Efficient and scalable GPU model inference on Domino with NVIDIA Triton inference framework
Author
Sameer Wadkar
Principal Solution Architect
Article topics
MLOps, LLMOps, LLM serving, Cost efficient GPU usage
Intended audience
Domino Administrators, Data Scientists
Overview and goals
GPUs are expensive, especially for inference workloads. Unlike training jobs that run and terminate, inference endpoints are always on. If your stack depends on GPUs, you're locking them up and paying for them 24/7, even during periods of low traffic. Whether you're using reserved cloud instances or managing on-premises hardware, high GPU utilization is non-negotiable.
Here are two proven strategies to optimize GPU usage for inference:
1. Slice the GPU with NVIDIA MIG (best when the number of models is small)
MIG (Multi-Instance GPU) partitions a single GPU into isolated slices — each with its own memory, compute, and cache.
- Ideal when the number of persistent model endpoints is less than or equal to the number of available slices
- Simple to configure and effective for predictable, low-latency workloads
2. Use NVIDIA Triton for dynamic, multi-model inference (best when serving more models than you have GPUs or MIG slices). When you're serving many models (CV, NLP, small LLMs) with variable traffic patterns and SLA requirements, Triton inference server excels at:
- On-demand model loading and unloading
- Concurrent model serving on GPU and CPU
- Policy-based control (e.g., always-loaded, lazy-load, GPU/CPU affinity)
Triton lets you serve more models than you have GPUs or GPU slices. Only active models consume GPU memory; others stay dormant until invoked. This makes Triton ideal for organizations with a large model zoo and sporadic or unpredictable workloads.
Domino supports MIG out of the box. Follow instructions from NVIDIA to configure MIG and configure Domino Hardware (HW) Tier to use MIG and you are all set. When setting up a Domino Model Endpoint, instead of selecting an HW tier with a full GPU, select the one that supports MIG and utilize an appropriate MIG slice. This improves the utilization of a GPU by allowing multiple model endpoints to use it.
The topic of this article is how we can use the NVIDIA Triton framework to maximize the utilization of GPU for inference. While this discussion focuses on efficient GPU utilization, it is equally valid for efficient CPU utilization when using the Triton inference framework.
When should you consider using this approach?
- You have several models that need GPUs for efficiently computing inference. You cannot use MIG because the number of models exceeds the number of MIG slices
- Your models are invoked intermittently and do not have a high throughput requirement
- Your models are not all GenAI models but include Computer Vision and Natural Language Processing models
- You need to maximize GPU efficiency to curb always-on GPU billing without degrading SLAs
Why does the inference engine approach help achieve the above goals?
We will leverage the same approach as we used for LLMOps previously. Two categories namely “data scientists” and “production deployers” will have access to designated development and production Domino Datasets. But instead of sharing the datasets with the model endpoints, these will be shared by the inference servers.
The system allows for multiple Triton inference servers to be plugged in. In other words, we provide a pluggable architecture to plugin in multiple Triton inference servers each with their own serving SLA’s as well as model loading/unloading policies.
The model endpoint will only serve as a proxy to the inference server. We will use NVIDIA Triton as our inference server. However, the pluggable design allows you to deploy any inference server of your choice. In a future article, we will expand on this to demonstrate how to use this design to plugin the NVIDIA Dynamo inference server for serving LLMs efficiently in a context sensitive manner.
What makes the Triton-based inference server approach so efficient for GPU usage is:
- Triton allows you to load multiple models in the GPU (assuming sufficient GPU memory) without slicing the GPU.
- Triton allows you to dynamically load/unload models from the underlying GPU (or CPU) memory. If your model usage is intermittent, this allows you to unload models not being used to load models actively requested. Consequently, you can serve a significantly higher number of models than your compute would allow if models were in an “always loaded” state.
