Considerations for Using Spark in Your Data Science Stack




This article covers the considerations to assess if Spark is the right technology for your data science needs. It also covers Spark’s architecture, alternative frameworks, and Domino’s support for on-demand Spark.
You have likely heard of Apache Spark, and may have even used it. Spark is a framework and set of libraries for parallel data processing. It was created in 2014 to address many of Apache Hadoop’s shortcomings, and is much faster than Hadoop for analytic workloads because it stores data in-memory (RAM) rather than on disk. It also has many built-in libraries that implement machine learning algorithms as MapReduce jobs (described later), making them easy to parallelize across many compute resources. Spark is the most actively developed open-source framework for large-scale data processing.
There is a famous saying by Abraham Maslow: “If all you have is a hammer, everything looks like a nail.” In the case of Spark, many users are initially drawn to its ability to do data engineering / ETL work on very large or unstructured datasets. After initial success with Spark, they gain the confidence to use it for other tasks and quickly run into its limitations. For example, many data scientists report that Spark consumes a lot of resources across its distributed computing framework, and will actually slow data processing versus using more conventional means for several use cases.
This blog explores the strengths and weaknesses of Spark, specifically in the context of modern data science and machine learning workflows, to help enterprises incorporate Spark wisely into their analytics technology strategy.
Spark Architecture
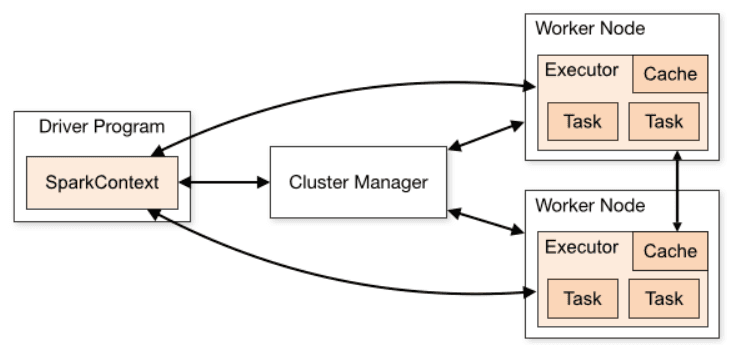
To understand the specifics of appropriate Spark use cases, it’s important to first understand the basic Spark architecture. Spark applications consist of a driver process and a set of executor processes. The driver process is responsible for three things:
- maintaining information about the Spark application;
- responding to a user’s program or input;
- analyzing, distributing, and scheduling work across the executors.
The executors are responsible for executing code assigned to it by the driver and reporting the state of the computation, on that executor, back to the driver node.
Source: Apache Spark
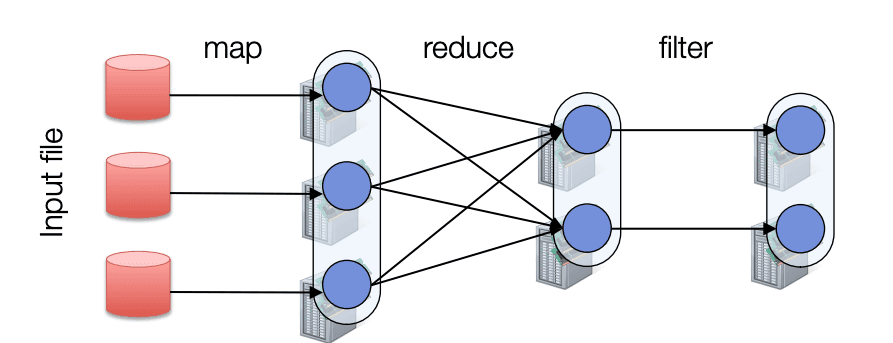
Spark’s computation model is based on Resilient Distributed Datasets (RDDs), a collection of objects across a cluster with user-controlled partitioning and storage. Spark builds RDDs with an approach that borrows heavily from Hadoop’s MapReduce design. The “map” tasks split the input dataset into independent chunks which are processed in a completely parallel manner, and then the “reduce” task groups and partitions the mapped data. Spark’s MapReduce approach is based on a more evolved model called Directed Acyclic Graph (DAG), and it supports iteration more effectively than MapReduce in Hadoop. But it still processes data in parallel, where there is a block step and then a wait step where everything synchronizes.
