
Paco Nathan's latest monthly article covers Sci Foo as well as why data science leaders should rethink hiring and training priorities for their data science teams.
Introduction
Welcome back to our monthly burst of themespotting and conference summaries. In mid-July I got to attend Sci Foo, held at Google X. In this episode I’ll cover themes from Sci Foo and important takeaways that data science teams should be tracking.
First and foremost: there’s substantial overlap between what the scientific community is working toward for scholarly infrastructure and some of the current needs of data governance in industry. Both of those communities are making big strides in their respective tooling, although there is a need for more collaboration. Secondly: some key insights discussed at Sci Foo finally clicked for me—after I’d heard them presented a few times elsewhere. Across the board, organizations struggle with hiring enough data scientists. Meanwhile, many organizations also struggle with “late in the pipeline issues” on model deployment in production and related compliance. There’s been a flurry of tech startups, open source frameworks, enterprise products, etc., aiming at tools for solving problems best characterized as skills gaps and company culture disconnects. Yeah, so there’s like several hundred thousand years of historical examples demonstrating how tools don’t really resolve cultural issues—just saying. In any case, there’s a simpler way to look at these concerns, then rethink hiring and training priorities for data science teams.
But first, let’s backup and discuss: what is this Foo thing anyway? Ever heard of it before?
What’s a Foo?
If you’ve never participated in a Foo event, check out this article by Scott Berkun. People consider the experience intense, unexpected, and life-changing. Having participated in several Foo Camps—and even co-chaired the Ed Foo series in 2016-17— most definitely, a Foo will turn your head around.
Rather than publish an agenda as most technology conferences do, why not let people mingle, discuss, and propose topics and possible sessions? Proposed sessions get stuck onto a wall within an hour or so. Then we’re into the fray with lightning talks, sessions, food, drink, live music, science experiments, long discussions into the wee hours, etc.
Imagine being amongst a bunch of people who are expert in quantum physics, tissue engineering, archeology, birdsong linguistics, climate change, vat-grown beef, CRISPR, building Mars rovers, and so on. Now imagine some of them wanting to carve off an hour to discuss “Is Amazon Destroying Urban Life?” led by people who dig up cities along the ancient Silk Route for a living, getting into debates with people who study network topology or macroeconomics. Just being a fly on the wall is fascinating enough. BTW, that was my favorite session topic this year—looking at the historic patterns of nomads vs. city-builders and considering the global impact of just-in-time delivery via large warehouses.
The first rule of Foo Club Camp is to get involved with sessions where you’re interested in the topic. If it’s not interesting after all, then you wander over to another session. No one gets offended if you stand up and walk out. Serendipity ensues and, as a result, people find themselves in hotly debated topics that aren’t anywhere close to their area of expertise. Yet, often the tangential, adjacent nature of their expertise provides a missing piece to the puzzle. The second rule of Foo Camp concerns a practice called “FrieNDA” where people speak candidly and others respect that without either (1) “Oh gosh I must live tweet stream this amazing insight” or (2) anybody having to sign legal documents.
Sci Foo 2019
Sponsored jointly by O’Reilly Media, Google, and Digital Science, the basic idea of Sci Foo is to pull together 200 or so of the world’s top scientists into an unconference “camp out” for a weekend. Of course, the attendees are “camped out” in posh hotels near Stanford while the infamous buses shuttle between the hotels and Google. Meanwhile, O’Reilly printed a mini guidebook of biographies for everyone attending, which nearly looked like trading cards for scientists. We received copies of the guidebook at the door, which set an expectation that the unconference was about to get interesting—really interesting. Then down the long hallway that led into the Google X auditorium, there were stacks of amazing books written by notable scientists we were going to spend a weekend with in close quarters: talking, eating, debating, ideating, drinking, laughing, exchanging, planning how we collaborate going forward, etc. Latest in quantum physics? Check. Latest in building planetary rovers? Check. Latest in how to grow mini-me brains in a vat? Check. Latest in machine learning research centers rapidly expanding in Africa? Check.