The motivation for this article is to enable an efficient use of GPUs. But this discussion is not limited to GPUs. For example, imagine a model that is served on four cores and can support four threads. This model will use 16 cores. Now add 4 GB per core, and you are looking at 64 GB of CPU memory. If such a model were also invoked intermittently but has a high throughput requirement at a specific time of the day, say a nightly batch process, it makes sense to share the compute with other models that are used during regular business hours. Especially if this model may also be intermittently used during regular business hours.
The end goal of using the Triton inference server is to efficiently use compute for model inference. Another strong capability of the Triton inference server is its ability to serve models in multiple formats (multiple inference engines). The list of engines supported by Triton is:
- TensorFlow (tensorflow) – Supports both TensorFlow SavedModel and GraphDef formats.
- ONNX Runtime (onnxruntime) – For ONNX models.
- PyTorch (pytorch) – Supports TorchScript serialized models.
- TensorRT (tensorrt) – Optimized for NVIDIA GPUs, supports TensorRT engine plans.
- Python (python) – For custom Python-based models using Python backend.
- OpenVINO (openvino) – Supports Intel’s OpenVINO-optimized models.
- FIL (fil) – Forest Inference Library backend for tree-based models like XGBoost, LightGBM, etc.
- Ensemble (ensemble) – Allows chaining multiple models/pipelines across backends.
- JAX (jax) – For models using JAX.
- DALI (dali) – For pre-processing pipelines using NVIDIA DALI.
- Backend for custom frameworks – You can write and register your own backend.
Not all backends support both GPU and CPU. Most optimized inference is achieved through TensorRT or ONNX Runtime on a GPU. Delegating inference to an inference server such as Triton, centralizes the deployment of models to a single entity (albeit a distributed and horizontally scalable one). This simplifies the Domino Model Endpoints, which now only serve as a proxy and hence have a simplified underlying environment and use a tiny hardware tier (usually 0.2 cores and 0.2 GB is adequate).
Another important idea to bear in mind is that using MIG and Triton inference server is not a mutually exclusive decision. A single Triton inference server can support multiple GPUs. You can certainly allocate multiple MIG slices (of different sizes even) to a Triton inference server. And you can allocate models to different slices and have different policies per slice. For example, certain models could be pinned forever to a MIG slice while others on other slices are loaded and unloaded on demand. Triton allows you to apply custom policies on how models are managed per GPU enabling efficient use of GPU compute.
How to deploy LLMs as endpoints in Domino
As discussed in the previous article we can take advantage of the Triton inference server without compromising on the ability for Domino to act as a System of Record. First let us focus on the underlying design of the inference server deployment. In this reference implementation we only support two types of inference servers:
- One Triton inference server pre-loads all models at startup.
- Another Triton inference server loads/unloads models on demand. In this mechanism, when a request arrives for a deployed model, the server verifies that the model is loaded. If loaded it applies the inference. If not, it determines which is the last used model to evict. If it finds a model that is not used for more than 5 mins, it evicts the model. If no such model exists, it sends a response to the client that the server is busy and to try again later.
The inference server framework is deployed in its own Kubernetes namespace. This allows for multiple instances of the framework to be deployed. In our reference implementation we have a development instance deployed to a development namespace and a production instance deployed to a production namespace.
If you are using Domino Nexus with development and production data planes, you could have a namespace with the same name in each data plane. One would be used for development by data scientists, and the other would be used for production and invoked by model endpoints deployed in the production data plane.
Each instance of the inference framework has the following components deployed in its dedicated namespace:
- Domino Inference Server Proxy - This is a horizontally scalable FastAPI based proxy server that all clients interact with.
- One or more Triton inference servers - These components will host the actual models from the Domino Model Registry. Any interaction with the inference servers is only via the Domino Inference Server Proxy.
This design allows us to enforce access control policies in the Domino Inference Server Proxy.

