Breaking generative AI barriers with efficient fine-tuning techniques




Using resource-optimized techniques, Domino demonstrates fine-tuning Falcon-7b, Falcon-40b, and GPTJ-6b.
In the rapidly expanding landscape of generative AI, fine-tuning large language models (LLMs) has emerged as a critical and intricate process. Fine-tuning adapts powerful pre-trained LLMs to specific topics or tasks. The fine-tuning process adjusts the underlying model's parameters. While fine-tuning offers enterprises an enormous jumpstart leveraging pre-trained LLMs to their unique needs, the technique presents some hurdles.
One major fine-tuning hurdle involves infrastructure. The sheer size and complexity of LLMs can lead to computational difficulties. Standard fine-tuning techniques can require extensive memory and processing power. Even the small LLMs are often very large, involving billions and tens of billions of parameters. This size and complexity require using pricy GPUs with as much memory as possible. Worse, adjusting billions of parameters can take a long time. Therefore, it is no surprise that extensively using such high-end, in-demand infrastructure gets very expensive.
Domino helps customers address cost challenges from the get-go. Customers can use standard cloud compute tiers, saving up to 20% over ML-specific options. They can also choose on-prem infrastructure for these demanding workloads, often avoiding data transfer costs. Beyond hardware, Domino's open architecture also makes it simple to use the latest tooling for efficient fine-tuning techniques instantaneously. These techniques can reduce infrastructure requirements to a single GPU, with less memory and even a lower-tier CPU. Our reference projects look at three techniques experiencing rapid adoption - quantization, LoRA, and ZeRO. Let's dive in!
Unpacking the Tools: LoRA, ZeRO, and Quantization
LoRA (Localized and Reasonable Adjustments) fine-tunes LLMs by freezing most parameters. Training only affects new, small-sized model layers.
ZeRO (Zero Redundancy Optimizer) Stage 3 is an optimization strategy aimed at reducing memory usage and improving the scalability of model training. ZeRO allows researchers to train much larger models, for a shorter time, primarily by partitioning model states across multiple devices. Other model and pipeline parallel techniques can spread the model itself across GPUs and more.
Model quantization aims to reduce infrastructure requirements by using a 4- or 8-bit number to represent the model parameters instead of a 32-bit number. As a result, the amount of memory and computation power required to store and operate on the model's parameters drops significantly.
As a result, LoRA, ZeRO, and quantization offer numerous benefits in LLM fine-tuning. These include improved performance, resource optimization, and cost-effectiveness. Our reference projects demonstrate the techniques with three LLMs: Falcon-7b, the much larger Falcon-40b, and GPTJ-6b.
Realizing the Generative AI Workflow in Domino
Our reference project work starts with an environment definition. Environments lie at the core of Domino's reproducibility engine. They combine a Docker container with the necessary code packages and development tools. Since we use GPUs extensively in our reference projects, we rely on an NVIDIA NGC container optimized for PyTorch as the basis for the project environment. We also include a set of Python packages, including HuggingFace's Transformers, PyTorch Lightening, tokenizers, datasets, and DeepSpeed. Environments provide teams with a consistent foundation for work and eliminate configuration and package conflict pain. With the environments defined, we can create Domino projects - one for each reference project.
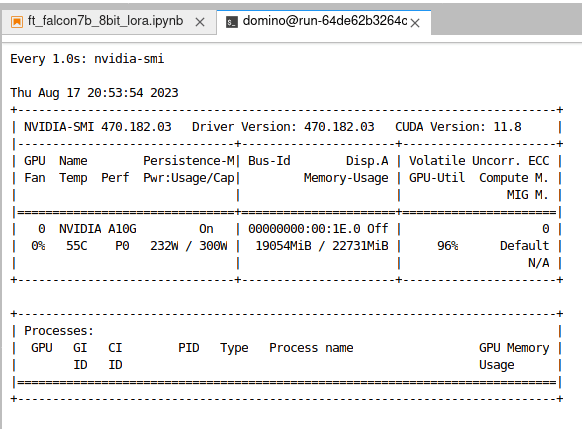
The reference projects come with a recommended AWS hardware tier (you can easily extrapolate similar tiers on other cloud providers). The tier recommendation offers infrastructure guidance and is verified to run the reference code. Note that we are using infrastructure tiers with large amounts of RAM. We also need a relatively large amount of GPU memory to load and store the foundation models’ parameters and optimizer states during fine-tuning.