Enroute to a session, I walked through a fascinating talk about solar geoengineering, i.e., terraforming to counter climate change. Nota bene: we’re in for temperature ranges that may very well turn Sacramento into beachfront property within our offsprings’ lifespan. There are some quite strange and intriguing ways to spray aerosols into the stratosphere for mitigating global warming effects. While I was trying to study the detailed slides projected onto a big wall at Google X, some guy in front kept asking disruptive, but apparently well-informed, questions. Eventually I recognized the guy as former California Governor Jerry Brown. Imagine having a campout/meetup where folks like that show up—that’s pretty much a Foo Camp in a nutshell.
The session about Tissue Engineering drove me to Peak Queasiness: the participants had a casual discussion about extracting brain cells via biopsies from cancer patients, then growing brain “organoids” on instrumented substrates. Their approach is to bombard “organoid” mini brains living in vats with potential cancer meds, to measure the meds’ relative effects. Afterward, I headed quietly back to my laptop for some light coding to recover.
Most fascinating moment: got to chat with Theodore Gray, co-founder of Wolfram Research and the inventor of notebooks (back in the 1980s). He’s been out of Wolfram for a while and writing exquisite science books including Elements: A Visual Explanation of Every Known Atom in the Universe and Molecules: The Architecture of Everything. We got to talk at length about Jupyter vis-a-vis their extensive private R&D for using notebooks, which was mind-blowing! It was like discovering an abandoned Soviet research site that had successfully created a low-cost fusion reactor.
Scholarly Infrastructure
Perhaps due to Digital Science being one of the event co-producers or, (more likely) it’s an emerging trend, many attendees mentioned “sci comms” as one of their top professional interests. In other words, science communications. Asking around, it turned out to be an encoding for different meanings: “I support STEM education,” or “I’m a science writer/editor,” or “I support scientific research, which is embattled by the current political environments worldwide” or, in other cases, it was short-hand for collecting metadata about research datasets (provenance, linked data, methods, etc.) then building machine learning models to recommend methods and potential collaborators to scientists. I mention this here because there was a lot of overlap between current industry data governance needs and what the scientific community is working toward for scholarly infrastructure. The gist is, leveraging metadata about research datasets, projects, publications, etc., provides ways to kill 2-3 birds with one stone: better recommendations for people leveraging that data, along with better data governance, along with better ROI on research funding. Do those concerns sound familiar? Data science teams should watch what’s happening here, especially the emphasis in the EU.
For example, meeting Carole Goble was one of the top highlights of Sci Foo 2019 for me. If open source for data governance, metadata handling, workflow management, compliance, dataset recommendation, and so on are interesting for your team, definitely check out the long list of Carole’s projects, including: FAIRdom, Apache Taverna, CWL standard, PAV provenance and versioning ontology, FAIR data guidelines, Galaxy, and so on—all this in addition to being one of the early institutional adopters for Jupyter.
There are big strides being made in the scientific research community enabling open source projects tackle major challenges with handling data. As I’m learning, they don’t share much crossover with similar open source projects that industry data science teams have been building. I’d like to help bridge these two communities and build more collaboration toward common goals. Oddly enough, in the data governance and compliance game, it’s sometimes the scientists who are further ahead than industry, especially in cases where laws don’t allow governance and compliance in research projects to be optional—for good reason.
Sometimes an odd notion
Thanks to Sci Foo conversations, an odd notion that finally clicked. Across the board, organizations struggle with hiring enough data scientists. Meanwhile, many organizations also struggle with issues that are encountered only after machine learning models get deployed in production. Turns out, regulators tend to grapple with the subtle issues of machine learning models deployed in production too–in other words, compliance and other legal issues–which in turn may keep BoD members up late at night. I’ve seen a flurry of projects attempt to provide tech-fixes to people-problems—in other words, treating the symptoms, not the disease. That’s a can-o-worms that exposes problems with Silicon Valley product management culture not entirely comprehending the real-world issues of MLOps. Turns out, there may be a way to help resolve both the hiring and the culture issues in one fell swoop. While I will credit Chris Wiggins and other experts for having patiently described this matter to me, multiple times, it was at Sci Foo that the pieces of that puzzle finally clicked into place, painting a much bigger picture.