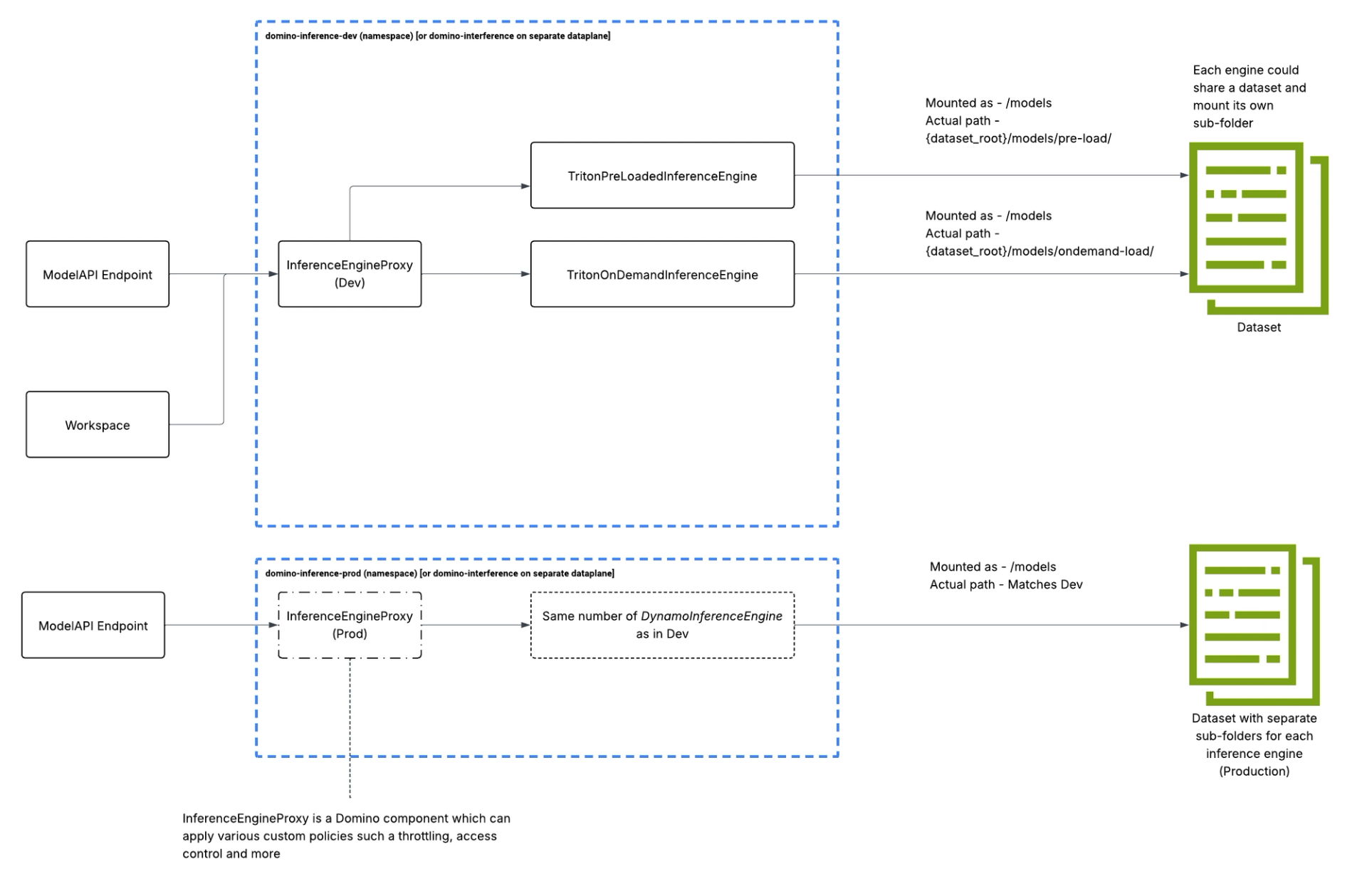
This is the essence of this design. The Triton inference server simply relies on the content of the folder "/models". There are essentially two ways to start the server depending on if you want to auto-load the models in the folder (which we call pre-loading) or if you want to load them on-demand and explicitly control the loading unloading of the models based on the incoming demand.