Each reference project starts with a foundation model download, along with a relevant training dataset. To avoid recurring downloads, you can store both in Domino's dedicated, persistent file system, Domino Datasets. At that point, the projects follow a straightforward process: We fine-tune each model using the previously mentioned techniques - LoRA, Quantization, and ZeRO. ZeRO specifically benefits from Domino's simple access to an array of ephemeral cluster technologies. Clusters help accelerate and even reduce the cost of fine-tuning jobs. As an early proof point: thanks to these techniques, we were able to avoid high-end GPUs, using ones with 24GB or even 16GB of RAM.
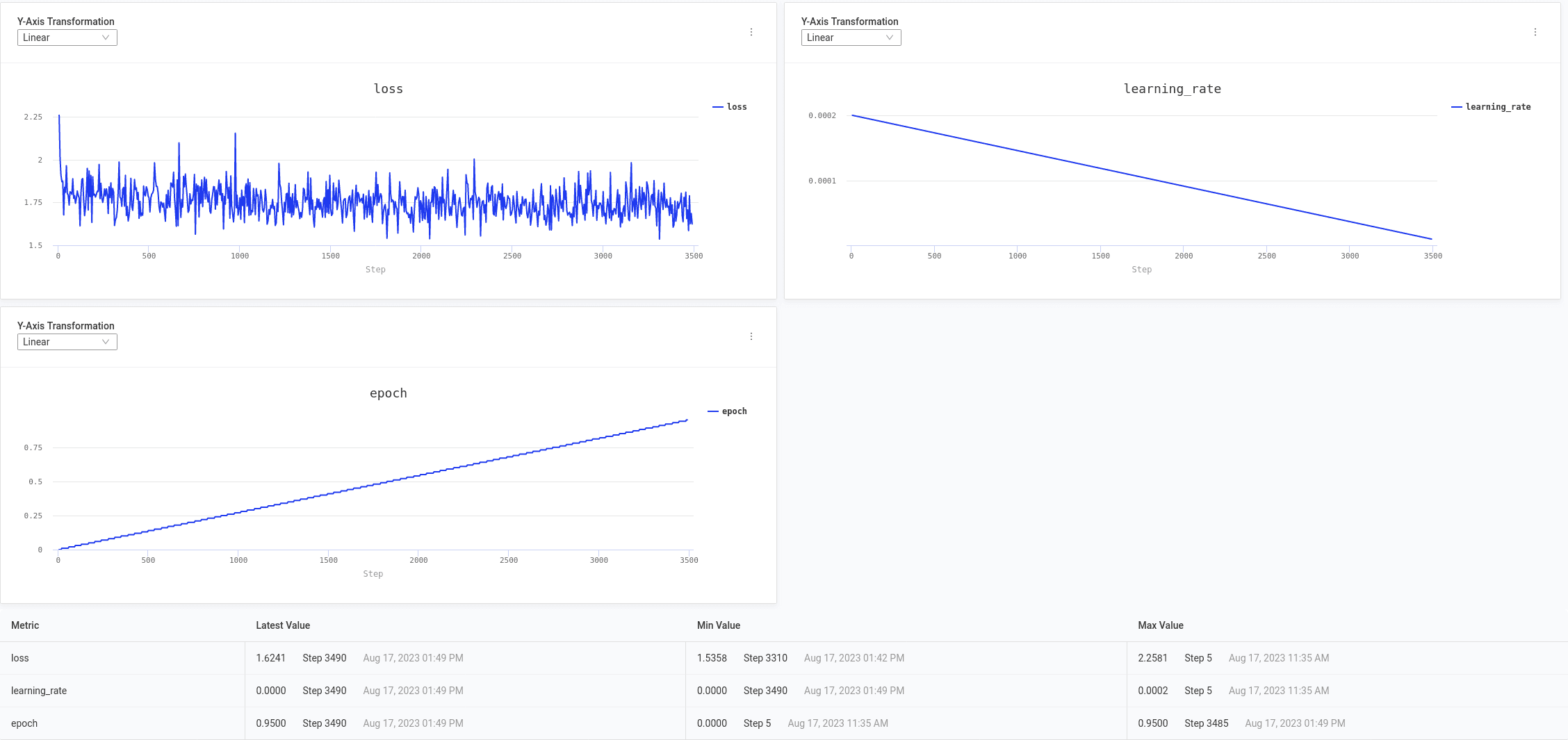
For larger-scale projects, Domino allows you to package fine-tuning efforts into scheduled jobs. Jobs automate the lifecycle of long-running workloads. Jobs shut down when completed, minimizing the use of expensive compute resources. Domino jobs can also run experiments concurrently, helping you identify better-performing models faster. Jobs retain other Domino's benefits, including automated reproducibility and experiment tracking. As with any Domino workload, data scientists can choose which infrastructure tier their job will run on with a single click of a button. And with a built-in MLflow instance to further aid in reproducibility, Domino makes managing and tracking model evolution simpler. Now that we've examined how Domino makes working with LLMs more efficient let's look at the reference projects in detail.
