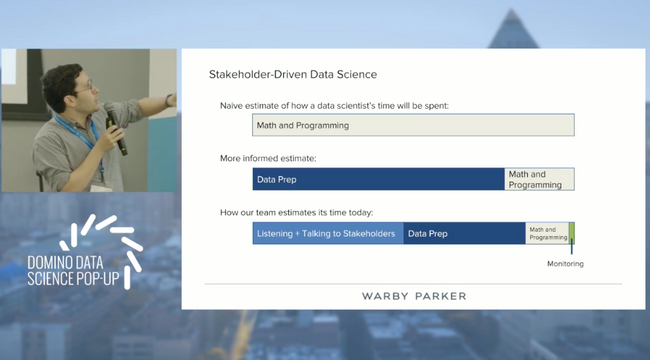
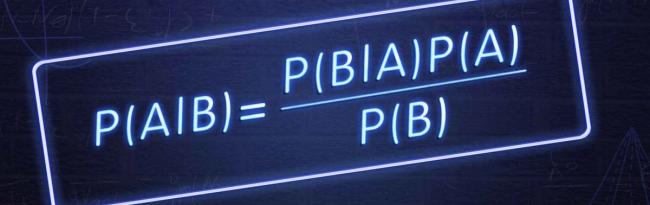Data ScienceModel-Based Machine Learning and Probabilistic Programming in RStanBy Daniel Chalef1 min read