
Paco Nathan's latest article features several emerging threads adjacent to model interpretability.
Introduction
Welcome back to our monthly burst of themes and conferences. Several technology conferences all occurred within four fun-filled weeks: Strata SF, Google Next, CMU Summit on US-China Innovation, AI NY, and Strata UK, plus some other events. I’ve been out themespotting and this month’s article features several emerging threads adjacent to the interpretability of machine learning models.
Quick summary: there's a persnickety problem. Software engineering made major breakthroughs two decades ago by applying reductionist techniques to project planning and management. Admittedly, throughout large swaths of computer science, reductionism serves quite well. Approaches involving words such as agile and lean have become familiar due to their successes. They’ve become “embedded institutions” in engineering. Unfortunately, ML applications introduce twists that are not matters for engineering to resolve. Good examples were illustrated by several IT executive talks I’ve seen recently. The same execs who stress needs for ML model interpretability are often the ones who overemphasize the engineering aspects of machine learning, ignoring the social context, in ways that make model interpretability nearly impossible.
In contrast, some researchers who are exploring the definitions, possibilities, and limitations of model interpretation point toward more comprehensive views. For example, common practices for collecting data to build training datasets tend to throw away valuable information along the way.
Why? IMO, the theme here is to shift more of the deeper aspects of inference – such as explainability, auditability, trust, etc. – back to the structure of the dataset.
The lens of reductionism and an overemphasis on engineering becomes an Achilles heel for data science work. Instead, consider a “full stack” tracing from the point of data collection all the way out through inference. Let’s look through some antidotes.
Machine learning model interpretability
At CMU I joined a panel hosted by Zachary Lipton where someone in the audience asked a question about machine learning model interpretation. If you’ve been following Lipton’s work – or if you’d seen my active learning survey talks last year – you can imagine that a lively discussion followed. Lipton wrote one of the early and oft-cited position papers critiquing ML model interpretation: “The Mythos of Model Interpretability.” Other good related papers include:
- “Towards A Rigorous Science of Interpretable Machine Learning”
Finale Doshi-Velez, Been Kim (2017-02-28) ; see also the Domino blog article about TCAV - “Challenges for Transparency”
Adrian Weller (2017-07-29) - “A Survey Of Methods For Explaining Black Box Models”
Riccardo Guidotti, et al. (2018-06-21)
It’s important to note that open source tooling for ML model interpretation has been gaining momentum, with super interesting projects such as Skater, LIME, SHAP, Anchor, TCAV, and so on. Data science teams need to be using these, as part of their process and workflows – and we’ll get to that point later.
Even so, be careful not to regard the interpretability of machine learning models as a robust technological capability. Not yet, if ever. Decision-making is a complicated process and there are oh-so-many issues to consider. Let’s look at two issues, both more social than technical, that bubble to the top of the list. On the one hand, the word interpret itself has different meanings if you are a doctor, a lawyer, or a journalist. There’s no one-size-fits-all definition of what’s required across all verticals. That’s a risk in case, say, legislators – who don’t understand the nuances of machine learning – attempt to define a single meaning of the word interpret. On the other hand, as Lipton emphasized, while the tooling produces interesting visualizations, visualizations do not imply interpretation. The latter is a human quality and quite a slippery one at that. Again, that’s not something to relegate to rules and algorithms.
ML model interpretability and data visualization
From my experiences leading data teams, when a business is facing difficult challenges, data visualizations can help or hurt. A really bad approach is for an analyst to march into a crucial meeting armed with a data visualization and attempt to interpret it for the stakeholders handling a crisis. That’s the corporate equivalent of something not unlike mansplaining. A more effective approach is for an analyst to create a variety of data visualizations for the problem at hand, then let the business stakeholders argue the relevance and meaning for what’s illustrated.

St Paul’s from Madison London
The analogy holds for ML model interpretation, albeit flowing in the opposite direction. Business stakeholders cannot rely on visualizations to interpret the ML models that their data science teams produce. The point being that an ML model is a kind of proxy for the training set features, that are a view of the underlying historical (or synthesized) data, that itself may not be complete or accurate. A visualization of a model’s predictive power adds yet another abstraction layer. Visualizations are vital in data science work, with the caveat that the information that they convey may be 4-5 layers of abstraction away from the actual business process being measured. Information can get quite distorted after being abstracted that many times. Keep in mind that the heatmap is not the territory, so to speak.