Exploring the Reference Projects
Falcon-7b
Falcon-7b LLM from TII is a 7 billion parameter causal decoder-only model trained on 1.5 trillion tokens. Falcon's architecture makes it adept at text generation, machine translation, and question-answering. We adapted code from the lit-gpt project to run on Domino with a conversational dataset that we curated in-house. The Domino environment for the project utilizes an NVIDIA NGC Pytorch container. We fine-tuned the 7b and 7b-instruct variants using LoRA and PyTorch Lightning. This framework offers robust training capabilities, ensuring a smooth fine-tuning process and making Falcon-7b well-optimized for tasks requiring instruction following. Visit the project repo on GitHub.
Falcon-40b
Falcon-40b is a 40-billion parameter model trained on one trillion tokens. The reference project involved fine-tuning 4-bit and 8-bit quantized model versions and LoRA. The project uses a conversational dataset to produce summaries using the Huggingface Trainer. As a result, a single g4dn.12xlarge AWS instance was sufficient to train Falcon-40b. The model maintained high performance, highlighting the technique's potential for scenarios with limited computational resources. Visit the project repo on GitHub.
GPTJ-6b
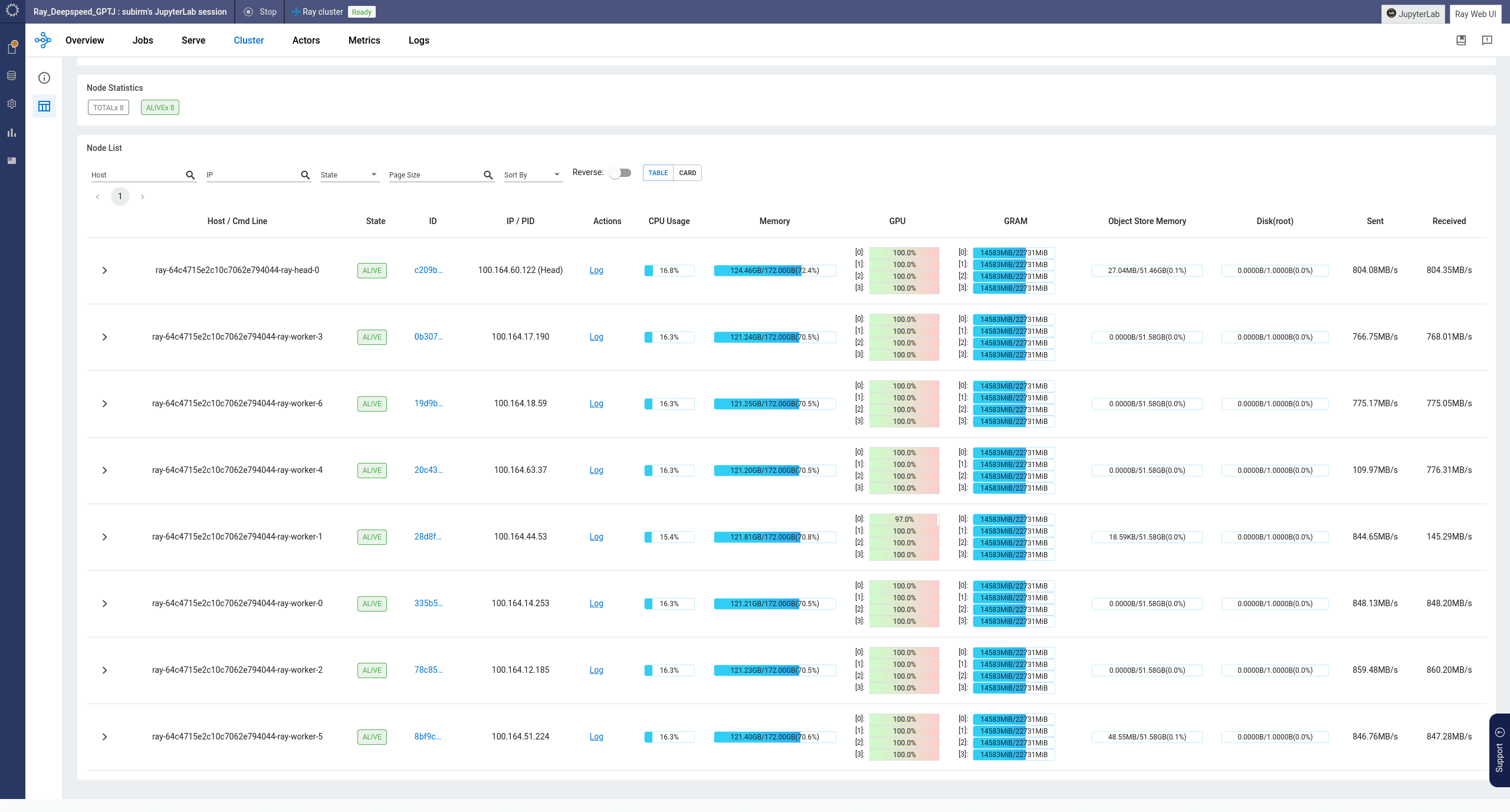