Source: Stanford University
Factors to Consider when Assessing Spark
There is no set formula for when using Spark is the “right” answer. Typically, you first need to determine what processing logic is needed and how much time and resources would be required in a non-Spark environment using your programming language of choice. Then, you weigh that against the benefits and drawbacks (e.g., more overhead, more complicated set-up) that come with adding a distributed computing framework such as Spark. In general, Spark will be most appropriate when your data cannot fit into memory on a single machine – i.e., data greater than hundreds of gigabytes.
Some of the most popular use cases for Spark include:
- Streaming data: Spark Streaming unifies disparate data processing capabilities, allowing developers to use a single framework to continually clean and aggregate data before they are pushed into data stores. Spark Streaming also supports trigger event detection, data enrichment, and complex session analysis.
- Interactive analysis: Spark is fast enough to perform exploratory queries on very large data sets without sampling. By combining Spark with visualization tools, complex data sets can be processed and visualized interactively.
- Machine learning: Spark comes with an integrated framework for performing advanced analytics that helps users run repeated queries on sets of data. Among the components found in this framework is Spark’s scalable Machine Learning Library (MLlib). MLlib can work in areas such as clustering, classification, and dimensionality reduction.
Spark involves more processing overhead and a more complicated set-up than other data processing options. Here are a few considerations about why Spark may not be the right framework for some use cases:
Effectiveness of a MapReduce paradigm.
Spark is fundamentally based on Hadoop’s design architecture and leverages a MapReduce approach (DAG) to create blocks of data in memory (RDDs). This design pattern can be very effective when each block/task requires about the same amount of processing time, but it can be slow for many machine learning workflows that are comprised of very heterogeneous tasks. For example, training deep neural networks could be very inefficient with a MapReduce approach, as there could be extreme variance in algorithmic complexity at each step.1
Spark sophistication of your data science team.
Spark is written in Scala, and has APIs for Scala, Python, Java, and R. A Scala developer can learn the basics of Spark fairly quickly, but to make Spark function well, they will also need to learn memory- and performance-related topics such as:
- Partitions
- Nodes
- Serialization
- Executors, the JVM, and more…
Adopting Spark typically involves retraining your data science organization.
Debugging capabilities of your team.
Debugging Spark can be frustrating, as memory errors and errors occurring within user-defined functions can be difficult to track down. Distributed computing systems are inherently complex, and so it goes for Spark. Error messages can be misleading or suppressed, and sometimes a function that passes local tests fails when running on the cluster. Figuring out the root cause in those cases is challenging. Furthermore, since Spark is written in Scala, and most data scientists only know Python and/or R, the debugging of a PySpark application can be quite difficult. PySpark errors will show both Java stack trace errors as well as references to the Python code.
IT challenges with maintaining Spark.
Spark is notoriously difficult to tune and maintain. IT typically does not have deep expertise in Spark-specific memory and cluster management so ensuring that the cluster does not buckle under heavy data science workloads and many concurrent users is challenging. If your cluster is not expertly managed, performance can be abysmal, and jobs failing with out-of-memory errors can occur often.
Spark Alternatives are Emerging
As recently as five years ago, Hadoop was the framework of choice when it came to distributed data processing. The largest analytics conference in the world was even named after it. Today, clusters sit idle as many enterprises migrate off Hadoop.
The meteoric rise and fall of Hadoop is a perfect example of the speed with which trends can change in enterprise analytics technology. With this in mind, the thoughtful IT leader today must ask, “is Spark here to stay, or will it go the way of Hadoop in a matter of years?”
Already, there are multiple distributed computing frameworks that offer compelling and mature alternatives to Spark.
Dask
In 2018, Dask was released to create a powerful parallel computing framework that is extremely usable to Python users, and can run well on a single laptop or a cluster. Dask is lighter weight and easier to integrate into existing code and hardware than Spark.
Whereas Spark adds a significant learning curve involving a new API and execution model, Dask is a pure Python framework, so most data scientists can start using Dask almost immediately. Dask supports Pandas dataframes and Numpy array data structures, so data scientists can continue using the tools they know and love. Dask also integrates tightly with Scikit-learn’s JobLib parallel computing library that enables parallel processing of Scikit-learn code with minimal code changes.
