Everything you need to know about feature stores




Features are input for machine learning models. The most efficient way to use them across an organization is in a feature store that automates the data transformations, stores them and makes them available for training and inference.
ML projects and applications are often expensive and difficult to scale due to various feature-specific challenges. Often, features are not reused across teams and different ML applications in an organization, and some teams may define and use features differently. Additional effort is needed to provide each ML model with the required features. Feature stores rectify these issues by improving consistency of definition and increasing efficiency for data science teams. Feature stores allow teams to reuse features across data science projects and ML models effectively, increasing the efficiency and scalability of their MLOps process.
In this article, you’ll learn about feature stores and how to effectively use a feature store in the development of ML models.
What Is a Feature?
In machine learning, a predictive model learns to make predictions based on past examples. A “feature” is an attribute that is used to describe each example.
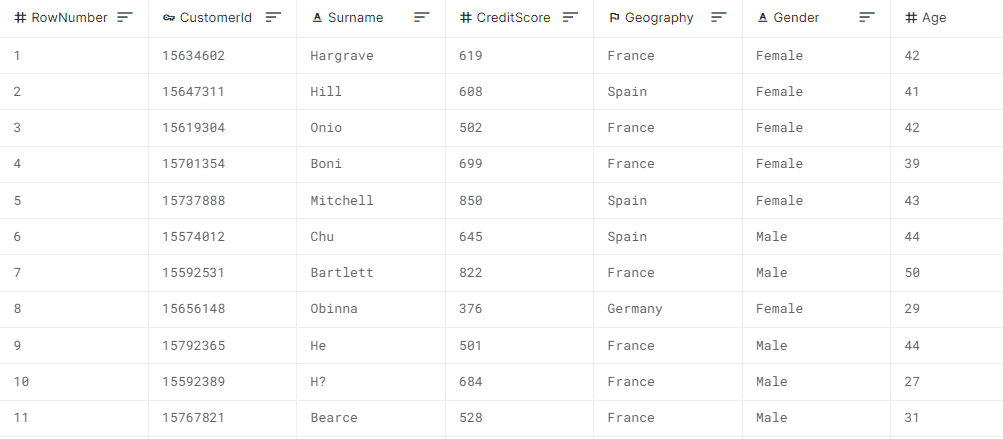
Each row in the table is a data instance that can be used for training or inference. The columns represent individual features, and each cell is a feature value.
The features that are used as training data for ML models are created during a process called feature engineering. In this process, a data scientist applies transformations to raw data in order to create features that can be consumed by an ML model.
What Is a Feature Store?
An feature store is a central store that manages features specifically prepared for the data science process. By making it easy to search and find features, they can easily be reused across projects, improving efficiency, governance and model velocity.
Most ML or deep learning (DL) models require hundreds to thousands of features that may be processed differently depending on the data type. However, managing a large number of features is not straightforward, and the same set of features may apply to different ML use cases.
For instance, a credit institute uses two different ML models: Model A and Model B. Model A uses the feature `customer_occupation` to predict the credit score of a particular customer. At the same time, a different model, Model B, uses the same feature to predict the probability that this customer will upgrade to a certain product when approached by the credit institute. When the same type of features is used for several applications, it makes sense to reuse features across these models.
