PyTorch
What is PyTorch?
PyTorch is an open source machine learning library, released by Facebook’s AI Research lab in 2016. It can be used across a range of tasks, but is particularly focused on training and inference of deep learning tasks, like computer vision and natural language processing.
PyTorch and TensorFlow lead the list of the most popular frameworks in deep learning. As the name implies, PyTorch is primarily meant to be used in Python, but it has a C++ interface too. Python enthusiasts generally appreciate its imperative programming style, which they view as more “Python-natural” than that of other, more declarative frameworks. PyTorch fits smoothly into the Python machine learning ecosystem.
PyTorch provides a Python package for high-level features such as computation on multidimensional data arrays, also known as tensors. This capability is similar to NumPy’s, but PyTorch provides strong GPU support – unlike NumPy which natively works with CPUs. PyTorch also provides deep neural networks/ deep learning built on an automatic differentiation system. To understand an automatic differentiation system, let’s briefly review computation graphs.
Computation Graph Illustration for Simple Neural Network
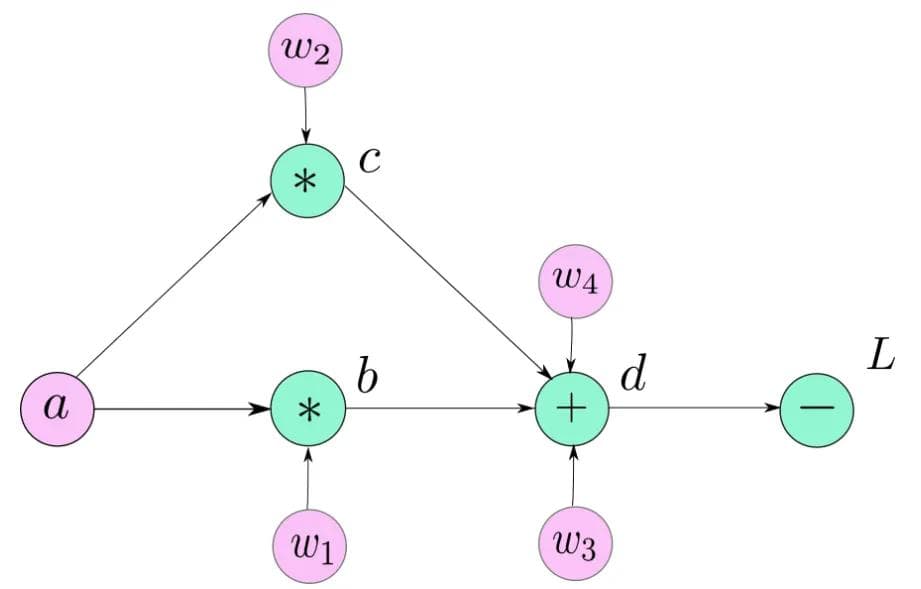
Source: Paperspace Blog
This simple computation graph comprises mathematical operators (in green), and user-defined variables (in pink). Additionally, the variables, b, c and d are created as a result of mathematical operations. Each node of the computation graph, with the exception of user-input leaf nodes (w1, w2, w3, and w4), can be considered as a function which takes some inputs and produces an output. For example in this illustration:
d = f(w3b, w4c)
In deep learning systems, we would calculate the gradient/ derivative of this function, and then there would be a backtracking step where algorithms run through the computation graph in reverse.
PyTorch creates something called a Dynamic Computation Graph, which means that the graph is generated on the fly, and the non-leaf nodes (b, c and d in this example) are not retained in memory. The dynamic graph paradigm allows you to make changes to your network architecture during runtime, as a graph is created only when a piece of code is run. This means a graph may be redefined during the lifetime for a program since you don’t have to define it beforehand.
PyTorch in Production
With the latest release of PyTorch, mobile deployment and TorchServe are supported to make it easier to move PyTorch models to production. TorchServe supports deploying trained models at scale without having to write custom code, including RESTful endpoints for application integration. TorchServe supports any machine learning environment, including Amazon SageMaker, Kubernetes, and Amazon EKS.