Type of Triton inference server loading
Command to start the inference server
Autoload (or pre-load). In this case if models are added/removed from the “/models” folder, they will be loaded/unloaded respectively in the next 30 second polling interval.
args: [
"tritonserver",
"--model-repository=/models",
"--model-control-mode=poll",
"--repository-poll-secs=30",
"--log-verbose=1"
]
Ondemand loading
args: [
"tritonserver",
"--model-repository=/models",
"--model-control-mode=explicit",
"--log-verbose=1"
]
Triton folder structure for model deployment
In the earlier section, we started the Triton inference servers with the models location as “/models”. Triton expects a specific structure for the models.
/models/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
[configs]/
[<custom-config-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
[configs]/
[<custom-config-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
...
The act of deploying a model to Triton simply involves getting this folder structure right. The recommended approach in Domino is to have a folder structure as:
/models/
<registered-model-name-from-model-registry>/
[config.pbtxt]
[<output-labels-file> ...]
[configs]/
[<custom-config-file> ...]
<registered-model-version>/
<model-definition-file>
<registered-model-version>/
<model-definition-file>Using Domino as the system of record
As described in the earlier article on deploying LLMs as Domino Model Endpoints, you cannot store the model binaries in the run associated with the registered model version. This causes the explosion in the size of the model image and is both operationally and cost inefficient.
Instead, you can use nested MLflow runs. We register an empty mlflow.pyfunc.PythonModel model [https://mlflow.org/docs/latest/api_reference/python_api/mlflow.pyfunc.html] for the parent run, where we log the model binaries as artifacts and register a model version. The model binaries are copied to the development Triton inference server folder using this model name and model version.