Feature Store Components
A modern feature store consists of three main components—transformation, storage, and serving:
Source: Artem Oppermann
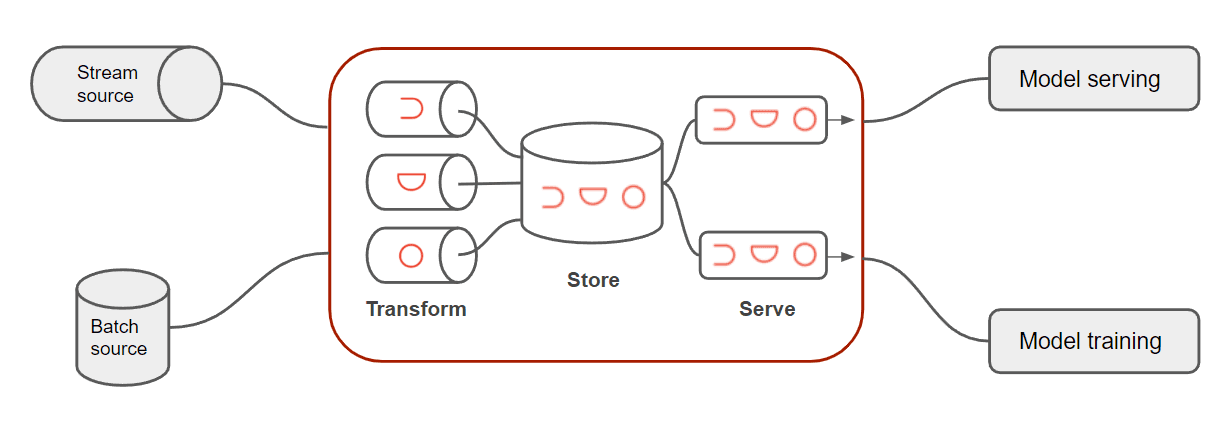
Transformations
ML models usually require transformations of raw data into features that the ML model can consume. For instance, ML/DL models do not handle features well that are represented as categories or labels (e.g. gender or color). Therefore, you need to transform this categorical data into a more suitable format. Other common transformations include standardization of data and calculated values. Feature stores orchestrate these feature transformations, and there are mainly two types:
- Batch transformations are applied only to data at rest and can be found in a database, data warehouse, or data lake. A typical example of this kind of data is historical customer data that can be found in a table (*ie* customer_occupation, customer_age, country, etc.).
- Streaming transformations are applied to data in motion or streaming sources. This means that the data is transformed online as it moves through the feature store pipeline. This kind of data is more recent as compared to data in a database or data warehouse. For example, data that must have streaming transformations applied would include the number of clicks on a landing page per user in the last thirty minutes or the number of views per listing in the past hour per user.
Storage
At a high level, a feature store is a warehouse of feature data used by ML operations. A feature store differs architecturally from a traditional data warehouse in the sense that it consists of a two-part database:
- An “offline database” is primarily intended for batch predictions and model training. The database stores large amounts of historical features for training purposes of ML models.
- The second database, called the “online database”, serves online features at low latency to trained models that are already in production. This online database satisfies the need to provide the most up-to-date features to the predictive models.
Serving
The transformed data that has been stored in the feature store can now be retrieved and provided to ML/DL models for training or once they are in production. This process is referred to as “serving”. This step is essential because it ensures that the correct feature data is constantly used.
For model training, offline data from the offline database is retrieved and used. For serving features to a model in production, the data is served from the online database through a high-performance and low-latency API.
Benefits of a Feature Store
Developing machine learning models is not easy, primarily because an AI system is very complex and requires significant manual effort. Data engineering and management for ML are some of the most time-consuming tasks in data science projects. Data engineers have to prepare a variety of data sources and associated metadata for the data science team. The data science team then determines what may be useful in a ML project and develops features to test.
Aside from losing valuable time in data preparation, ML projects and applications are expensive and difficult to scale. Aside from losing valuable time in data preparation, ML projects and applications are expensive and difficult to scale. Non standard feature creation is time consuming, can cause repetitive, inconsistent work across teams, and can make models unable to go into production because the data used to train the model can't be recreated in production.
