Built in Domino: Agentic AI for Credit Risk Decisions
Scoring loans has always been the easy part. Explaining those decisions in a defensible, auditable way is where AI has historically fallen short, and where this application was built to make a difference.



Built in Domino is a series of first-hand accounts from Domino users about what they built, how they built it, and what they learned along the way. Each installment walks through a real workflow, the decisions behind it, and the practical steps to reproduce something similar on your own Domino deployment.
Defensibility is the point at which AI creates as many problems as it solves. A model can process thousands of applications faster than any team of underwriters. But a probability score on its own doesn't tell a loan officer what drove the decision, whether the inputs make sense in context, or how to explain the outcome to someone sitting across the desk. The score is the easy part. The explanation is the hard part.
Almost counterintuitively, explainability is exactly the problem that generative AI in this space is working to solve. We approached it by pairing an XGBoost model with an agentic AI system that explains its own decisions in plain language, built on a governance foundation designed to support compliance with the 2024 EU AI Act.
What does it actually take to go from raw data to an explainable AI credit risk application, complete with governance and auditability? For most teams, that journey spans weeks of infrastructure wrangling, environment headaches, and disconnected tooling. Building on Domino, I did it in a couple of hours, and I had never touched the platform before.
How can systems that use generative AI have explainability?
The core model is an XGBoost classifier trained on a synthetic dataset of 10,000 loan applications. XGBoost is a machine learning algorithm that builds predictions by combining many small decision trees, each one correcting the errors of the last. It is widely used in financial services because it handles structured tabular data, such as loan applications, exceptionally well, and regulators and model risk teams are also familiar with it. It outputs a default probability and a risk tier (low, medium, or high) based on inputs such as credit score, debt-to-income ratio, employment duration, and credit utilization. That part is the score.
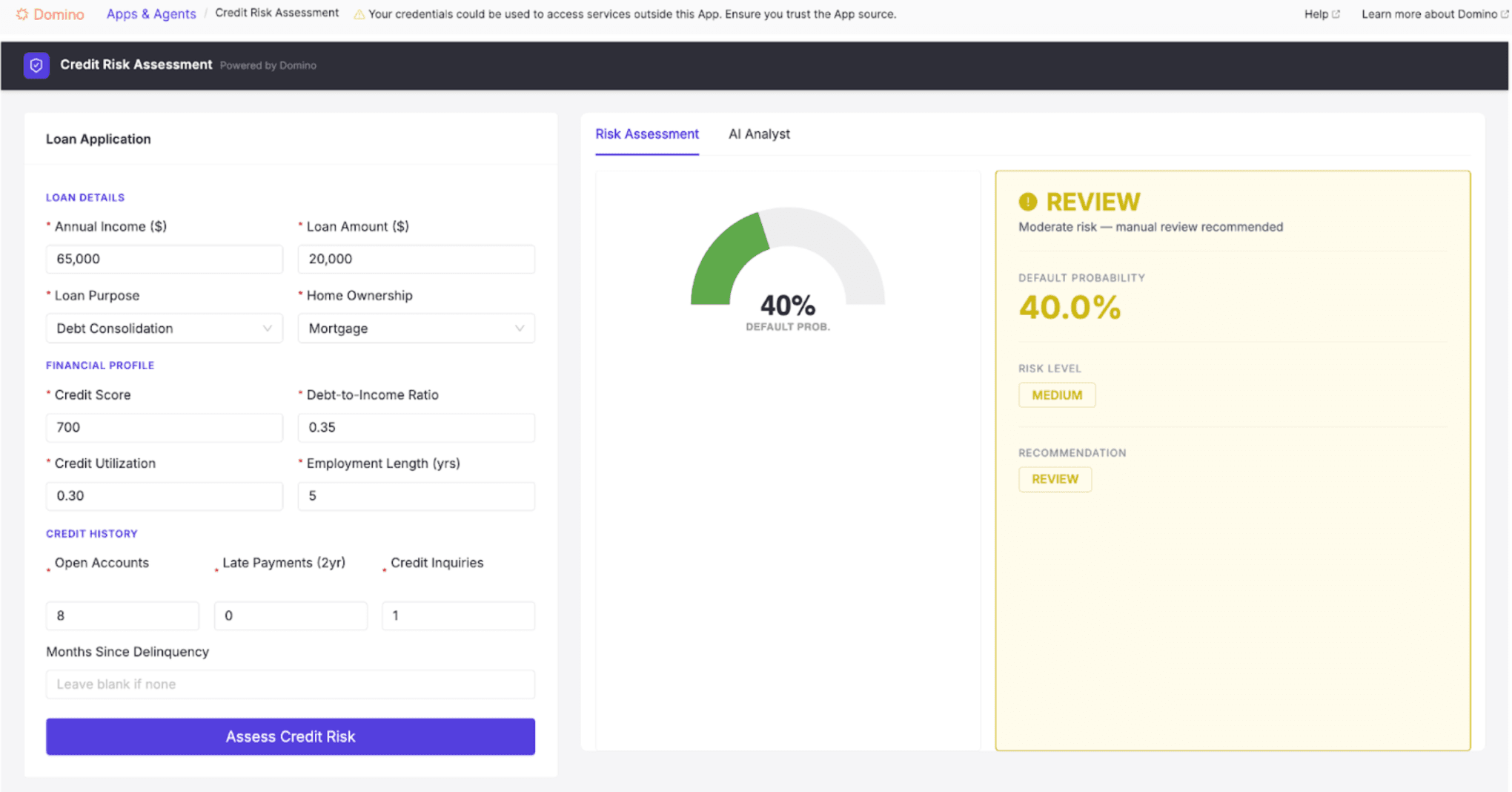
But the score isn’t enough. What makes the application particularly useful to a loan officer is the layer on top.
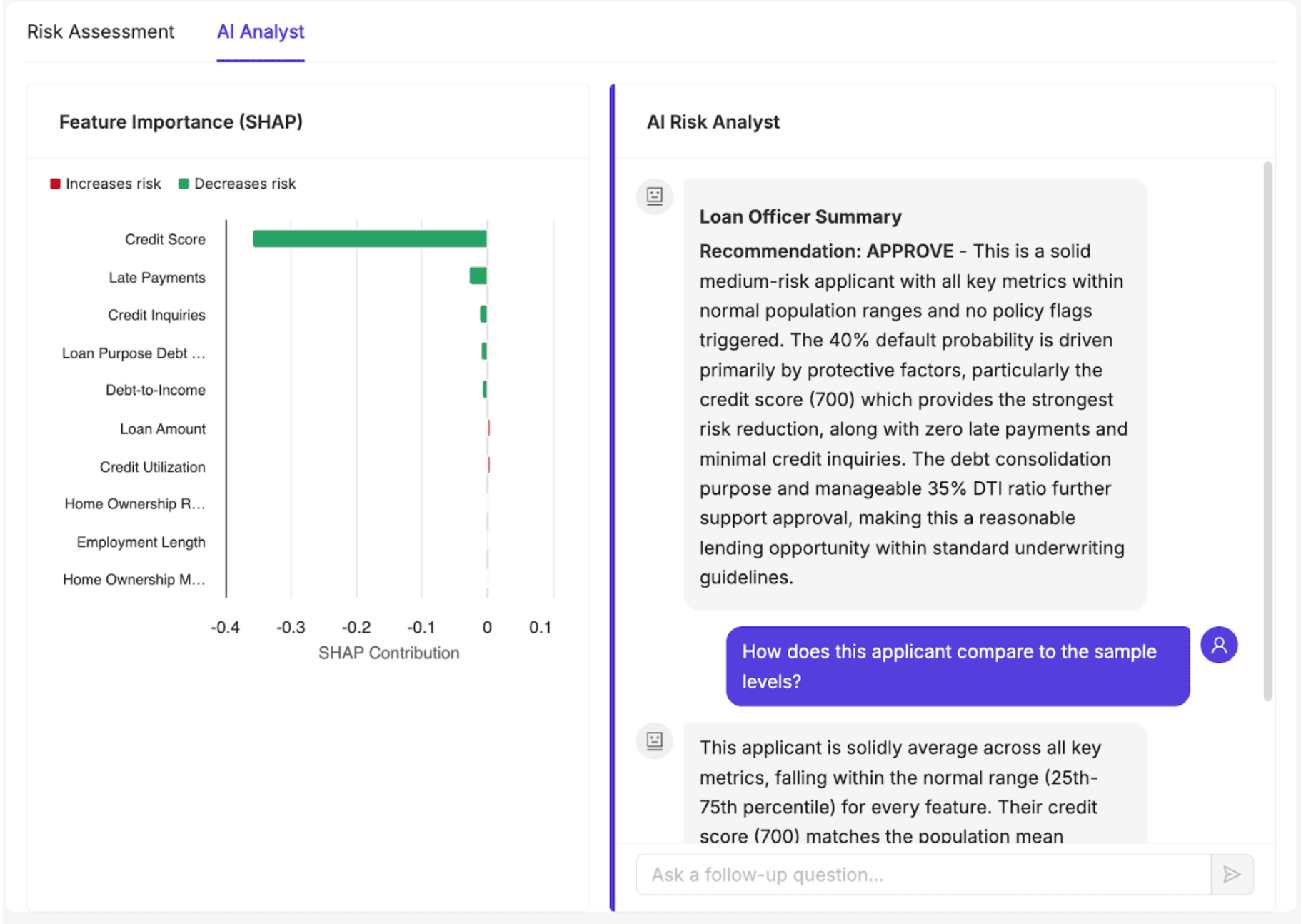
The AI Analyst view pairs a SHAP-based feature-importance plot with an agentic AI system that generates a narrative explanation for every application. SHAP (SHapley Additive exPlanations) quantifies how much each input feature contributed to a given prediction. The agent uses that output as a starting point, then goes further: it investigates the case before writing its explanation, using three tools:
- Population benchmarking compares the applicant against the broader loan population
- Risk threshold flagging surfaces specific warning signals, such as a debt-to-income ratio above acceptable bounds
- Feature analysis identifies and explains the key drivers behind each decision
What makes this system agentic, rather than a sophisticated prompt wrapper, is how it arrives at its explanation. A standard generative AI system, given a SHAP output, would summarize what it was handed. This agent decides what to investigate before it writes anything. It determines which tools to call based on the applicant profile, reasons across the outputs, and only then constructs an explanation. The loan officer isn't reading a summary of a score. They're reading an explanation built from active reasoning across the applicant's data, population context, and policy rules.
A script-driven system executes the same sequence of steps every time, regardless of what it finds. This agent is goal-directed. It evaluates the situation, decides which tools are worth calling for this particular applicant, and adapts based on its findings. For one applicant, the most important signal might be a credit score below policy thresholds. For another, it might be a debt-to-income ratio that looks acceptable in isolation but ranks in the top 5% of the population. The agent surfaces whichever story the data is actually telling, rather than running every applicant through the same fixed narrative.
What it actually took to build this foundation
One of the more revealing aspects of this build was how little of it required traditional software development scaffolding. Both the application and the agentic system started as plain-language descriptions of the problem.
