Faster model tuning and experimentation




Domino provides a great way to iterate on analytical models by letting you run many experiments in parallel on powerful hardware and automatically track their results. Recently we added two powerful new features to make that workflow even easier: Run Comparisons and Diagnostic Statistics.
Motivation
Many principles from software engineering (e.g., version control) are critical for good analytical work, but standard software tools (e.g., Github, continuous integration systems) don't always transplant well onto analytical workflows. One reason for this is that while source code is the key component of software systems, analytical work involves code as well as data, parameters, statistics, and visual results.
A typical iterative model development workflow involves testing different techniques or parameters, and then comparing visual results (e.g., charts) or model statistics (e.g., AUC) — and upon inspection, determining which source code changes were responsible for the better results. Software engineering tools don't facilitate this workflow.
##Run Comparison
Run comparison makes it easy to figure out how two experiments differed in their inputs, and how those changes affected the results that were generated.
Comparing two runs is easy: simply select the two runs you’re interested in and hit the “Compare” button:
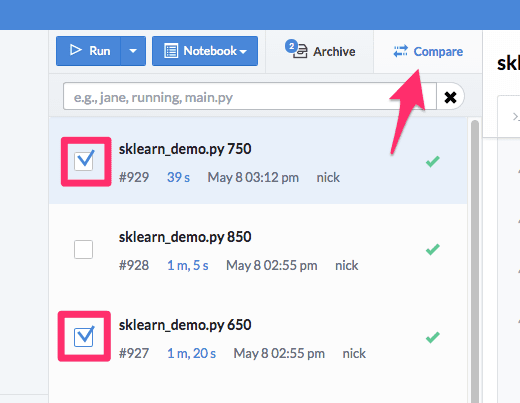
This will generate a report, summarizing the differences between those two runs:
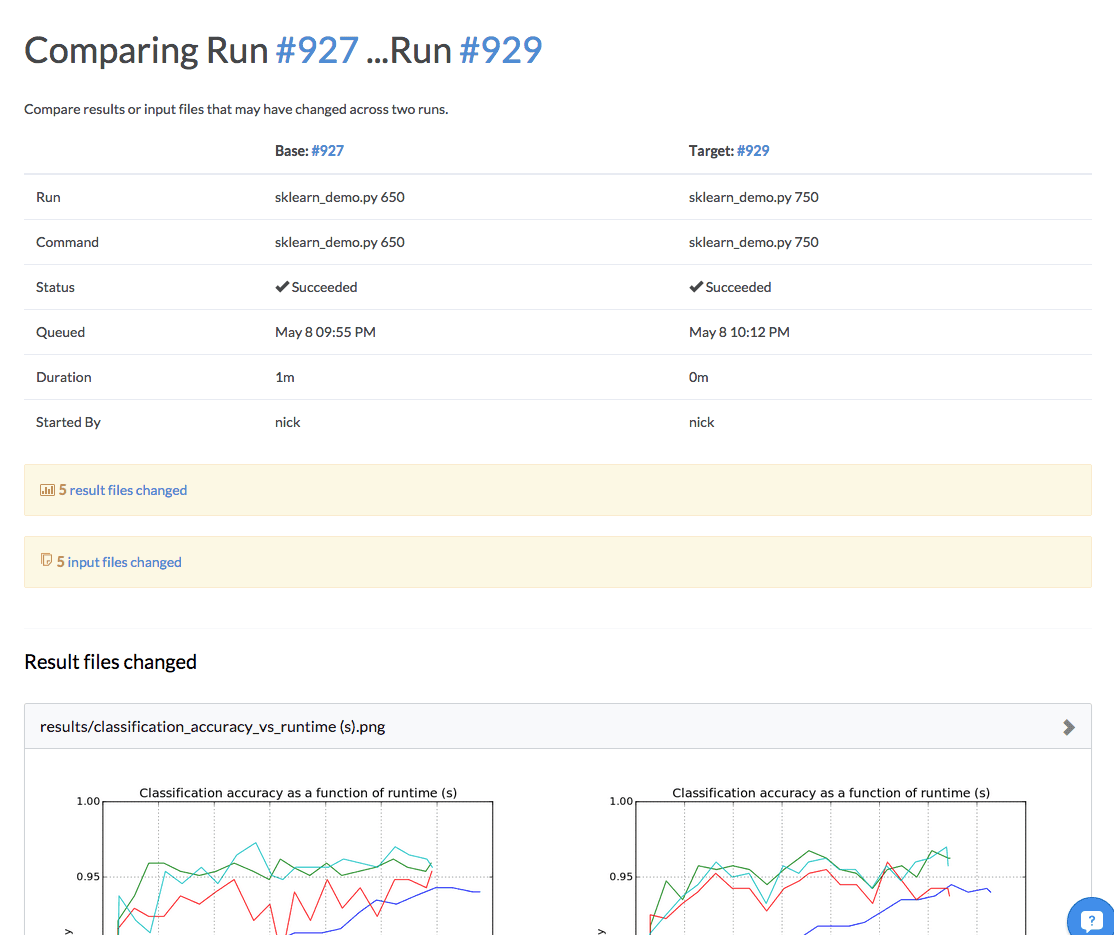
There are three sections: (1) a summary of the differences (2) the differences between the results that were generated by the two runs and (3) the differences between the input code and data.