To illustrate this complexity, the diagram below depicts the ML infrastructure. It shows that the features are non-standard and, therefore, not very scalable:
Source: Artem Oppermann
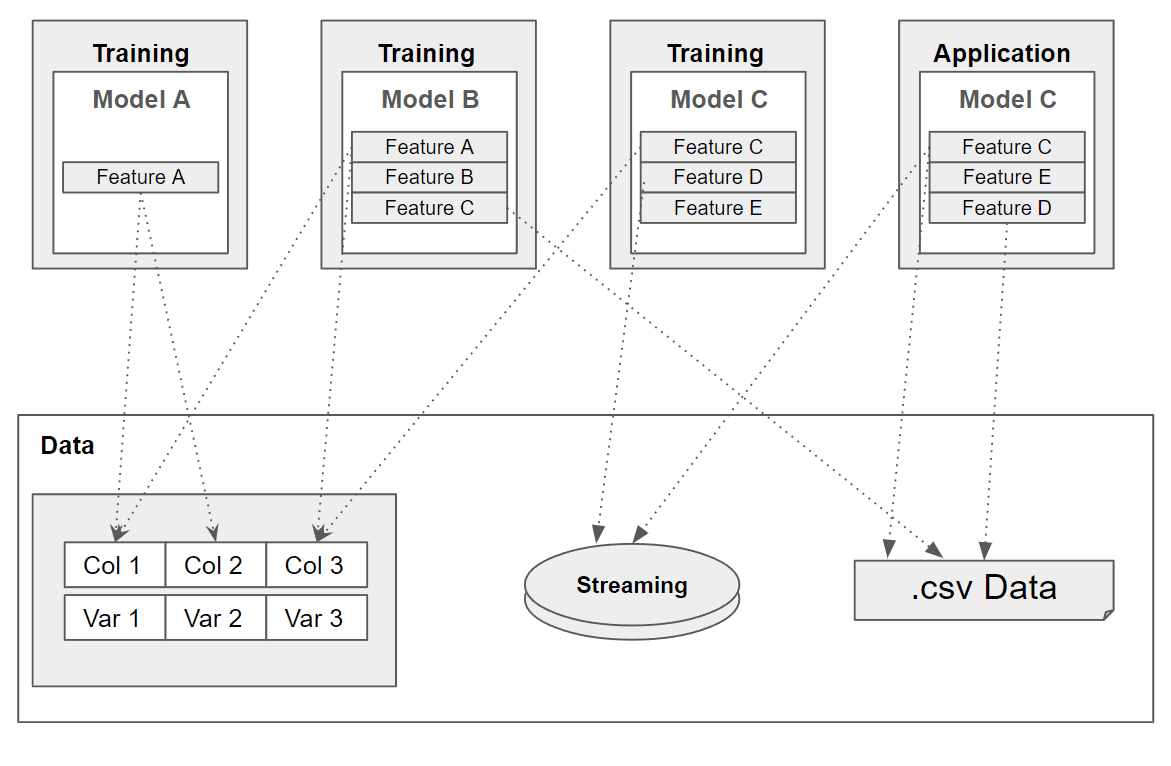
The different models access the same data sources so that individual data preparation happens for each use case. This means that a great deal of effort goes into preparing the data and codes are duplicated, which introduces an enormous potential for errors. It also has the potential to make it impossible to recreate the features in production efficiently.
Below is a brief summary of the problems and challenges when using an unstandardized ML infrastructure:
- Redundant feature building
- Features are not reusable
- Duplicate codes
- Features may not be available in production
- Resource intensive data preparation
A data science team can avoid these challenges by using a feature store. By securing the features in the store, features can be easily reused by different models reducing model development time and increasing reproducibility of model development.
Feature stores serve as a central hub for ML, which can improve the efficiency of the ML team by avoiding a data pipeline jungle. Without feature stores, various models may have essentially the same or similar data pipeline to prepare, create and access required features. In contrast, a feature store provides a standardized data pipeline for all models.
A high degree of ML automation can be achieved by using a feature store. Specifically, automated data validation rules to verify data integrity. This can involve checking whether values are within a valid range, have a correct format and data type, and are not null.
Feature stores can also increase the velocity of model deployment, by ensuring features are consistently available for inference. By using a centralized data store for training data, a data science team can achieve optimal scalability and increase ML applications’ efficiency.