Using algorithms to resolve non-algorithmic problems
Overall, looking through the papers listed above, clearly there are no magical solutions for the problem of ML model interpretation. Not yet. While there’s an appeal to populism that ML models should be explainable – which I’ve seen stated in nearly every executive-level slide deck at these conferences – we should not look toward technology fixes, nor attempt to legislate them. As long as the research community is struggling with even basic definitions, it’s unlikely that regulators will have consistent ways to measure ML interpretability, let alone “enforce” its use. Businesses would be wise to adapt their views as well.
In other words, don’t try to use algorithms to resolve the non-algorithmic problems experienced through the use of algorithms. Bokay?
Not a purely computational problem
Meanwhile let’s cutover to a recent interview by Ben Lorica with Forough Poursabzi Sangdeh, “It’s time for data scientists to collaborate with researchers in other disciplines,” on The O’Reilly Data Show Podcast:
Many current machine learning applications augment humans, and thus Poursabzi believes it’s important for data scientists to work closely with researchers in other disciplines.
Truer words were seldom spoken. For example, in the critical domains where algorithmic decision-making gets used, they are almost always instances of ML models plus people working toward decisions together:
- Who gets approved for a loan?
- Who gets released on probation?
- Who gets hired for a job?
Check out the podcast interview for more details. After initial research in this field, Poursabzi grew puzzled by the notion of the interpretability of machine learning models. Clearly there’s a technology component to ML; however, there’s also a human computer interface (HCI) component. It’s not a purely computational problem.
ML interpretability: unpacking conflicting priorities

Keynotes at Strata UK. Image Credit.
Back to the interview between Ben Lorica and Forough Poursabzi, practically any discussion of interpretability in machine learning will entangle a list of conflicting priorities:
- explainability
- trust
- intelligibility
- transparency
- auditability
It goes without saying how that’s a loaded argument and needs to be unpacked.
The word interpret itself has a connotation that one should be able to describe the internals of a system in a way that’s understandable for humans. A subtext often accompanies: any solution should have enough completeness that it applies in the general case, i.e., beyond the training data – or else it won’t really make sense as a solution. Explainability pushes a tension between those two points: do you want your ML model explanation served simple or complete? Generally, you cannot get both. For example, in the case of more recent deep learning work, a complete explanation might be possible: it might also entail an incomprehensible number of parameters.
Given how so much of IT gets driven by concerns about risks and costs, in practice auditability tops the list for many business stakeholders. However, in a more long-term view about ML models deployed in production, intelligibility represents a realistic priority for risks and costs: considerations for tech debt, the ability to detect mistakes, troubleshooting, and so on. Another crucial factor to take into account: how experienced are the users who are involved in the task that’s being augmented by automation?
Some of these priorities are properties of model and system design, while others are properties of human behavior. Poursabzi stresses an excellent point about the questions of trust, auditability, etc.:
If you don’t think about them in terms of human in the loop, they’re impossible to answer.
Here’s where she cuts to a core observation about the practice of machine learning that I rarely find mentioned in academia, and almost never in industry. If you invest enough time into modeling, you can often find relatively simple models for a given problem. Let’s unpack that one: it’s quite important. So much work in machine learning – either on the academic side which is focused on publishing papers or the industry side which is focused on ROI – tends to emphasize:
- How much predictive power (precision, recall) does the model have?
- Does it beat existing benchmarks, i.e., is it SOTA?
- How fast can the model be trained?
- How fast can it infer results?
- What did it cost to train?
- What does it cost to run?
- How easy would it be for nonexperts to train the model? (AutoML)
In a rush to gain predictive power rapidly – that is, less expensively – the results will tend toward more complex ML models. If your “performance” metrics are focused on predictive power, then you’ll probably end up with more complex models, and consequently less interpretable ones. The trade-off is whether or not data science teams invest the time to iterate beyond mere predictive power, to reach simpler models that are as effective, and that also have better auditability, intelligibility, etc.
Then again, when you emphasize completeness, you get explanations that may be thorough but tend to be more difficult for humans to understand. Ergo, less interpretable.
The process and priorities your data science team follows will imply potential risks to ML model interpretability.
ML model interpretability: context of intended use
Another one of the key takeaways from Poursabzi is that ML model interpretability should be studied in the context of its intended use. In other words, have there been any human-subject experiments to evaluate the models?