Ray
Researchers at UC Berkeley’s RISELab, which is affiliated with the original development of Spark, note that existing data processing and distributed computing frameworks fall short of satisfying today’s complex machine learning requirements. Spark and Hadoop, for example, do not support fine-grained computations within milliseconds or dynamic execution. They are creating Ray from the ground up to support primary machine learning use cases, including simulation, distributed training, just-in-time/rapid computing, and deployment in interactive scenarios while retaining all the desirable features of Hadoop and Spark.
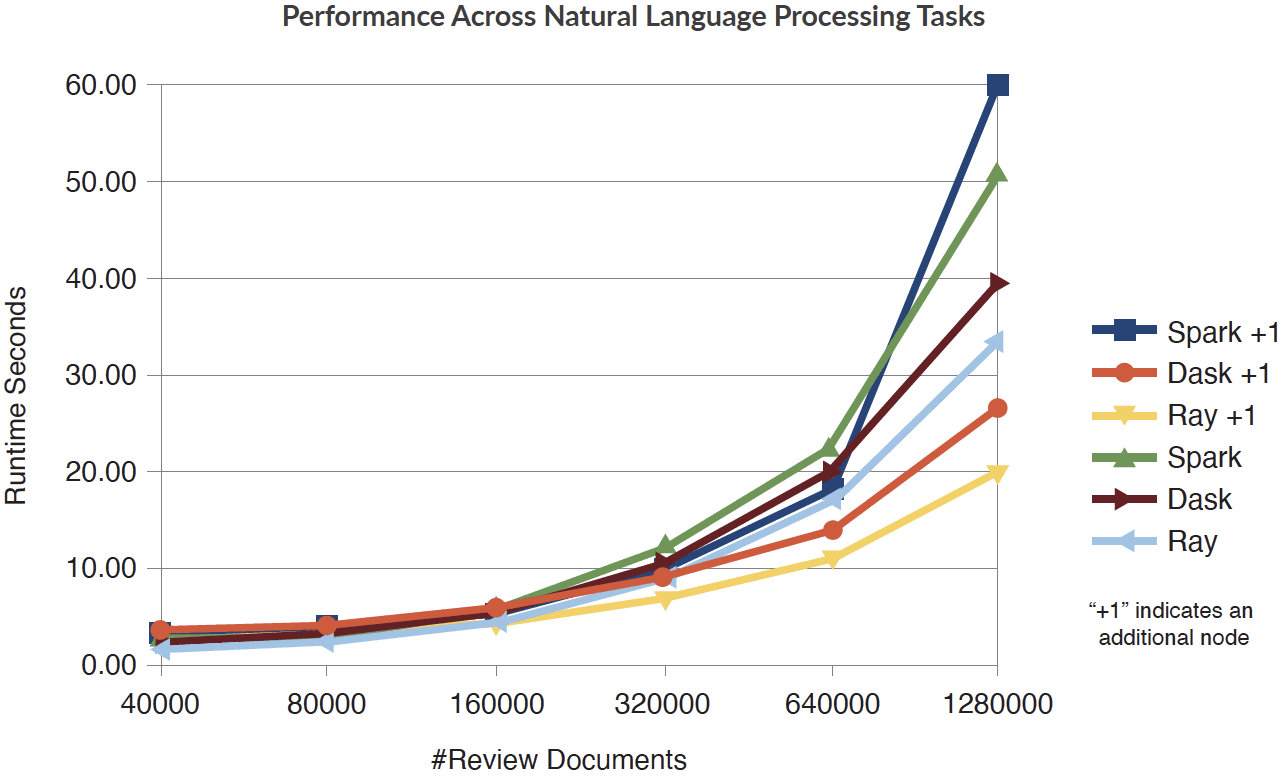
Initial benchmarking results have been very positive, and show that Ray outperforms both Spark and Dask in certain applications. For example, Ray and Dask both outperform Spark in this benchmark of common natural language processing tasks, from text normalization and stemming to computing word frequency tables.
