5 MLOps best practices for large organizations




Machine learning operations (MLOps) is more than just the latest buzzword in the artificial intelligence (AI) and machine learning (ML) community. Many companies are realizing they need a set of practices to efficiently get models built and into production, and MLOps does just that.
MLOps streamlines, standardizes, and automates the development and deployment of ML models, across the entire data science lifecycle, including the post-deployment monitoring and maintenance of ML models.
Currently, data scientists have several tools to support MLOps in their organizations. Yet 87% of machine learning models never make it to production due to technical challenges related to model development and deployment as well as high-level organizational challenges. If you want to succeed with your ML projects, you need to incorporate MLOps best practices to help you move forward quickly and efficiently.
In this article, you’ll learn about five best practices for MLOps teams with examples of MLOps practices used by well-known organizations.
Why should you incorporate MLOps best practices?
Taking a ML model from ideation to deployment and monitoring is a complex and time-consuming process. Additionally, this complexity increases rapidly when an organization tries to scale data science. Without MLOps practices and supporting infrastructure, organizations are forced to manually develop, validate, deploy, monitor, and manage models. This is a large-scale effort that involves multiple teams, stakeholders, and skill sets, and frequently gets bogged down because every model is created and deployed differently depending on the use case.
MLOps creates standard practices, enabled by technology, that streamline the steps in the data science lifecycle. Tasks that can take months without MLOps, can happen in days.
A critical element is automating the monitoring of models to ensure they continue to perform as expected or are remediated quickly. The end result is more accurate, robust, and reliable models in production.
Best practices for MLOps teams
Realizing the full promise of data science and machine learning is complicated and comes with a number of challenges.
The following MLOps best practices listed can help mitigate challenges by supporting automation and reducing the time spent to manage, develop, deploy, and monitor ML models in production.
Data set validation
Data validation is a critical first step towards building high quality ML models. For improving the predictions of an ML model, it’s important to validate the data sets along with training the model to generate value and provide better results. Detecting errors in data sets is crucial in the long run and is directly responsible for the performance of the ML models.
In practice, you can start with identifying duplicates, dealing with missing values, filtering data and anomalies, and cleaning it. Doing this improves the accuracy of the ML model and reduces time spent overall. .
The biggest challenge with validating data sets occurs when the data set becomes very large and complex, with different sources and formats.
Automated data validation ensures that the overall performance of the ML system isn’t adversely affected. As an example, TensorFlow is helpful with detailed data validation at scale.
Facilitate a collaborative culture
Creative ideas that drive breakthroughs in ML innovation arise from spontaneous interactions and non-linear workflows. Teams siloed while developing models, in turn, face inefficiencies, including duplicative efforts among colleagues, wasted time searching for past scripts/hardware configurations, and low ramp-up times.
Through taking away barriers to collaboration within your MLOps process, teams can work in sync while management can oversee project blockers. Having a centralized hub that regardless of what tools or language are used for ML, makes it easy to share work, collaborate on projects and share context that results in compounding knowledge and increased model velocity. But it won’t happen overnight. It relies on fostering a culture of collaborative processes alongside enabling technology. Ensuring your data scientists are embedded across your business and exchanging ideas from different areas allows the global team to adopt beneficial practices beyond what they wouldn't have otherwise recognized.
In practice, one of the world's largest insurers SCOR developed a collaborative culture through their Data Science Center of Excellence, which led to customer-first models developed in a fraction of the time it usually took them.
Application monitoring
ML models rely on clean and consistent data and will fail to make accurate predictions when the input data set is error-prone or departs from the characteristics of the data it was trained on. For this reason, monitoring pipelines is an important step to incorporate when adopting MLOps.
Going further, automating continuous monitoring (CM) can give you the confidence you need to release models in production while ensuring model performance degradation is caught quickly and remediated.s., Depending on the use case, the output of ML models can be utilized by customers or employees in real time in order to make decisions quickly. Therefore, it’s also necessary to monitor operational metrics, like latency, downtime, and response time.
For example, if there’s a huge sale on a website and the ML delivers irrelevant recommendations, the success rate of converting a user’s search query to a purchase decreases and impacts the business as a whole. Data auditing and monitoring the models’ performance post-deployment help in operating a smooth ML pipeline, which reduces the need for manual intervention.
In the real world, an example of an enterprise company deploying this strategy is DoorDash’s monitoring framework, which is used to collect insights and stats, and generate metrics to be monitored.
Reproducibility
Reproducibility in ML is a challenging task and requires tracking model artifacts such as the code, data, algorithms, packages and environment configurations. It’s well known that many data scientists begin model development manually in a Jupyter notebook keeping track of versions manually. This approach often lacks documenting the exact model artifacts, and makes it impossible to reproduce on another system.
To reproduce models easily, there needs to be a central repository that captures all the artifacts and their versions. It is critical to be able to spin up an exact replica the model that will deliver the exact same results. While this may be possible to do for a few modeling projects, without the right technology to facilitate capturing these details it becomes impossible as the number of projects scales. Not being able to reproduce models makes it harder for data scientists to show how the model delivered the output and for validation teams to recreate the results. It also makes it difficult to comply with regulatory requirements. Additionally, if a different team has to pick up work on a model or wants to use it as the starting point for work, quickly recreating work can ensure efforts are not wasted.
