Dask
What is Dask?
Dask was released in 2018 to create a powerful parallel computing framework that is extremely usable to Python users, and can run well on a single laptop or a cluster. Dask is lighter weight and easier to integrate into existing code and hardware than Apache Spark.
Dask is a flexible library for parallel computing in Python. Dask is composed of two parts:
- Dynamic task scheduling optimized for computation and interactive computational workloads. The central dask-scheduler process coordinates the actions of several dask-worker processes spread across multiple machines and the concurrent requests of several clients.
- Big Data collections like parallel arrays, dataframes, and lists that extend common interfaces like NumPy, Pandas, or Python iterators to distributed environments. These parallel collections run on top of dynamic task schedulers.
Internally, Dask encodes algorithms in a simple format involving Python dicts, tuples, and functions. This graph format can be used in isolation from the Dask collections. Working directly with task graphs is rare, unless you intend to develop new modules with Dask.
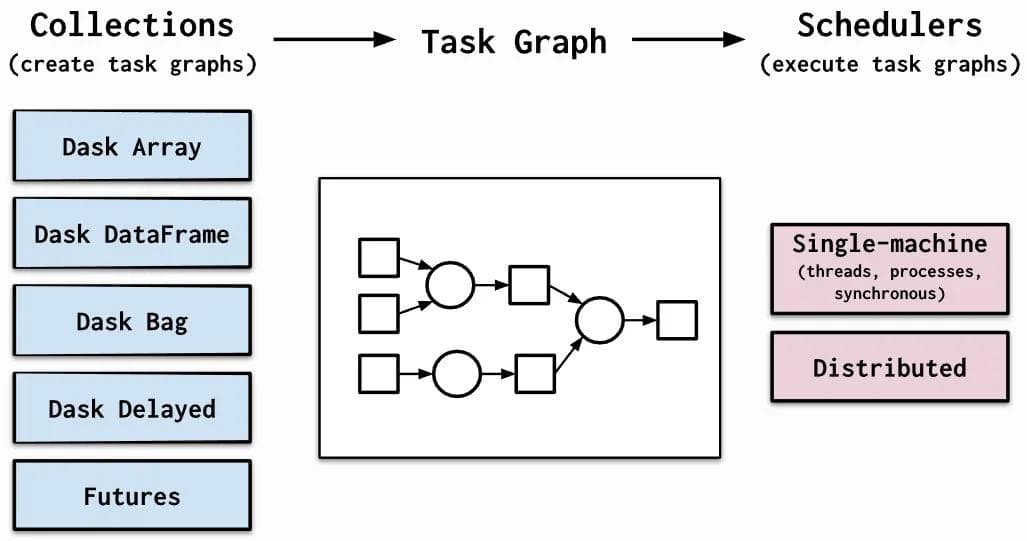
Source: Dask Documentation
Since Dask supports Pandas dataframes and NumPy array data structures, data scientists can continue using the tools they know and love. Dask also integrates tightly with Scikit-learn’s JobLib parallel computing library that enables parallel processing of Scikit-learn code with minimal code changes.