The initial prompt for the application:
I want to build a credit risk assessment web app from scratch. Start by generating a synthetic dataset of 10,000 loan applications with realistic distributions for features like annual income, credit score, debt-to-income ratio, employment length, loan amount, number of open accounts, late payments in the last 2 years, total credit utilization, number of credit inquiries, and loan purpose. The target variable should be binary default/no-default with a realistic default rate. Once the data is generated, train an XGBoost classifier with a proper preprocessing pipeline, then fit a SHAP explainer so predictions have feature-level contributions. The frontend should be a React + Vite app following Domino design requirements, with a panel for the loan officer to enter applicant information and see the default probability, risk tier, and SHAP plot.The prompt for the agentic system:
I want to build an agentic AI system in Python that explains credit risk predictions to loan officers. Claude should act as a senior credit risk analyst that investigates the case using tools before writing an explanation, not just summarize what it's handed, but actively reason about it. The agent should compare the applicant profile to the population, check specific policy rules, and analyze the main features relevant to the prediction. Use Domino's built-in agent tracing capabilities so there is full observability and governance is satisfied.What helped enable this was a Claude Code plugin built for Domino, described in full in this blueprint, a reusable set of 20 skills that give Claude deep, native knowledge of the platform. Rather than functioning as a generic coding assistant, Claude understood Domino's patterns, SDK, and deployment model from the start. The skills that carried the most weight here were jobs, model endpoints, and GenAI tracing, each handling a distinct layer of the application.
What does compliance actually look like in practice?
Credit risk is a high-stakes, regulated use case. In the US, the Equal Credit Opportunity Act requires lenders to explain adverse credit decisions and demonstrate that models do not discriminate. Internationally, the 2024 EU AI Act explicitly classifies credit scoring as high-risk, with full compliance obligations taking effect on August 2, 2026. The regulation applies extraterritorially, meaning that any organization whose AI affects EU residents must comply, regardless of where it is headquartered.