Consider the following timeline:
- 2001 - Physics grad students are getting hired in quantity by hedge funds to work on Wall St. (following a breakthrough paper or two, plus changes in market microstructure).
- 2008 - Financial crisis: scientists flee Wall St. to join data science teams, e.g., to support advertising, social networks, gaming, and so on—I hired more than a few.
- 2018 - Global reckoning about data governance, aka “Oops!…We did it again.”
How did that latter train wreck happen? If the field of data science had matured for over a decade, with tens of thousands of super-smart people flooding into highly sought data science roles, how did those kind of data blunders happen en masse? Was it a matter of greed and avarice by tech billionaires, perhaps along with single-minded focus toward revenue growth by any means available? Probably so. But I have a hunch that was not entirely the problem.
Roll the clock out to Sci Foo. I’d been paying careful attention to recent talks by Pete Skomoroch about how product management in the context of machine learning becomes a different kind of responsibility. The probabilistic nature changes the risks and process required. I’d also poured over recent talks by Chris Wiggins about data and ethics. Then I overhead a few remarks during Sci Foo, which recalled similar discussions at JupyterCon last year. Bingo, an idea finally clicked!
Historically, grad students in physics and physical sciences have been excellent candidates for data science teams. A physics student will typically need to collect data, clean the data, run analysis and visualizations, build models, evaluate results… and that’s just prep needed before meeting with their advisor to discuss science. Rinse, lather, repeat—probably each week. Generally, these students must pick up skills using Linux, Jupyter, Docker, Git, various cloud services (or other high-performance computing infrastructure), libraries such as NumPy, SciPy, scikit-learn, and so on. Case in point: one of my favorite tutorials about using Git is inside Effective Computation in Physics: Field Guide to Research with Python by Anthony Scopatz and Kathryn Huff. In many instances, Jupyter stands out in particular, the popular open source tools we use in data science are authored by people with physical science backgrounds, not CS degrees.
Does this description of skills and tooling sound familiar? My formal training was in computer science, and I may have a bias toward that skill set. Even so, in my experience, an engineer with a CS degree probably needs at least a few months of additional training before they can contribute much on a data science team. The tools and processes—and moreover, the mindset—are so different from typical programming work. On the other hand, a physicist can probably get busy in a new data science job on day one because the tools, processes, and mindset are already familiar.
PITAaaS
For the past several years, data science leaders in Silicon Valley have accepted the notion of physicists quickly adapting to data science roles as canon. I’d estimate that at least 50% of the data science teams I’ve built over the years were staffed by people from physical science backgrounds. That’s great for recruiting people who understand the tools and data wrangling techniques and are familiar with building machine learning models. Meanwhile, I’d watched candidates from social science backgrounds face more challenges when it came to getting hired into highly sought data science roles. Something about the latter point bothered me, although I couldn’t quite articulate the particulars.
Recently, we (the data science community in industry) have acknowledged that building machine learning models isn’t the most difficult challenge of working on a data science team. The real fun begins once models get deployed in production. Enterprise concerns regarding security, privacy, ethics, lineage, compliance, and so on, generally come to the fore only after models get deployed. Plus, we’re seeing how these issues surface in regulated environments, which have increasingly become target use cases for the popular open source projects used for data analytics infrastructure: Spark, Jupyter, Kafka, etc. Data governance, for the win!
Another key point: troubleshooting edge cases for models in production—which is often where ethics and data meet, as far as regulators are concerned—requires much more sophistication in statistics than most data science teams tend to have. Try striking up light conversation about “calibrated equalized odds” or “causal inference” at a meetup for product managers. It’s a quick way to clear the room.
To paraphrase Chris Wiggins, ethics in data science comes from the intersection of philosophy and sociology…and philosophy, for its part, Chris describes as “Pain in the Ass as a service” (PITAaaS) since philosophers keep reminding us that life isn’t simple. Repeating mistakes that are known to lead us into trouble, well, tend to lead us into trouble. Putting discussions about security aside, the statistics competency required to confront fairness and bias issues for machine learning models in production set quite a high bar. Check how this point has been reiterated by Stanford Policylab, Google, Microsoft, Accenture, and so on.
