Machine Learning Projects: Challenges and Best Practices




This blog post provides insights into why machine learning teams have challenges with managing machine learning projects. He also provides best practices on how to address these challenges. This post was provided courtesy of Lukas and originally appeared on Medium.
Why are Machine Learning Projects so Hard to Manage?
I’ve watched lots of companies attempt to deploy machine learning — some succeed wildly and some fail spectacularly. One constant is that machine learning teams have a hard time setting goals and setting expectations. Why is this?
It’s really hard to tell in advance what’s hard and what’s easy.
Is it harder to beat Kasparov at chess or pick up and physically move the chess pieces? Computers beat the world champion chess player over twenty years ago, but reliably grasping and lifting objects is still an unsolved research problem. Humans are not good at evaluating what will be hard for AI and what will be easy. Even within a domain, performance can vary wildly. What’s good accuracy for predicting sentiment? On movie reviews, there is a lot of text and writers tend to be fairly clear about what they think and these days 90–95% accuracy is expected. On Twitter, two humans might only agree on the sentiment of a tweet 80% of the time. It might be possible to get 95% accuracy on the sentiment of tweets about certain airlines by just always predicting that the sentiment is going to be negative.
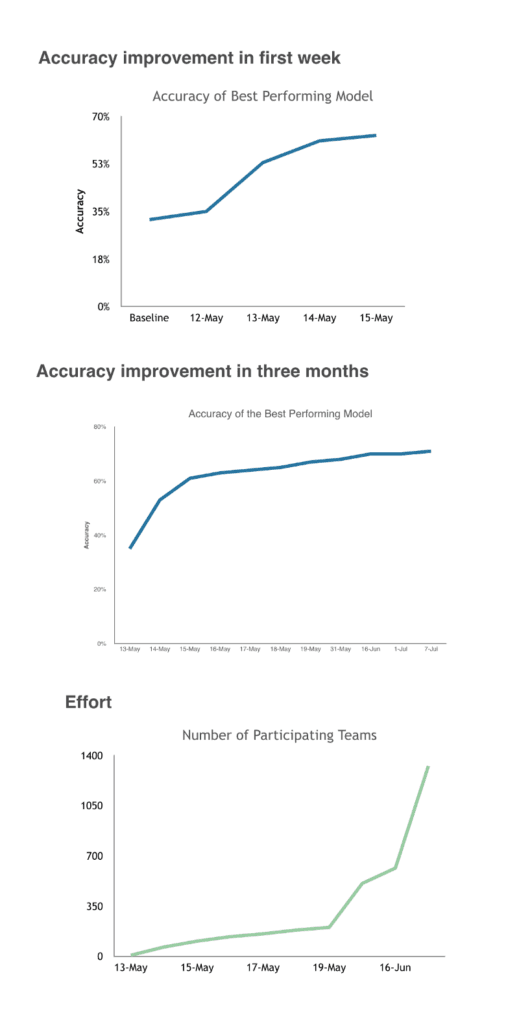
Metrics can also increase a lot in the early days of a project and then suddenly hit a wall. I once ran a Kaggle competition where thousands of people competed around the world to model my data. In the first week, the accuracy went from 35% to 65% percent but then over the next several months it never got above 68%. 68% accuracy was clearly the limit on the data with the best most up-to-date machine learning techniques. Those people competing in the Kaggle competition worked incredibly hard to get that 68% accuracy and I’m sure felt like it was a huge achievement. But for most use cases, 65% vs 68% is totally indistinguishable. If that had been an internal project, I would have definitely been disappointed by the outcome.
My friend Pete Skomoroch was recently telling me how frustrating it was to do engineering standups as a data scientist working on machine learning. Engineering projects generally move forward, but machine learning projects can completely stall. It’s possible, even common, for a week spent on modeling data to result in no improvement whatsoever.
Machine Learning is prone to fail in unexpected ways
Machine learning generally works well as long as you have lots of training data and the data you’re running on in production looks a lot like your training data. Humans are so good at generalizing from training data that we have terrible intuitions about this. I built a little robot with a camera and a vision model trained on the millions of images of ImageNet which were taken off the web. I preprocessed the images on my robot camera to look like the images from the web but the accuracy was much worse than I expected. Why? Images off the web tend to frame the object in question. My robot wouldn’t necessarily look right at an object in the same way a human photographer would. Humans likely not even notice the difference but modern deep learning networks suffered a lot. There are ways to deal with this phenomenon, but I only noticed it because the degradation in performance was so jarring that I spent a lot of time debugging it.