That’s not especially good news for data science teams pressured by management to be “agile” and crank out lots of models rapidly. Instead, teams should take sufficient time to:
- build simpler models that retain predictive power while being more understandable
- evaluate the effects of models on human subjects
- measure the subjects’ ability to trust the models’ results
Those kinds of efforts are difficult or impossible to automate. They also require advanced skills in statistics, experimental design, causal inference, and so on – more than most data science teams will have. FWIW, the social sciences tend to teach those skills much more than computer science. Keep in mind that data science is fundamentally interdisciplinary. Perhaps this point illustrates a need to broaden the curriculum and training for data science practitioners, raising the bar?
“Agile” makes almost no sense in a social context
As mentioned, it’s important for data science teams to be using whatever tools are available for interpreting the models they produce. That approach creates feedback loops so that the people building models can learn insights from their results. Could feature engineering be improved? Going back a step earlier, could the data be enhanced? Do the model results fit the context for the customer? Have there been any human-subject experiments?
Here’s where I get baffled by people who use words such as agile or lean to describe process for data science. Agile was originally about iterating fast on a code base and its unit tests, then getting results in front of stakeholders. Investing time to find simpler models that are easier to troubleshoot is not a particularly Agile approach.
Perhaps if machine learning were solely being used to optimize advertising or ecommerce, then Agile-ish notions could serve well enough. Being solely a mechanized matter of “training data creates model, evaluated on testing data,” perhaps it could be translated into purely engineering terms. That may have been the case a decade ago, but those days are long gone. Machine learning gets used for driving buses (at airports in EU now), coordinating operations within hospitals, parole boards, loan applications, developing pharmaceuticals, and other areas where decisions based on software engineering methodology alone are recipes for disaster – and lawsuits.
Digging into this, the notion of writing “unit tests” for a machine learning problem is a fallacy; however, that’s what test-driven development and other Agile-ish approaches require. Instead, teams must invest substantial time working with the training data, working through a variety of models, evaluating with live customer data, and so on. Rushing toward a minimum viable product will tend to produce models that are more complex and less explainable. Creating less explainable models that are more difficult to troubleshoot doesn’t serve the stakeholders’ needs and is decidedly not Agile.
ML: social systems and context

Strata chair Ben Lorica, coordinating backstage.
Backstage at Strata UK, I got to chat briefly with James Burke just before he walked on stage to present one of the most fascinating keynote talks I’ve ever attended. He talked about the risks of reductionism and Descartes’ questionable legacy. About the end of scarcity being the driving motivation for economics, political discourse, education, etc. About how monumental shifts in technology almost always come from unanticipated uses. About how the problems that we need to be wrangling now are the embedded institutions that prevent us from recognizing enormous advances available right under our noses.
There’s a joke going around the interwebs, attributed to Mat Velloso:
If it is written in Python, it’s probably machine learning. If it is written in PowerPoint, it’s probably AI.
Poursabzi and a growing list of researchers point toward more useful definitions than that AI/PowerPoint joke circulating on Twitter:
- ML is about using tools and technology
- AI is about changing social systems
Developing AI is no longer merely about engineering process, nor is it about PowerPoint jokes. It’s increasingly quite a serious matter about social systems and context. The embedded institutions of our day, with respect to AI, are: Agile-ish notions, overemphasis of engineering approaches, populist appeals for interpretation of machine learning, and so on.
The crucial aspects of AI that we must incorporate from social systems go beyond reductionist perspectives of machine learning. Full disclosure: that’s why I believe use of the title machine learning engineer is a signifier for a legacy organization, and that ultimately both Amazon and Google may fall from grace, at least for their current approach to marketing cloud-based AI services. But I digress.
Moving beyond the blinders of embedded institutions, IMO the social systems work in AI will become the primary focus for the next generation of product management. As the O’Reilly surveys and other recent reports have demonstrated, the state of “Product Management for AI” is still barely even evolved to a primordial soup stage. Pete Skomoroch gave an excellent talk at Strata UK, outlining the shape of product management required in the context of AI, and here are his slides. I have a hunch this is still a wee bit reductionist and lacking the social systems aspects – although perhaps that helps reach a broader audience based on their current thinking? Overall, directionally, it’s pretty cool.