Source: Towards Data Science
Domino: A Platform for Easy Access to Spark AND Other Frameworks
Innovations in data science happen quickly. Ten years ago everyone was talking about the potential of Hadoop. Five years ago it was Spark. Today we are at another crossroads with new distributed computing frameworks becoming more common. Just like you need more than a hammer in your toolbox, you need the flexibility to work with the right language, IDE, environment, etc. for the project at hand. It’s critical to choose a path that allows you to embrace the most powerful tools today while having the flexibility to support the new tools of tomorrow.
Domino is a platform that is purpose-built for IT and data science departments in large organizations. It allows data science organizations to build, deploy, and share models using the tools they know and love. Under the hood, Domino directly manages your preferred distributed computing frameworks, as well as your infrastructure resources, tools, and IDEs. This allows data science teams to use the tools they want with minimal IT overhead while meeting IT’s requirements. Specifically for distributed computing and high-performance machine learning, Domino supports several frameworks, including Spark and TensorFlow, with plans to support Dask, Ray, and additional frameworks as they become more prominent.
Unlike some platforms that are built on Spark, Domino can unify Spark and non-Spark workloads in a single platform – creating a technology-agnostic approach that supports parallel processing across cores. For example, one data scientist working in Domino can spin up a Spark cluster for a distributed computing workload, like image transformations; their colleague can spin up a TensorFlow instance using GPUs for machine learning training. Their work will be united within the same Domino platform so they can collaborate, comment on, and reproduce each other’s work.
Domino also simplifies setting up clusters and instances so data scientists don’t need to fight for IT resources. All they have to do is select their desired compute capacity, and with one click Domino automatically connects the cluster to their workspace (e.g., Jupyter) or batch script. There is no DevOps or dependency management pain; packages automatically load across the cluster with Domino.
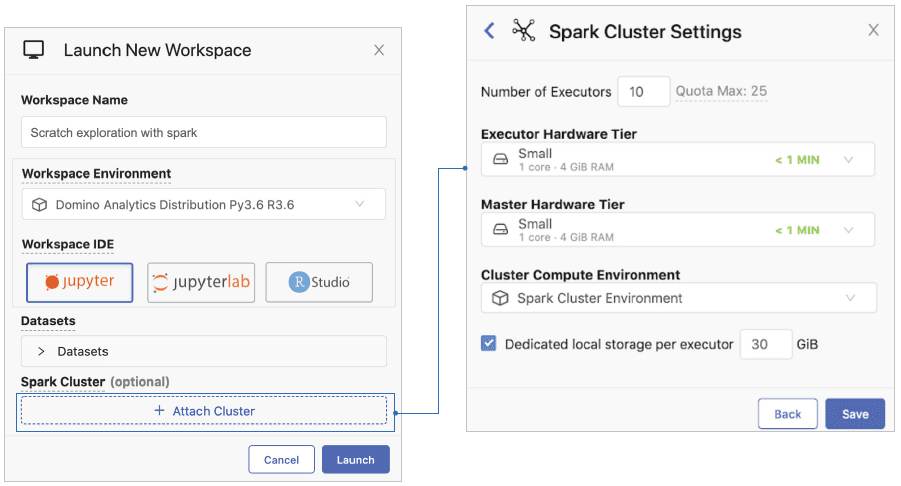
With Domino’s support for On-Demand Spark clusters, data scientists can now access the power, speed, and flexibility that they need to run bursty workloads, and IT teams can more readily support them without the burden of managing a separate Spark cluster. Efficiency and governance are baked in, and IT can reduce computing costs with automatic cluster de-provisioning. There is just a single footprint to manage, and no need for multiple clusters or ad hoc requests. And IT can eliminate the dependency management hassle that would come with different packages and Spark binaries; Domino fully manages the packages across the cluster. On top of that, you get the peace of mind knowing that Domino is technology-agnostic, and will support the best technologies for parallel data processing on hardware clusters moving forward.
Conclusion
Spark has its strengths, but it is not the be-all and end-all for data science that some vendors would lead you to believe. It is important to understand its strengths and weaknesses so you can apply Spark when it makes sense, and avoid it when it does not. But more importantly, invest in platforms that leave your options open so that you do not get locked into one ecosystem, and can adopt new data processing frameworks as they mature.
1See “Large Scale Distributed Deep Networks” by Jeffrey Dean, et al.