Model monitoring
What is model monitoring?
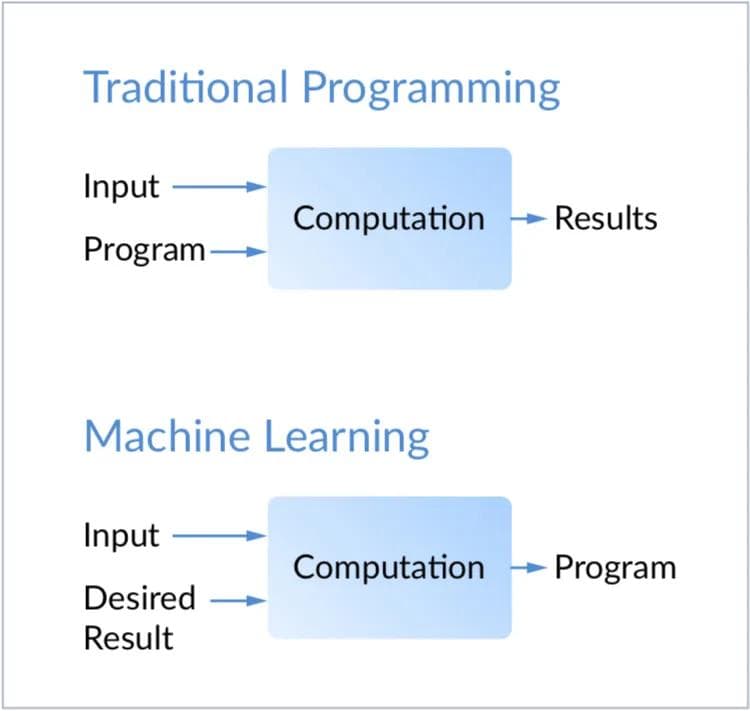
Model monitoring is an operational stage in the machine learning lifecycle that comes after model deployment. It entails monitoring your ML models for changes such as model degradation, data drift, and concept drift, and ensuring that your model is maintaining an acceptable level of performance.
Machine learning models are often deployed to automate decisions and critical business processes (e.g., claims processing, fraud detection, and loan approval). These probabilistic ML models, unlike in traditional software, can change if production data diverge from the data used to train the model. Said differently, a model’s behavior is determined by the picture of the world it was “trained” against — but real-world data can diverge from the picture it “learned.” For example, if you trained a mouse to perfectly navigate a maze, the mouse would not perform as well when placed into a new maze it had not seen before.
Models can degrade for a variety of reasons: changes to your products or policies can affect how your customers behave; adversarial actors can adapt their behavior; data pipelines can break; and sometimes the world simply evolves. The most common reasons for model degradation fit under the categories of data drift and concept drift.
A new class of software has emerged recently to help with model monitoring. While typical functional monitoring schemes for uptime, usage, and response times are usually sufficient to ensure model SLAs are met and that models are online, model monitoring software helps with more specialized metrics to monitor model predictions, data (input) drift, and concept drift.
Model monitoring tools such as Domino Model Monitor are available to automate model evaluation and provide alerts when production models have degraded to the point where an expert should perform a detailed evaluation.
Domino model monitor
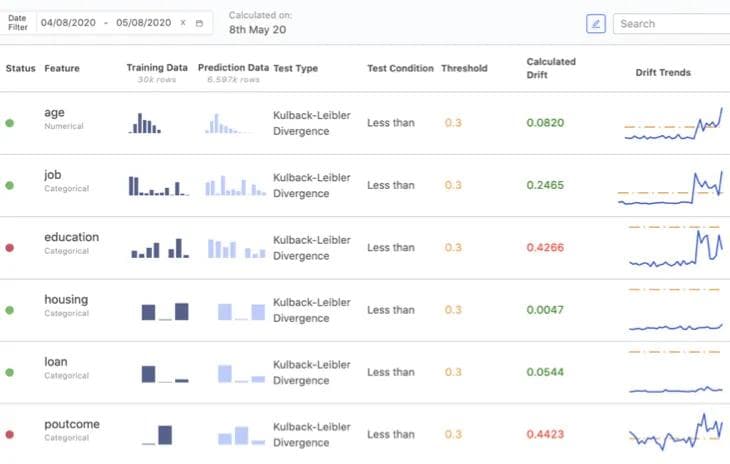
Expertise is needed to set up systems to ensure that a monitoring program effectively manages the entire portfolio of model assets. Every statistically-based monitoring system will produce false alarms (aka, type-I errors) and will miss real issues (aka, type-II errors). Statistical expertise is needed to manage the balance of type-I and type-II errors and identify early signs of model health degradation. Model monitoring cannot be left to IT or data engineering alone; data scientists share responsibility for the proper monitoring of models.
Finally, model monitoring should complete the feedback loop to model research by alerting for, or automatically triggering, the retraining of models that have degraded.