That’s when the light bulb flashed on for me. Granted, I’m a bit dense, and even though experts including Chris have patiently explained this point to me at least a few times, it took awhile for the facts to sink in. The delta between the skill sets and mindsets of typical physical science researchers versus typical social science researchers provides the magic decoder ring here. While the former tend to be fluent with data wrangling tools, amazing visualizations, and machine learning models, the latter tend to work with smaller datasets, albeit much more sensitive data, and typically much more stringent compliance and ethics requirements.
Social science research—which produces outcomes such as guiding government policies— tends to use confidential data about people: medical histories, home addresses, family details, gender, sexual practices, mental health issues, police records, details you probably wouldn’t tell anyone else but your therapist, and so on. In lieu of working with big data tools and (publication-worthy) applications of machine learning, social science researchers generally get confronted with data-use authorizations to maintain strict data privacy requirements in addition to strong needs to track lineage and other data governance-ish minutiae. They have to honor all kinds of compliance and ethics standards before they can start performing the science involved (which tends to focus on human behaviors), being concerned about how their actions affect the humans involved in their studies, etc. They tend to use less machine learning, but more advanced statistical practices, since the outcomes (government policies, etc.) will imply lots of consequences and potential disputes unless the evidence is sound.
As an aside to data science leaders and tech-firm product managers: does any of the preceding paragraph resemble your current needs for handling customer issues w.r.t. machine learning? Yeah, I had a hunch those points might ring familiar.
We—a collective “we” pronoun, as in the data science community overall—were busy for the first decade on staffing. We (the leaders) got frantic about hiring enough people onto data science teams, rapidly, to meet corporate objectives. We placed priorities on people who had prior hands-on experience with the tools rather than taking the more expensive and time-consuming route of training new people from a cold start, or focusing on people who understood the issues better than the tools.
Meanwhile, we painted ourselves into a corner. The hard parts of our practice increasingly have become focused on that litany about “all the things” in data governance: security, privacy, lineage, fairness/bias, ethics, compliance—plus, a deeper bench in statistics for troubleshooting edge cases. There’s also the matter of understanding customers as people, rather than modeling millions of customers the same way that we model galaxy clusters. These are outcomes that executives care about, post 2018—ever since what WSJ called a “global reckoning” about data governance.
In other words, while physics students (whom we hired onto data science teams) may have been able to make tools and models do backflips in highly cost-effective ways, social science grad students (who weren’t hired quite as frequently) had already understood issues and practices that became crucial in industry, especially to avoid large risks in business. To wit: data science is a team sport. It’s been interdisciplinary since day one. Diversity matters in data science, and is often the competitive edge for solving complex problems in business. Hire physical science researchers to bolster having people on your data science team who understand the tools. Then hire social science researchers to complement the team; adding staff who understand the issues and the people involved, i.e., your customers.
Putting Insights to Good Use
How does this matter?
First, our accepted notions about “data-driven business” have become increasingly disconnected from what matters in business over the long-term. For example, notions in the industry about privacy versus utility are distorted. Managing machine learning in production turns out to be something that isn’t fixed by engineering. Even so, there’s a different way to look at these problems as a whole, and good ways to address them.
Let’s start with how privacy versus utility is an eternal tension when working with data. In other words, if you can identify a business use case that’s important and has good ROI, there’s probably a workaround for privacy concerns about the data. Sometimes the opposite of that statement is what derails best intentions. In any case, the conventional wisdom is to identify the fields in a dataset that represent personally identifying information (PII)—for example, a customer’s passport number—then “anonymize” those fields. Hashing and crypto methods have become accepted, along with sampling and other approaches for de-identification which get applied before sharing data.