What just kills me is how many of the same execs who call for ML model interpretability are often the ones who overemphasize engineering and Agile-ish notions, in a synecdoche of the problem/resolution entanglement. Not entirely unlike the Cornish mining execs whom Burke used as an illustration in his keynote: struggling with economic woes, driving their staff quite literally to death, hellbent to extract every last bit of tin ore, even in the face of diminishing returns – while in fact their people had innovated on the Watt steam engine design, creating a high pressure variant.
Decades from now, the James Burke of that time may guide audiences through a hilarious “Connections” tour of circa 2020 thinking about “Agile AI” – back when people were employed to write software – how a backwards industry of the time called “IT” had missed the point entirely, shortly before crumbling into obscurity.
There’s an interesting narrative arc on the Google research blog between the 2009 paper “The Unreasonable Effectiveness of Data” and the 2017 update “Revisiting the Unreasonable Effectiveness of Data.” I suggest comparing the two, with the caveat that the latter focuses on computer vision. Going back to execs’ slide decks, the former paper gets misquoted. Having more data is generally better; however, there are subtle nuances. There’s probably more than a little confirmation bias that Big Data volume must somehow be an intrinsic virtue – otherwise why bother with all that data engineering cost to store it?
One of the emerging threads adjacent to ML model interpretability suggests that data science teams might want to rethink how their training datasets get built. Or at least look more closely at that process for interpretation, rather than relying on post-hoc explanations of models that have been built from the data.
A good first stop on this part of the tour is the 2017 work “Understanding Black-box Predictions via Influence Functions” by Pang Wei Koh and Percy Liang at Stanford. Use of influence functions goes back to the 1970s in robust statistics. Koh and Liang applied this approach in machine learning to trace model predictions through the learning algorithm and back to the training data. This can be used for detecting and repairing dataset errors, understanding model behavior, troubleshooting, and creating training-set attacks.

Robotic bartenders mixing my Negroni cocktail at Strata UK.
We got two fascinating and super helpful updates along those lines from Bay Area researchers at AI NY. Stanford professor Chris Ré presented “Software 2.0 and Snorkel” about weak supervision. To paraphrase, Ré had observed that in many cases there are ad hoc forms of programmatic labelling used to build training datasets. These create structure within the source data, albeit in isolated ways. Snorkel formalizes those ad hoc approaches to leverage the supervision that’s going into the datasets – the key ingredient for supervised learning:
Big theme: use organizational knowledge resources to quickly and effectively supervise modern ML.
That helps create good training data more quickly, helps for managing the data over time, but also helps for building better quality ML models:
There’s a fair amount of power in just knowing the source of every single label.
I’ll let you connect the dots for the impact that has on model interpretation. Hint: consider the phrase model lineage, and recognize that not all rows within a training dataset are equally valuable. This edges toward core issues in model governance. Consider that probabilistic methods for programmatic labeling retain more information through all the levels of abstraction from business process up through training data, modeling, inference, and eventually the resulting explanations. Burke used conference attendance to illustrate how information implies change, and to paraphrase: “Telling you that you’re attending a conference does not convey any information. You already knew that. However, stating that the person seated next to you has a communicable disease, that implies change.” That, roughly speaking, is what Ré is describing here.
Let’s try to illustrate this in a diagram. Think of the following diagram as “stack” where the in-between words in italics (e.g., “data collection”) show the “process” steps that a team performs, while the boxes (e.g., “training data”) show the tangible outcomes. Ostensibly the business is operating and getting measured – at the base of the diagram – as the most tangible layer. Abstracted a level above that you’ve got your data. Abstracted a level above that you’ve got a training dataset. So on and so forth. Approximations, distortions, variance, and other troublesome artifacts tend to get introduced at nearly every level, which destroys information. If your goal is to have some kind of explainable inference as the end result, you must consider those artifacts all along the way. The current generation of tools for ML model interpretability tends to pick up at the “ML model” stage, ignoring the other steps needed to arrive at that point – that’s part of the criticism by Zachary Lipton, Forough Poursabzi, et al. It’s reductionism taken to an extreme. Chris Ré argues that you can have better formalisms all the way back through data collection, to preserve structure and information for when you reach hard problems at the “explanations” stages – instead of throwing it away. That seems much more robust.