Our third reference project fine-tunes GPTJ-6b, created by EleutherAI. GPTJ-6b is an encoder-decoder model leveraging rotary position embedding. The project avoids quantizing and uses Ray and Deepspeed ZeRO Stage 3. The goal was to generate output in the style of Isaac Newton with the text of The Mathematical Principles of Natural Philosophy as our dataset. We use an 8-worker Ray cluster, each utilizing a g4dn.12xlarge instance. Due to their size, the demo uses Domino Datasets to store the fine-tuned model binary and other checkpoints. Visit the project repo on GitHub.
The Future of Fine-tuning
Fine-tuning techniques are unlocking new potential in large language models. Fine-tuning enables LLMs to perform more complex tasks and adapt to an expanding variety of applications. Our reference projects demonstrate how enterprises can overcome full fine-tuning complexity and cost. Quantization can markedly reduce LLM memory requirements. Parameter-Efficient Fine-Tuning (PEFT) techniques, like LoRA and Prompt Tuning, can further reduce infrastructure requirements. And parallelization strategies, like ZeRO, can further lower the bar to more affordable hardware. These techniques bring AI research to enterprise use cases. They expand the limits of what these LLMs can achieve. Domino enables enterprises to benefit from the latest commercial and open-source AI innovations. As this field continues to evolve, we expect to see even more exciting advancements. Domino will remain the fast, responsible, and cost-effective way to deliver AI at scale to the enterprise.