However, this shallow view of privacy and security is far too aristotelian and now becomes a matter of missing the forest for the trees. In case you didn’t see it, a recently published research paper— “Estimating the success of re-identifications in incomplete datasets using generative models” by Luc Rocher, Julien M. Hendrickx, Yves-Alexandre de Montjoye; Nature Communications (2019-07-23)—showed that, even with many allegedly “anonymized” datasets, machine learning models can be used to “re-identify” people described in the data. To dig into details: “generative copula-based method can accurately estimate the likelihood of a specific person to be correctly re-identified, even in a heavily incomplete dataset.” They use ML models to triangulate on people, “predicting individual uniqueness…with low false-discovery rate” to relink to PII. Here’s the punchline: “Using our model, we find that 99.98% of Americans would be correctly re-identified in any dataset using 15 demographic attributes.” Uh-oh.
Granted, I’ve mentioned Chris Wiggins several times in this article, but you seriously need to check out his recent talks along these lines. We face problems—crises—regarding risks involved with data and machine learning in production. Some people are in fact trained to work with these kinds of risks. They handle sensitive data about people, they troubleshoot edge cases using advanced statistics, they apply effective processes for ethical use of data, and so on. These people typically haven’t passed screenings for data science interviews because they aren’t proficient at writing 5000-line Java programs on a whiteboard. Or, they commit the cardinal sin of mentioning fuzzy studies during an interview with a programmer. Or something.
“Nothing Spreads Like Fear”
Once upon a time, circa 2012-ish, data science conferences were replete with talks about an industry hellbent on loading amazing enormous Big Data into some kind of data lake, and applying all kinds of odd astrophysics-ish approaches…for eventual PROFIT! It turns out that wasn’t quite what businesses needed. Modeling hundreds of millions of people as if they were hundreds of millions of stars is a categorical error. Oddly enough, the astronomical bodies won’t initiate a class action lawsuit or an activist-shareholder campaign when you leak their bank account data online in front of Russian troll armies.
An enlightened (read: intellectually aggressive) data science leader should be able to connect the dotted lines here. Want to find a bigger pool of candidates for hiring onto data science teams? Especially people who can help with the later stages of the ML pipelines? Especially at the points where you’re getting into trouble with regulators? Then rethink your hiring strategies w.r.t. what Chris describes.
These are great words. The best words. But, hey, what about a more tangible example? For-instance, where social science research intersects business concerns related to data science practices? I asked around, and this paper came back as an example: “Advancing the Use of Emergency Department Syndromic Surveillance Data, New York City, 2012-2016” by Ramona Lall, Jasmine Abdelnabi, Stephanie Ngai, et al.; Public Health Reports (2017-07-10). Seems obscure and innocuous enough, a thoroughly academic topic, until you read through details in the abstract:
- Surveillance data and bioterrorism concerns – check.
- Crises during Superstorm Sandy – check.
- Ebola-like virus among travelers recently returned to NYC – check.
- Building collapse during storm, involving emergency rooms – check.
- Potential quarantine breaches – check.
- Outpatients as a mobile vector – check.
Concerned Data Scientist: “Um, this is important. There’s a problem here and it’s much more of a priority than our scrum meeting today. There are ethical concerns about that data, about not taking appropriate responses…”
Unconcerned Data Scientist: “That only has hundreds of data points. It’s really not enough to build an interesting model. No big deal.”
Frustrating Product Manager: “The business use case isn’t clear, in particular what’s the anticipated ROI? Have you run any A/B tests yet or written a one-pager describing a Minimum Viable Product?”
Concerned Data Scientist: “WHICH PART OF ZOMBIE APOCALYPSE DID YOU NOT UNDERSTAND!?!”
The Big Picture
In fact, let’s make a picture out of this. The following diagram shows an idealized workflow for projects handled by a data science team. There are some outcomes for the rest of the organization that get supported—such as “executive decisions” and “customer interactions”—and there’s also the support that a data science team receives from the organization which I’ll label generically as a platform of some kind. What kinds of skills are needed, and for which parts of the puzzle?
