoring with tools where people spend most of their time (e.g., email, Slack)
High performing teams realize that monitoring is only good if someone acknowledges, inspects, and changes behavior if necessary. We’ve seen organizations build alerts into chatbots or email systems to ensure they can keep up with the alerts as their number of production models scales.
Best practices for data science project lifecycles
Now that we have the model and methodology for data science projects, the following video highlights the best practices for managing the project lifecycle.
Creating a data science flywheel
Watch this panel discussion to learn how to create a data science “flywheel” and dramatically accelerate the pace of innovation.

Pre-flight Project Checklist
This pre-flight project checklist walks through an ideal set of upfront actions that data science leaders can take to maximize the probability of success for their data science projects.
Business case:
- What’s the desired outcome of the project, in terms of a business metric?
- What are the linkages from your project to impacting that ultimate business metric?
- What is the order-of-magnitude ROI and cost? State assumptions. Use back-of-envelope math.
Delivery:
- Who will consume this and what form factor will the final product take (report, app, API)?
- What dependencies or resources will you require to deliver work this way (e.g., IT)?
- What are other possible delivery mechanisms, especially ones that are lighter weight or easier to test first?
- What user training is necessary to ensure adoption?
Success measures:
- How will you know if it’s working as expected, or otherwise get feedback? What’s your “monitoring” plan, even if it’s manual and subjective?
Other questions to consider in real use:
Roles and responsibilities:
Indicate what roles will be involved, who, and if their sign-off is required before delivery:
- Lead data scientist
- Validator
- Data engineer
- Product manager
- Application developers
- Internal end users
- External end users (customers)
- DevOps engineer
- Legal / compliance
Technology:
- What compute hardware and software infrastructure do you anticipate being necessary?
- Would your project benefit from specialized or parallelized computing?
Data:
- What relevant data exists today? Who are the subject matter experts?
- What other data would we potentially want to capture, create, or buy externally?
Prior art:
- Who has worked on this business topic before (internal and external)?
- Who are the relevant experts in the techniques I will likely use?
Risk mitigation:
- How could this model be misused by end users?
- Any constraints on modeling approach (e.g., interpretability requirements)?
Next steps
Organizations that excel at data science are those that understand it as a unique endeavor, requiring a new approach. Successful data science leaders follow a project lifecycle for selecting projects, building and deploying models, and monitoring them to ensure they’re delivering value. Check out our weekly demo to learn more.