Feature Engineering
What is feature engineering?
Feature engineering, in data science, refers to manipulation — addition, deletion, combination, mutation — of your data set to improve machine learning model training, leading to better performance and greater accuracy. Effective feature engineering is based on sound knowledge of the business problem and the available data sources.
Creating new features gives you a deeper understanding of your data and results in more valuable insights. When done correctly, feature engineering is one of the most valuable techniques of data science, but it is also one of the most challenging. A common example of feature engineering is when your doctor uses your body mass index (BMI). BMI is calculated from both body weight and height, and serves as a surrogate for a characteristic that is very hard to accurately measure: the proportion of lean body mass.
Feature engineering in the ML lifecycle
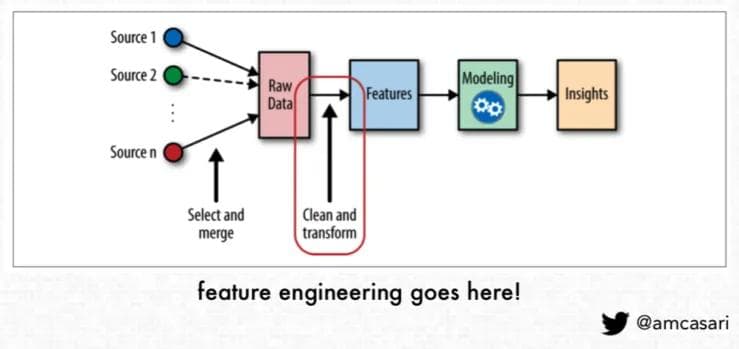
Feature engineering involves transforming raw data into a format that enhances the performance of machine learning models. The key steps in feature engineering include:
- Data Exploration and Understanding: Explore and understand the dataset, including the types of features and their distributions. Understanding the shape of the data is key.
- Handling Missing Data: Address missing values through imputation or removal of instances or features with missing data. There are many algorithmic approaches to handling missing data.
- Variable Encoding: Convert categorical variables into a numerical format suitable for machine learning algorithms using methods.
- Feature Scaling: Standardize or normalize numerical features to ensure they are on a similar scale, improving model performance.
- Feature Creation: Generate new features by combining existing ones to capture relationships between variables.
- Handling Outliers: Identify and address outliers in the data through techniques like trimming or transforming the data.
- Normalization: Normalize features to bring them to a common scale, important for algorithms sensitive to feature magnitudes.
- Binning or Discretization: Convert continuous features into discrete bins to capture specific patterns in certain ranges.
- Text Data Processing: If dealing with text data, perform tasks such as tokenization, stemming, and removing stop words.
- Time Series Features: Extract relevant timebased features such as lag features or rolling statistics for time series data.
- Vector features are commonly used for training in machine learning. In machine learning, data is represented in the form of features, and these features are often organized into vectors. A vector is a mathematical object that has both magnitude and direction and can be represented as an array of numbers.
Feature engineering is often an iterative process; evaluate, refine, and repeat as needed to achieve optimal results. These steps may vary based on the nature of the data and the machine learning task, but collectively, they contribute to creating a robust and effective feature set for model training.
Common feature types:
- Numerical: Values with numeric types (int, float, etc.). Examples: age, salary, height.
- Categorical Features: Features that can take one of a limited number of values. Examples: gender (male, female, non-binary), color (red, blue, green).
- Ordinal Features: Categorical features that have a clear ordering. Examples: T-shirt size (S, M, L, XL).
- Binary Features: A special case of categorical features with only two categories. Examples: is_smoker (yes, no), has_subscription (true, false).
- Text Features: Features that contain textual data. Textual data typically requires special preprocessing steps (like tokenization) to transform it into a format suitable for machine learning models.
Feature normalization
Since data features can be measured on different scales, it's often necessary to standardize or normalize them, especially when using algorithms that are sensitive to the magnitude and scale of variables (like gradient descent-based algorithms, k-means clustering, or support vector machines).
Normalization standardizes the range of independent variables or features of the data. This process can make certain algorithms converge faster and lead to better model performance, especially for algorithms sensitive to the scale of input features.
Feature normalization helps in the following ways:
- Scale Sensitivity: Features on larger scales can disproportionately influence the outcome.
- Better Performance: Normalization can lead to better performance in many machine learning models by ensuring that each feature contributes approximately proportionate to the final decision. This is especially meaningful for optimization algorithms, as they can achieve convergence more quickly with normalized features.
Some features, however, may need to have a larger influence on the outcome. In addition, normalization may result in some loss of useful information. Therefore, be judicious when applying normalization during the feature extraction process.