Much more pernicious are the subtle differences that lead to degraded performance that are hard to spot. Language models trained on the New York Times don’t generalize well to social media texts. We might expect that. But apparently, models trained on text from 2017 experience degraded performance on text written in 2018. Upstream distributions shift over time in lots of ways. Fraud models break down completely as adversaries adapt to what the model is doing.
Machine Learning requires lots and lots of relevant training data
Everyone knows this and yet it’s such a huge barrier. Computer vision can do amazing things, provided you are able to collect and label a massive amount of training data. For some use cases, the data is a free byproduct of some business process. This is where machine learning tends to work really well. For many other use cases, training data is incredibly expensive and challenging to collect. A lot of medical use cases seem perfect for machine learning — crucial decisions with lots of weak signals and clear outcomes — but the data is locked up due to important privacy issues or not collected consistently in the first place.
Many companies don’t know where to start in investing in collecting training data. It’s a significant effort and it’s hard to predict a priori how well the model will work.
What are the best practices to deal with these issues?
Pay a lot of attention to your training data.
Look at the cases where the algorithm is misclassifying data that it was trained on. These are almost always mislabels or strange edge cases. Either way you really want to know about them. Make everyone working on building models look at the training data and label some of the training data themselves. For many use cases, it’s very unlikely that a model will do better than the rate at which two independent humans agree.
Get something working end-to-end right away, then improve one thing at a time.
Start with the simplest thing that might work and get it deployed. You will learn a ton from doing this. Additional complexity at any stage in the process always improves models in research papers but it seldom improves models in the real world. Justify every additional piece of complexity.
Getting something into the hands of the end user helps you get an early read on how well the model is likely to work and it can bring up crucial issues like a disagreement between what the model is optimizing and what the end user wants. It also may make you reassess the kind of training data you are collecting. It’s much better to discover those issues quickly.
Look for graceful ways to handle the inevitable cases where the algorithm fails.
Nearly all machine learning models fail a fair amount of the time and how this is handled is absolutely crucial. Models often have a reliable confidence score that you can use. With batch processes, you can build human-in-the-loop systems that send low confidence predictions to an operator to make the system work reliably end to end and collect high-quality training data. With other use cases, you might be able to present low confident predictions in a way that potential errors are flagged or are less annoying to the end user.
Here’s an example of a failure that wasn’t handled gracefully. Microsoft hadn’t predicted how quickly their Tay bot would learn bad behavior from trolls on Twitter.
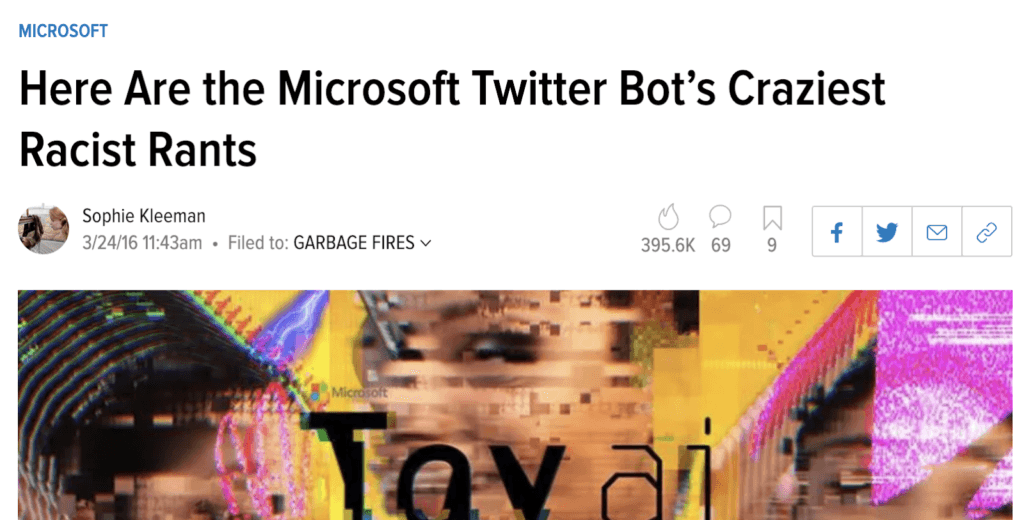
Image captured from Sophie Kleeman's article on Gizmodo
What’s Next?
The original goal of machine learning was mostly around smart decision making, but more and more we are trying to put machine learning into products we use. As we start to rely more and more on machine learning algorithms, machine learning becomes an engineering discipline as much as a research topic. I’m incredibly excited about the opportunity to build completely new kinds of products but worried about the lack of tools and best practices. So much so that I started a company to help with this called Weights & Biases. If you’re interested in learning more, check out what we’re up to.
Thanks Yan-David Erlich, James Cham, Noga Leviner and Carey Phelps for reading early versions of this and Peter Skomoroch for getting me thinking about this topic.