Once you have this model name and model version, start a child run and create the actual mlflow.pyfunc.PythonModel model you wish to use to make inferences. This second model has all the information it needs to invoke the Triton inference server in its registered model context:
- The Triton inference server name
- The registered model name [of the first empty model]
- The registered model version [of the first empty model]
The invocation of the Triton inference server needs awareness of the Domino Inference Server Proxy endpoint. This is configured in the Domino Model Endpoint as an environment variable [DOMINO_INFERENCE_PROXY]. The model developer configures the endpoint to the development Domino Inference Server Proxy and tests the endpoint by passing the model payload.
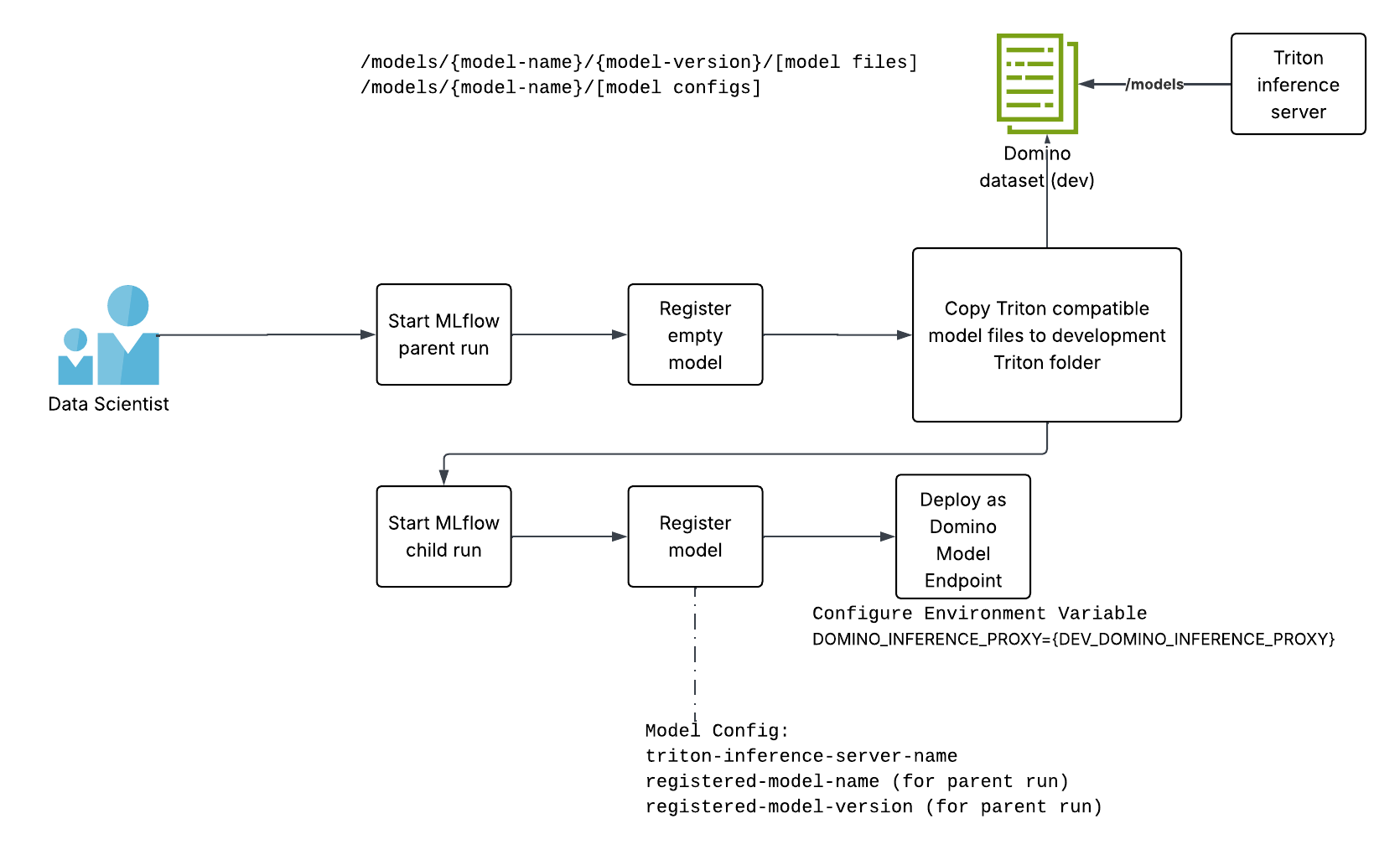
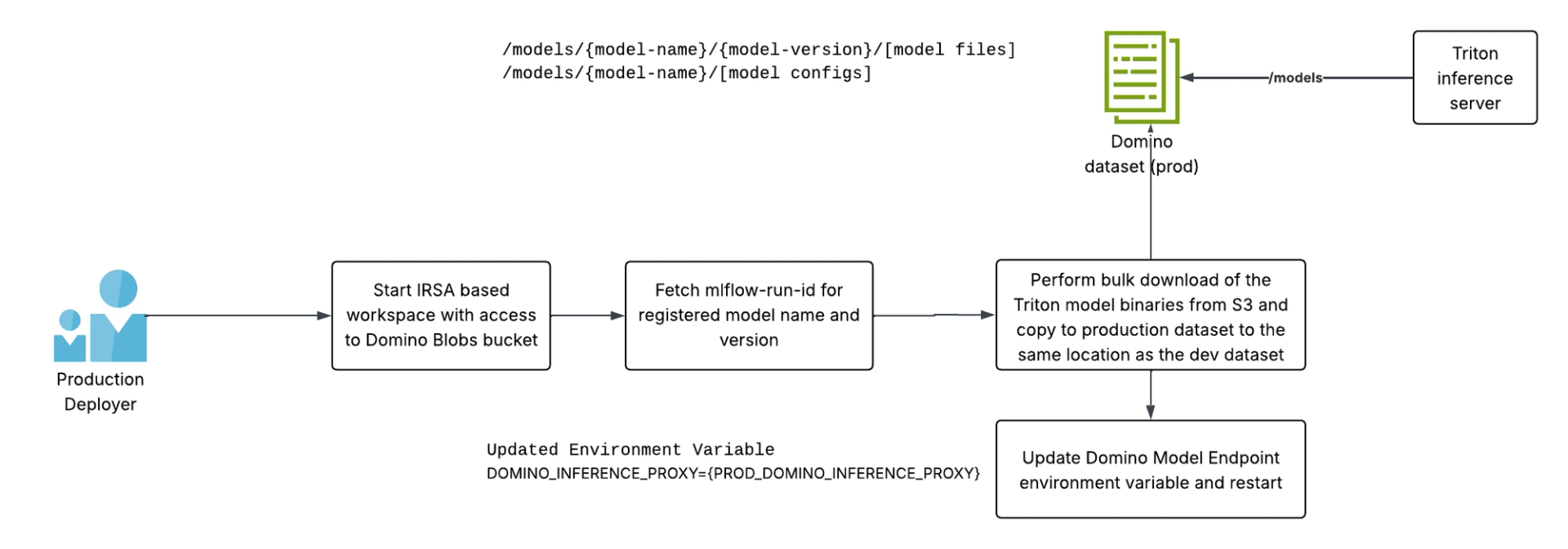
Once satisfied, the model developer asks the Domino user in the designated production deployer to deploy this model. This step requires the prod deployer to create the same folder structure in the production Triton inference server (a separate Domino dataset to which the model developers do not have access). The steps the production deployer will follow are similar to the ones mentioned in the previous article, where LLMs were deployed to Domino endpoints:
- Use the registered model name and model version to fetch the mlflow-run-id
- Use S3 bulk download (from an IRSA configured workspace) to download the model binaries and configurations
- Copy those model files into an identical folder structure in the production dataset (aka production Triton inference server)
Restart the model endpoint after changing the [DOMINO_INFERENCE_PROXY] to point to the production instance of the inference server proxy endpoint
And now all requests for model inference will strike the production Triton inference server.
How to achieve cost savings with this design
Let us reiterate what is so compelling about this design. Triton allows you to load multiple models into the memory (CPU or GPU, depending on what is being used) of the compute being used for model serving.
