dplyr
What is dplyr?
Dplyr (pronounced “dee-ply-er”) is the preeminent tool for data wrangling in R. Learning and using dplyr helps data scientists make the data preparation and management process faster and easier to understand. Data scientists typically use dplyr to transform existing datasets into a format better suited for some particular type of analysis or data visualization.
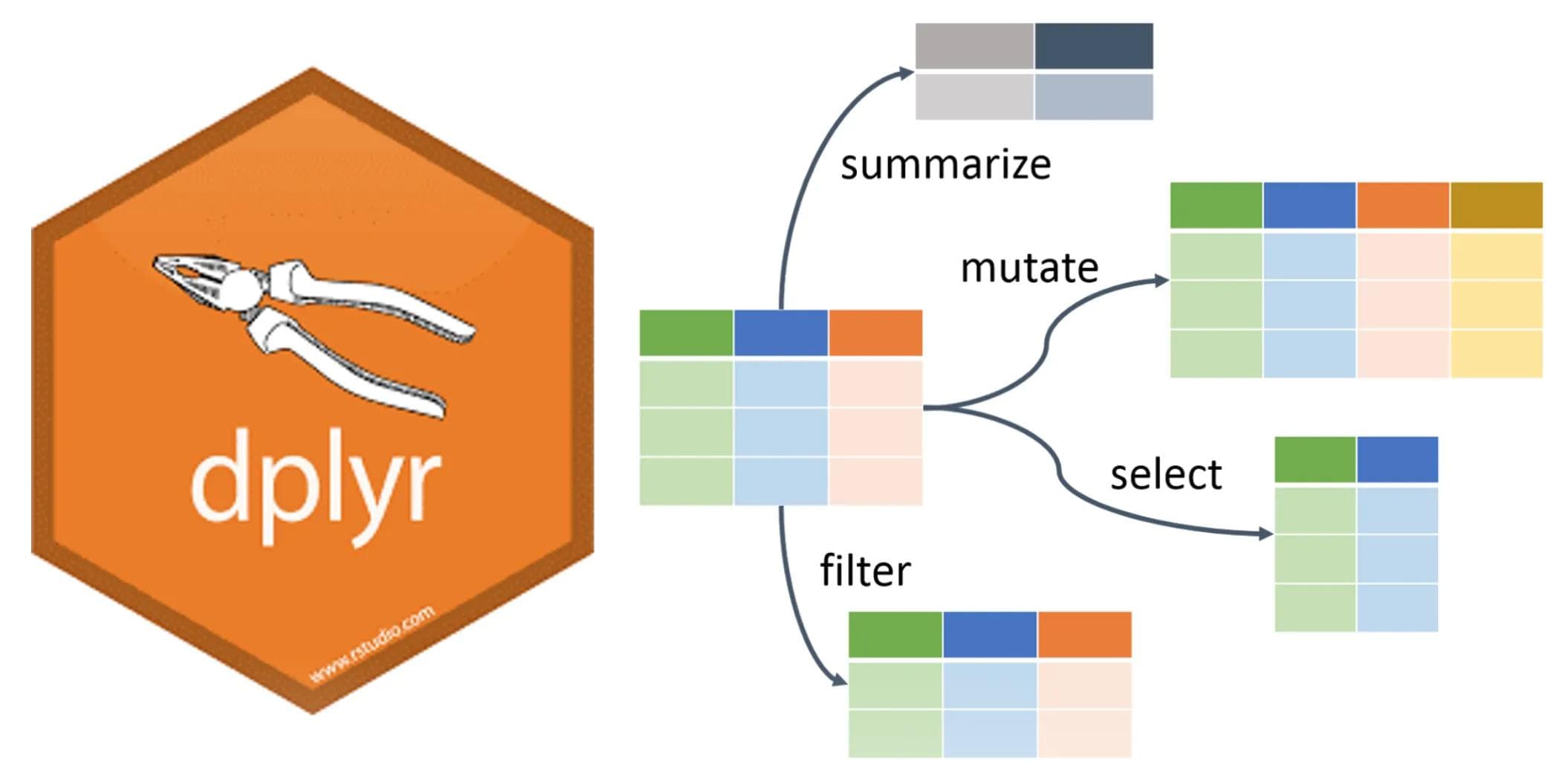
One of the core packages of the tidyverse in R, dplyr was released in 2014. Hadley Wickham, the original creator of the dplyr package, refers to it as a “grammar of data manipulation.” This is because the package provides a set of verbs (functions) to describe and perform common data preparation tasks. One of the core challenges in programming is mapping from questions about a data set to specific programming operations. The presence of a data manipulation grammar makes this process smoother, as it enables you to use the same vocabulary to both ask questions and write your program. Specifically, the dplyr grammar lets you easily talk about and perform tasks such as the following:
- Select specific features (columns) of interest from a data set
- Filter out irrelevant data, and keep only observations (rows) of interest, based on specified conditions
- Mutate a data set by adding more features (columns)
- Arrange observations (rows) in a particular order
- Summarize data in terms of aggregates such as the mean, median, or maximum
- Join multiple data sets together into a single data frame.
You can use these words when describing the algorithm or process for interrogating data, and then use dplyr to write code that will closely follow your “plain language” description because it uses functions and procedures that share the same language. Indeed, many real-world questions about a data set come down to isolating specific rows/columns of the data set as the “elements of interest” and then performing a basic comparison or computation (e.g., mean, count, max). While it is possible to perform such computation with base R functions, the dplyr package makes it much easier to write and read such code.
Source: Towards Data Science
Starting out with dplyr
Since dplyr is an external package, you will need to install it (once per machine) and load it in each script in which you want to use the functions:
1 install.packages("dplyr") # once per machine
2 library("dplyr") # in each relevant script
After loading the package, you can call any of the functions just as if they were built-in functions. Incidentally, if you are interested in installing more packages in the tidyverse collection, such as tidyr or ggplot2, you can install them all at once by loading the collected tidyverse package.