Using the EU AI Act as the compliance framework means that tracking how the model was built, by whom, and under what conditions was just as important as model performance.
As new loan data arrives, it is added to a Domino Dataset, making it automatically available to the project without manual transfer or synchronization. A scheduled Domino Job can be configured to pick up the new data, retrain the model, and run it through the preprocessing pipeline. The results flow into experiment tracking, where the new model's performance is compared directly against the version currently in production. If the new model is stronger, it can be promoted through a governed approval workflow, with a complete record of how it compares to its predecessor, what evidence supported the decision, and who signed off. For a regulated application where model changes can affect lending decisions at scale, that lineage is required.
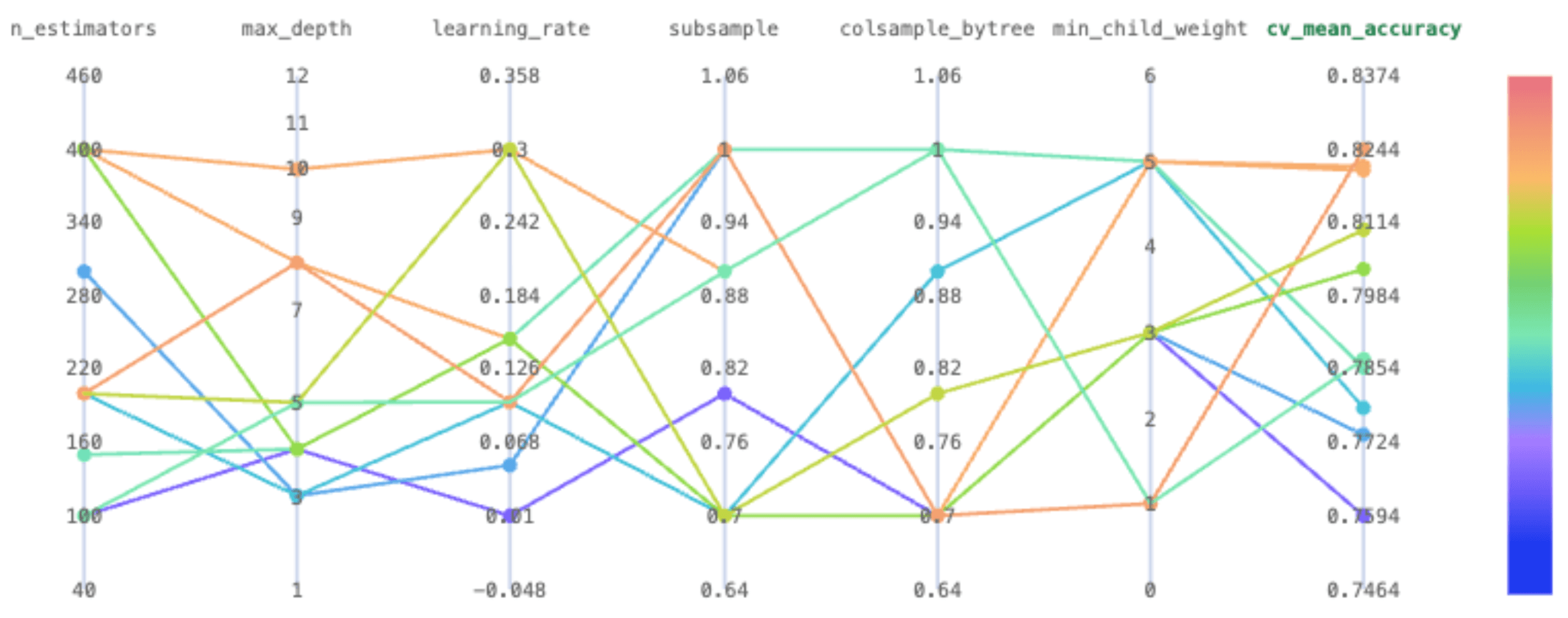
Building on Domino, what I noticed most was how naturally each piece of the workflow connected to the next. Data, code, environments, compute, and governance live in one place. I was never jumping between tools or manually reconciling state across systems. The experiment tracking view makes it straightforward to compare hyperparameter runs side by side, and the model registry keeps a clean, versioned record of every model and its associated parameters.
Domino handles the broader governance layer through governed bundles: formal submission packages where artifacts and evidence are collected against defined policies. Those policies are customizable, covering performance metric thresholds, data lineage documentation, fairness evaluations, and manual sign-off from specific stakeholders. They evolve alongside the model rather than being assembled after the fact.
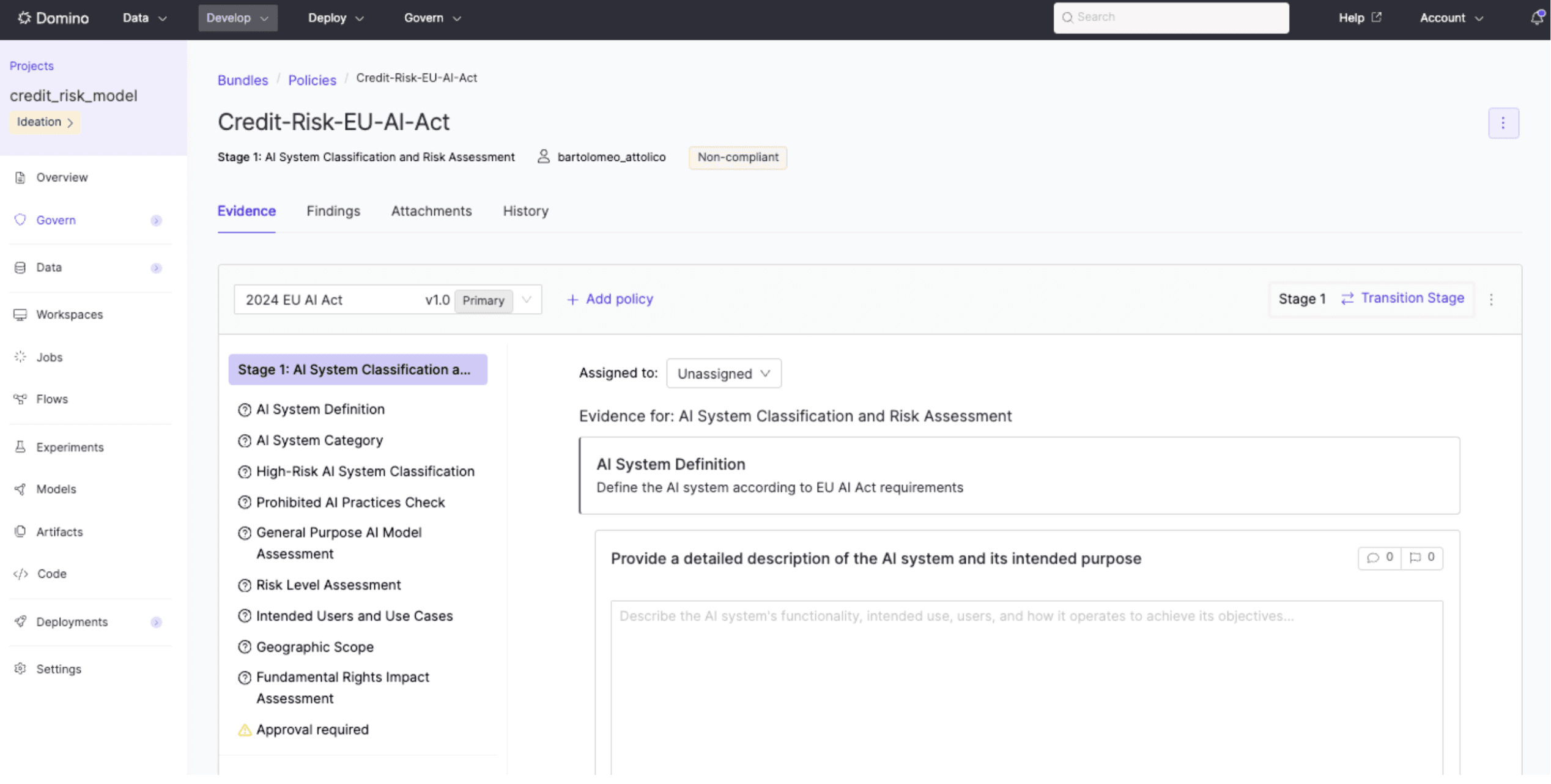
In regulated environments, the cost of separating development from governance is rarely visible until a model is ready to deploy and suddenly isn't. Embedding compliance into the project from the start means governance becomes a continuous property of the work, not a checkpoint at the end.
What a connected platform changes
Most AI projects don't fail because of the model. They fail because the surrounding system, including environment management, data versioning, experiment tracking, and deployment infrastructure, is assembled from disconnected tools and eventually comes apart.