Remember that Domino snapshots the state of all the files in the project before the run starts (the “inputs”) and snapshots the project after the run completes (the “outputs”). Any files that were added or modified between the input and outputs are considered “results.”
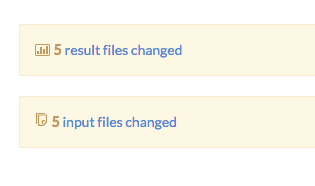
To quickly navigate between the sections, you can use these links, located immediately below the run comparison table at the top:
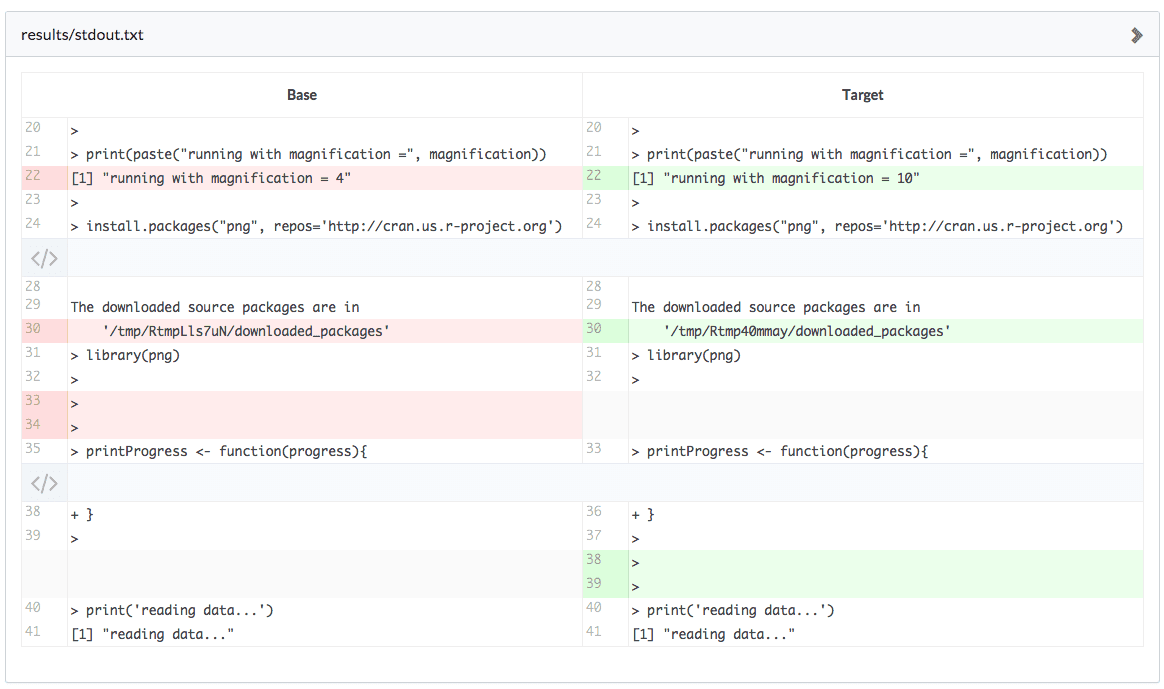
Domino will do its best to show you differences as sensibly as it can. For text, we will highlight the lines in the file that are different:
For files that we know how to render, we will render those files side-by-side so you can easily visually compare:
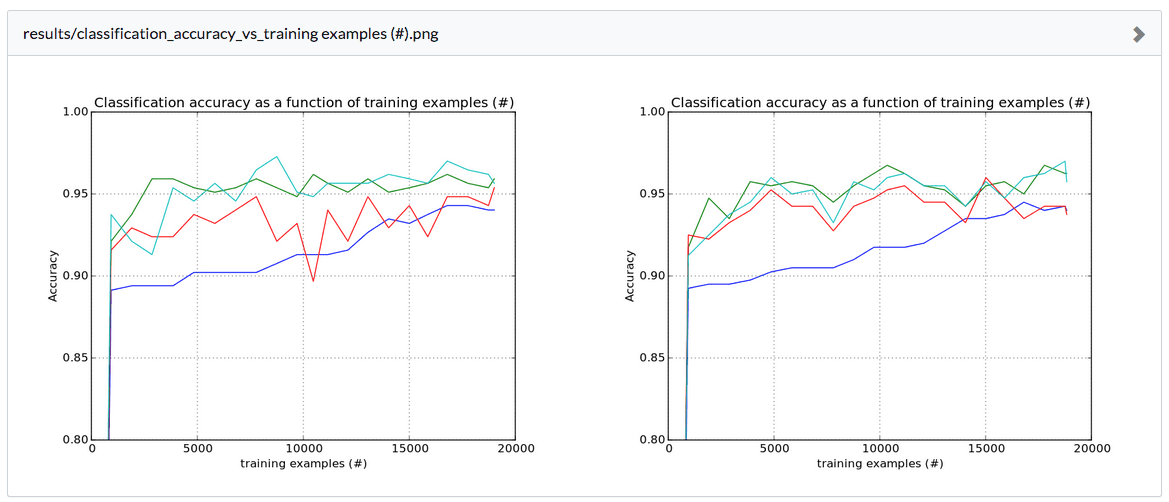
And for files Domino doesn’t know how to render, we’ll give you some simple metadata and links to download the exact version so you can look at them on your own computer:
Diagnostic Statistics