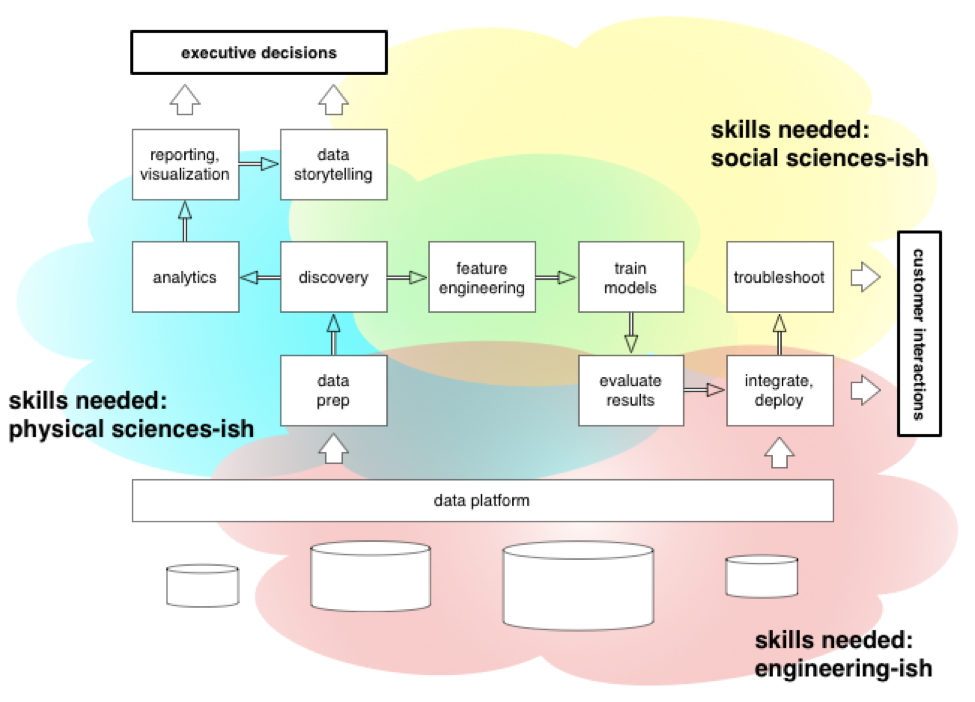
Credit: Paco Nathan
Okay, if this line of thinking piques your interest, what are some recommended resources? Most definitely, the Data Science Community Newsletter out of NYU, by Laura Norén and Brad Stenger. Laura was previously a professor at NYU, researching data science education in the US and Canada using JupyterHub, etc., in other words what works and what doesn’t in particular contexts.
Another resource I highly recommend is Douglas Rushkoff and the TeamHuman.fm project. While on the surface this content may appear relatively luddite, edging toward left-ish themes, Doug’s an expert in technology; he was working early in the days of the interwebs to consider the social impact of using Big Data, machine learning, etc. Rushkoff helped inform people back then about looming disasters (which happened) and how to mitigate them (we ignored him). For an engaging example of his current work, see “Survival of the Richest” (also on this podcast) with billionaires preparing for the end of the world and Doug gets pulled in as a technology consultant. If you take a sample of the people interviewed, looking past some of the obvious political themes, there are some amazing projects and practical suggestions on how to balance technology innovations with the more squishy human concerns.
One of my favorite segments on TeamHuman.fm is with Heather Dewey-Hagborg about an “art project” involving DNA analysis, machine learning, virtual reality, etc., and reconstructing likely faces from DNA leftovers found in NYC subways: chewing gum, cigarette butts, hair, etc. If you haven’t consider the data ethics of making DNA “evidence” admissible in court, this is one interview you shouldn’t miss.
If we could just get a Foo event led by Doug Rushkoff, Chris Wiggins, Laura Norén, and a few dozen other people we’ve covered in this episode—that’d be awesome. Let’s try to avoid a 2018 redux.
Upcoming events
Here are some events related to data science, to mark on your calendars:
- AI SJ, Sep 9-12, San Jose
- Strata NY, Sep 23-26, NYC – check out our panel “Data Science vs. Engineering, does it really have to be this way?”
- Connected Data London, Oct 3-4, London
- AI UK, Oct 14-17, London – check out “Exec Briefing: Unpacking AutoML”
- Tensorflow World, Oct 28-31, San Jose

Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.