Apache Spark
What is Apache Spark?
Apache Spark is an open source, distributed computing framework and set of libraries for real-time, large-scale data processing. Spark was created in 2009 at UC Berkeley to address many of Apache Hadoop’s shortcomings, and is much faster than Hadoop for analytic workloads because it stores data in-memory (RAM) rather than on disk.
Spark has many built-in libraries that implement machine learning algorithms as parallel processing jobs, making them easy to parallelize across many compute resources. Spark is the most actively developed open-source framework for large-scale data processing.
Spark applications consist of a driver process and a set of executor processes. The driver process is responsible for three things:
- maintaining information about the Spark application;
- responding to a user’s program or input; and
- analyzing, distributing, and scheduling work across the executors.
The executors are responsible for executing code assigned to it by the driver and reporting the state of the computation, on that executor, back to the driver node.
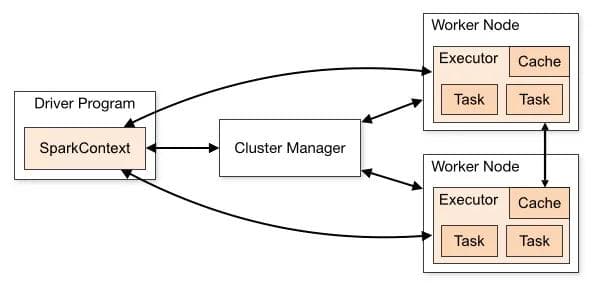
Source: Apache Spark
In general, Spark will be most appropriate when your data cannot fit into memory on a single machine – i.e., data greater than hundreds of gigabytes. Some of the most popular use cases for Spark include:
- Streaming data: Spark Streaming unifies disparate data processing capabilities, allowing developers to use a single framework to continually clean and aggregate data before they are pushed into data stores. Spark Streaming also supports trigger event detection, data enrichment, and complex session analysis.
- Interactive analysis: Spark is fast enough to perform exploratory queries on very large data sets without sampling. By combining Spark with visualization tools, complex data sets can be processed and visualized interactively.
- Machine learning: Spark comes with an integrated framework for performing advanced analytics that helps users run repeated queries on sets of data. Among the components found in this framework is Spark’s scalable Machine Learning Library (MLlib). MLlib can work in areas such as clustering, classification, and dimensionality reduction.
Spark involves more processing overhead and a more complicated set-up than other data processing options. Alternatives such as Ray and Dask have recently emerged.