Understanding the performance of a particular model can be quite complex, and often it’s useful to see key metrics at a glance — metrics like area under curve, F1 score, log-likelihood — across all your runs, to allow you to quickly pre-prune which experiments are worth investigating further.
Domino’s Diagnostic Statistics functionality allows you to do just that!
To enable this, write a file dominostats.json to the root of your project directory that has the diagnostic statistics you’re interested in showing. Here is an example in R:
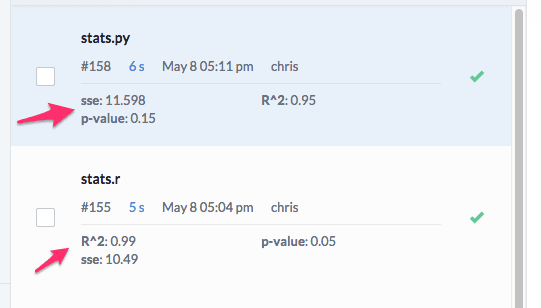
diagnostics = list("R^2" = 0.99, "p-value" = 0.05, "sse" = 10.49)library(jsonlite)fileConn<-file("dominostats.json")writeLines(toJSON(diagnostics), fileConn)close(fileConn)And in Python:
import jsonwith open('dominostats.json', 'wb') as f: f.write(json.dumps({"R^2": 0.99, "p-value": 0.05, "sse": 10.49}))If Domino detects this file, it will parse the values out and show them on the Runs Dashboard:
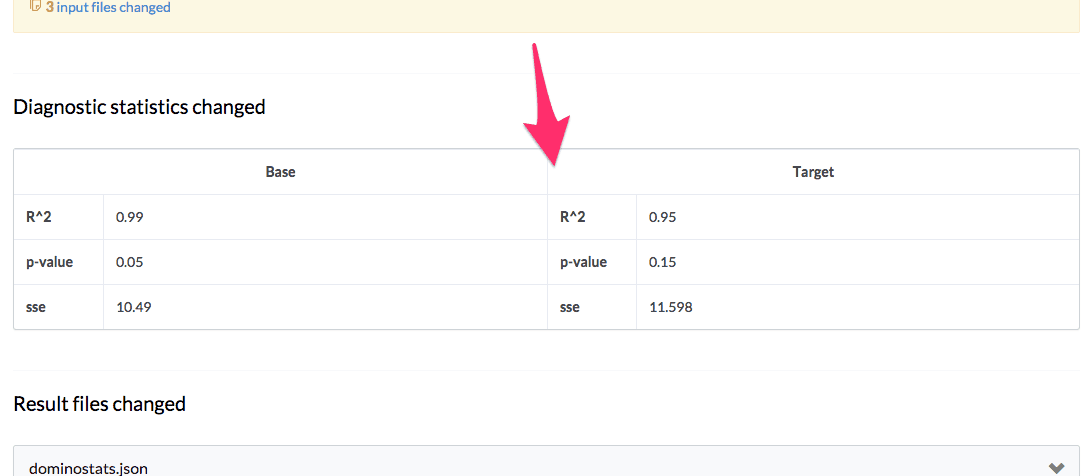
Also, run comparisons will show these statistics rendered in a table as well to make it even easier to compare their performance:
You can start running faster analytical experiments today with Domino.