Without a unified platform, every layer of this application would have been managed and architected separately. Code would live in GitHub, but with no native connection to the environment it ran in or the data it trained on. Environment configurations would be a requirements.txt file checked into the repo, with no guarantee that it actually reproduces the same setup across machines or that it reflects what was installed when a specific model was trained. Model versioning would be a manual process of saving artifacts to S3 or a shared drive, with filenames like model_v3_final_updated.pkl, and a spreadsheet somewhere that tracks which version maps to which training run. Connecting to data sources would mean managing access keys across team members, stored in .env files. Every time something changed, whether a new dependency, a different dataset, or an updated model, the setup would need to be partially or fully reconstructed. There is no single place where the full state of the project lives, so reproducing any prior result means retracing steps across five or six disconnected systems.
With Domino, that category of work largely disappears. Data lands in a versioned Dataset, immediately accessible to every job and workspace in the project. Environments are reproducible by design, so the setup used to train the model in development is identical to the one running in production. Experiments are tracked automatically, models are registered with full lineage, and deployment is a single command. Governance is not a separate workstream. It is built into the same system where the work happens.
As someone brand new to the platform, I was genuinely surprised by how quickly I could move. With Domino's AI Gateway, Agentic Tracing and Claude Code integrated directly into the environment, the gap between having an idea and having a deployed, auditable application narrowed dramatically. I wasn't assembling a stack. I was building the application.
The credit risk score was never the hard part. Loan officers have had scores for decades. What has been missing is a system that can stand behind the score, explain it, defend it, and update it as the world changes, all within the changing governance boundaries that regulations lending requires. That is what this application is built to do. And with the right platform underneath it, it is no longer a months-long infrastructure project.
For a deeper look at Claude Code within Domino check out our Blueprint: Claude Code on Domino: AI-assisted development with Domino skills