XGBoost
What is XGBoost?
XGBoost is an open source, ensemble machine learning algorithm that utilizes a high-performance implementation of gradient boosted decision trees. An underlying C++ codebase combined with a Python interface sitting on top makes XGBoost a very fast, scalable, and highly usable library.
XGBoost is an algorithm that has recently been dominating applied machine learning (ML) and Kaggle competitions for structured or tabular data. The XGBoost algorithm was developed as a research project at the University of Washington, and presented at the SIGKDD Conference in 2016. Since its introduction, this algorithm has not only been credited with winning numerous Kaggle competitions, but also for being the algorithm powering several cutting-edge industry applications. As a result, there is a strong community of data scientists contributing to the XGBoost open source projects with ~500 contributors and ~5000 commits on GitHub.
To understand how XGBoost works, you need to understand decision trees, ensembles, boosting, and gradient boosting.
Decision Tree Illustration from Titanic Survival Rates
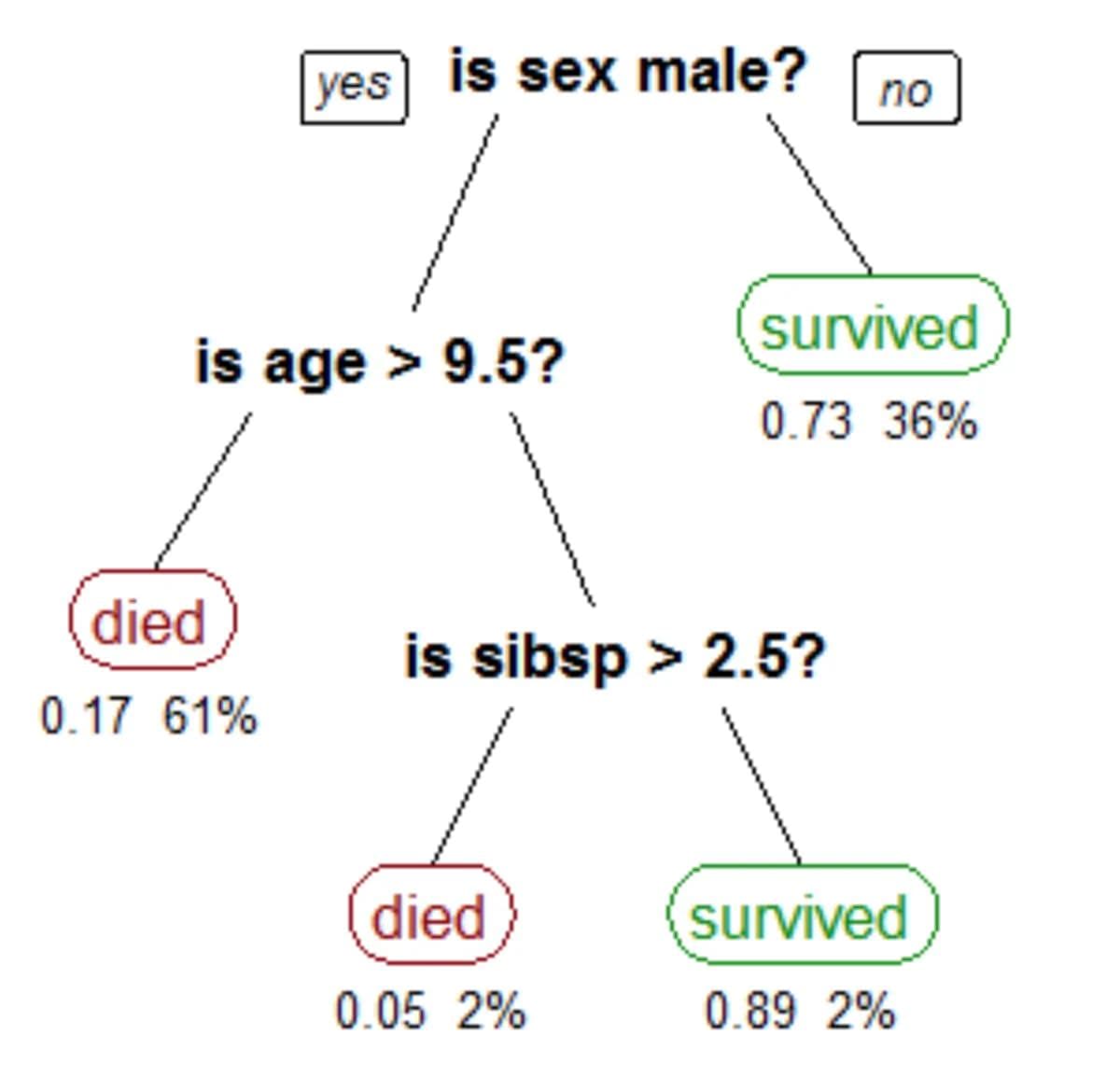
Source: Vighnesh Tiwari
Decision trees are a type of ML algorithm that have a tree-like graph structure that is used for prediction. The leaves in a decision tree correspond to target classes, and each node in a decision tree represents an attribute. The popular electronic game 20Q and Alexa skill Twenty Questions are both examples of a decision tree in action.