The Domino Model Endpoints are now mere proxies to the actual endpoints hosted in Triton inference servers. For models using expensive compute (GPU or large number of CPU’s for short bursts) it allows us to share these expensive compute nodes across multiple endpoints.
Compare that with the default where you have dedicated compute resources for each Domino endpoint. Endpoints are always running. Endpoints that are idle for large amounts of time, end up being wasteful from a cost perspective. This approach allows you to maximize the use of your compute nodes for model inference.
How to make scaling decisions for Triton inference servers
A Triton inference server will host models. For the sake of this discussion, let us only focus on the server whose loading policy is to pre-load all models in memory (GPU or CPU, depending on the model configuration). For the server that allows models to be loaded and unloaded on demand, the same discussion applies with minor modifications.
There are two types of scaling:
- Horizontal scaling - We scale out if we need to load balance a model invocations to multiple GPUs or multiple GPU partitions. When GPU memory usage is moderate but GPU compute utilization approaches saturation, add more GPUs. This will cause Triton to load multiple model instances across available GPUs, enabling concurrent inference and distributing the load.
- Vertical scaling - Vertical scaling is needed when a model needs more GPU resources (GPU memory) to execute. If GPU memory is saturated but compute utilization is moderate, you should upgrade to a GPU with more memory or assign the model to a larger MIG partition. Alternatively, you can add additional GPUs and redistribute model instances across the expanded pool.
Check out the GitHub repo


Sameer Wadkar
Principal solution architect

I work closely with enterprise customers to deeply understand their environments and enable successful adoption of the Domino platform. I've designed and delivered solutions that address real-world challenges, with several becoming part of the core product. My focus is on scalable infrastructure for LLM inference, distributed training, and secure cloud-to-edge deployments, bridging advanced machine learning with operational needs.