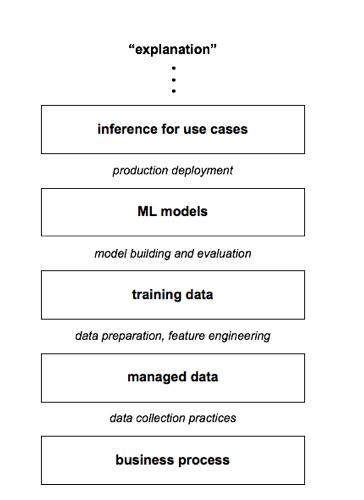
Pushing this notion further, UC Santa Cruz professor Lise Getoor presented “The unreasonable effectiveness of structure” – with a play on words from one of the Google papers cited above. Here’s a video of an earlier version of her talk at NeurIPS 2017, and her related slides from ScaledML.
Probabilistic soft logic (PSL) is a machine learning framework for developing probabilistic models. PSL models are easy to use and fast. You can define models using a straightforward logical syntax and solve them with fast convex optimization. PSL has produced state-of-the-art results in many areas spanning natural language processing, social-network analysis, knowledge graphs, recommender systems, and computational biology.
Granted this PSL work has been brewing for ~9 years, and the emphasis is about building explainable knowledge graphs from your data. Even so, if you haven’t seen this before then run, do not walk, to check out the code for Probabilistic Soft Logic:
IMO, the theme here is to shift more of the deeper aspects of inference – such as explainability, auditability, trust, etc. – back to the structure of the dataset. Of course, people have often used Bayesian networks to construct probabilistic graphs to explain inferences, with mixed results. PSL is quite different and I’m eager to leverage it in some current applications. Again, it’s fast.
Product Management for AI
Obviously, I have concerns about vendors who attempt to push the narrative that there are engineering solutions to almost all problems related to AI. Process goes to measurement which goes to data collection which goes to training and testing models which goes to inference. Done and done, in such a thoroughly linear, aristotelian manner that it’d probably make Descartes blush. Agile to the core. Not to mention any names, per se, but we’ve seen the conundrums that result. That is not AI. That’s reductionism applied to machine learning tools.
Other organizations use ML models to help aggregate examples within the data – focusing the collaborative decision-making lens toward important indications – but then let the customers decide based on examples within the data, not “results” from ML models. I believe that’s a more resilient approach. Primer AI is a good example, and for full disclosure I’m an advisor there. That subtle nuance allows teams to blend the results of advanced ML into their social systems for leveraging information (as Burke described) and making judgements. Probably not what you need to optimize a gazillion ad placements, but then again I believe that most business models based on ad placements are pretty much toast at this point. AI offers paths forward for far more important matters that need to be resolved.
I have a hunch this will become the basis of “Product Management for AI” – and if you’ve been listening to me over the past 2-3 years, yeah that’s the problem. Not the lack of “Agile AI” process.
Misc items, too good to miss
Also, here are four links to recent items that are not tightly woven into our themespotting here, but nonetheless too good to miss:
- “A Recipe for Training Neural Networks” by Andrej Karpathy (2019-04-25)
- “Jupyter Book: Interactive books running in the cloud” by Chris Holdgraf (2019-03-27)
- “Women in Open Source” by Debra Williams Cauley and Melissa Ferrari (2019-04-18)
- “The coming privacy crisis on the Internet of Things” by Alasdair Allan (2017-10-09) – and related talk at Strata UK 2019
- SparkFun channel on YouTube, featuring Pete Warden and other low-power ML luminaries
Upcoming events
Data-related events to mark on your calendars:
- Jupyter Community Workshop, May 16-17 in Paris
- AKBC, May 20-22 in Amherst
- Rev, May 23-24 in NYC – see you there!
- Petaluma Salon, Jun 5 – I’ll be hosting an AI-themed book review about John Barr, “Are Facebook and China scrambling to become each other?”
- OSCON, Jul 15-18 in Portland: CFP is open for the “AI Ops: Development meets Data Science” track which I’ll be hosting on Jul 16

Summary
- Introduction
- Machine learning model interpretability
- ML model interpretability and data visualization
- Using algorithms to resolve non-algorithmic problems
- Not a purely computational problem
- ML interpretability: unpacking conflicting priorities
- ML model interpretability: context of intended use
- “Agile” makes almost no sense in a social context
- ML: social systems and context
- Product Management for AI
- Misc items, too good to miss
- Upcoming events
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.