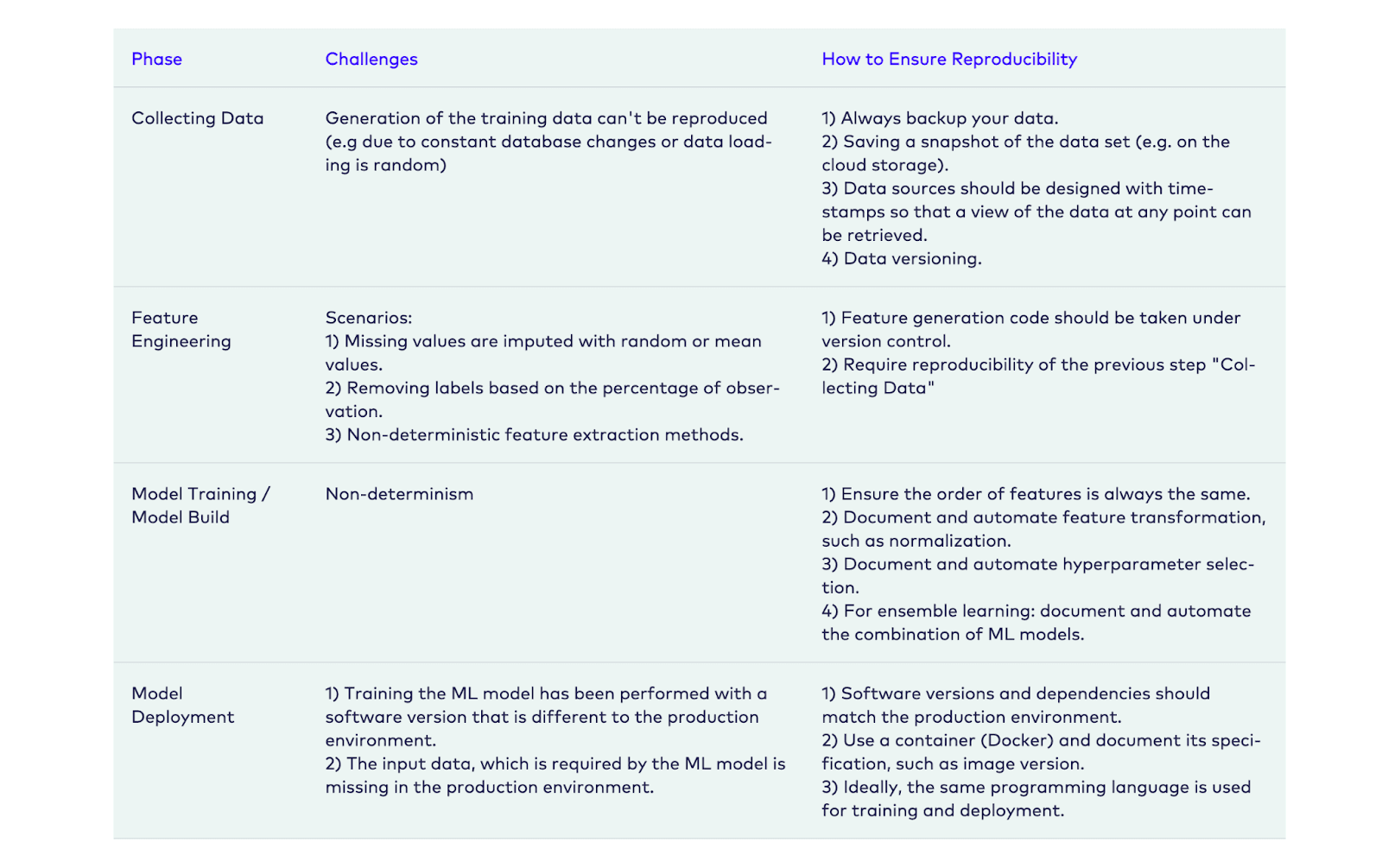
Airbnb uses an in-built framework called ML Automator that helps in achieving reproducible models.
Experiment tracking
Typically, a data science team simultaneously develops multiple models for a variety of business use cases. Numerous experiments are conducted before identifying and validating a candidate model to take to production. Tracking and versioning the various combinations of scripts, data sets, models, model architectures, hyperparameter values, the different experiments and their results is a core requirement for keeping track of what is happening within your models and which model should be used in production. building reproducible ML models.
Effective management of datasets and experiments is a fundamental requirement that can be efficiently coordinated by MLOps teams using a variety of tools like Domino Enterprise MLOps Platform.
Conclusion
Investing in MLOps is now a necessity for most companies. It makes it possible to get models into production efficiently and ensure they continue to perform reliably. MLOps helps organizations of all sizes streamline and automate their processes across the data science life cycle, and resolve issues of scalability when it comes to large and complex data sets, models, pipelines, and infrastructure.
Improved productivity, reliability, and faster deployment of ML models are just a few of the many benefits of adopting MLOps. Implementing the previously mentioned best practices will help organizations unlock and reap the benefits of increased return on investment from ML models.
If you’re looking for an enterprise-level MLOps platform, check out the Domino Enterprise MLOps Platform. It’s the leading MLOps solution that helps many large enterprises like J&J and Lockheed Martin solve the issue of scalability, and accelerates development and deployment by providing ML tools, infrastructure, auditability, and governance—all with integrated security.