The following graphic shows how a feature store can structure the features, independent of the models:
Source: Artem Oppermann
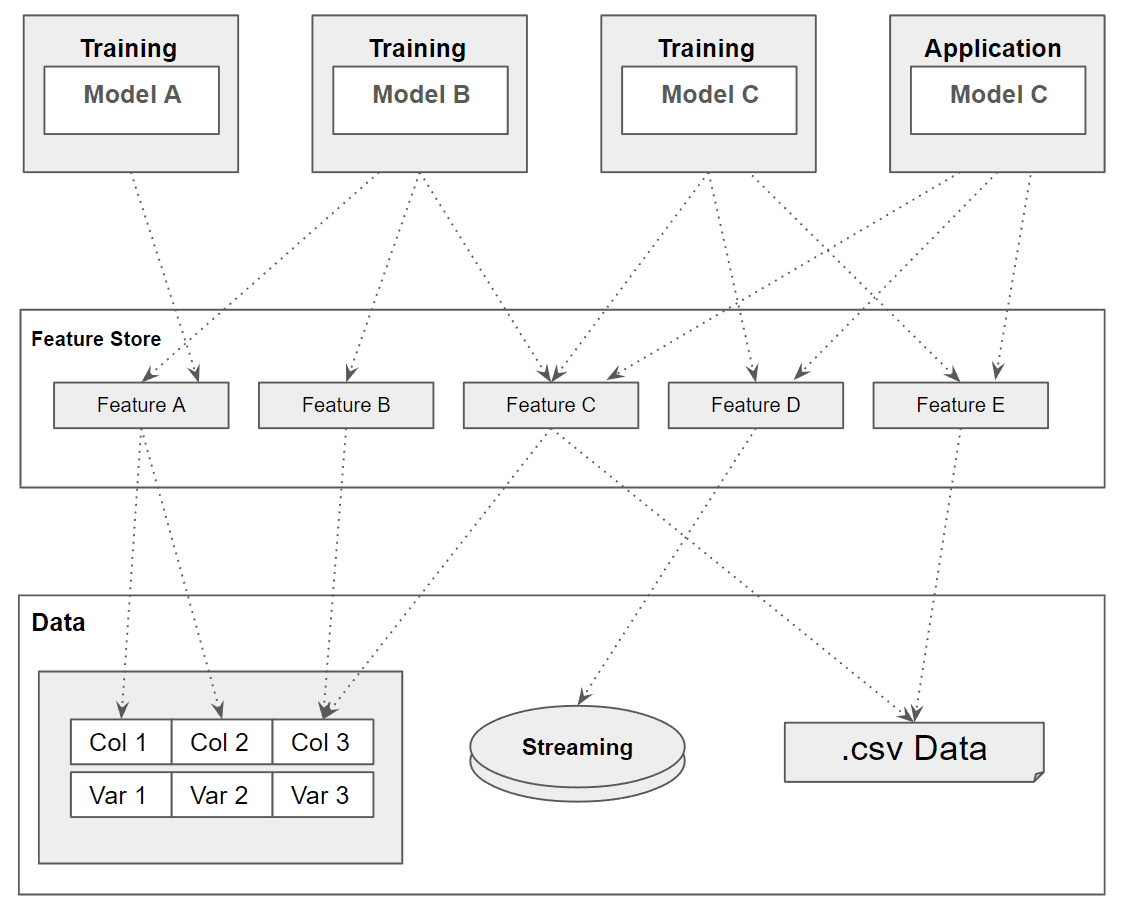
To summarize, a feature store brings many benefits to a data science team, including the following:
- Reusability of features
- Reproducibility
- Quality assurance of features
- Efficient use of data scientists (*ie* time is significantly reduced)
- High degree of ML automation
- Emergence of a central hub for ML
- Scalability of data science, wherein new projects and models can be scaled and implemented faster because data, infrastructure, and standardized processes are already in place
Feature Store Options
Until recently, if you wanted to incorporate a feature store in your ML operation, you had to develop your own. Feature stores were mainly used in in-house ML platforms, like Uber’s Michelangelo. Thanks to the open source community, this has changed.
Even though the options of open source feature stores are still limited, options are increasing with products such as Feast and Hopsworks.
The Hopsworks Feature Store was first released at the end of 2018 and is a component of the larger Hopsworks Data Science Platform. Feast is a standalone feature store, released by GoJek, and is built around Google Cloud services, like BigQuery, Redis, and Cloud Bigtable, and uses Apache Beam for feature engineering.
Conclusion
In this article, you learned about how feature stores can increase efficiency through the automation they bring into an ML operation. Feature stores are central data stores specifically for ML processes that have become a critical component of the modern ML stack.
By centralizing ML features, new projects and models can be scaled and implemented faster and more reliably because the data, infrastructure, and standardized data processes are already available.