



If you are involved in work in the data science field, you may have heard about feature stores. This post will provide a basic overview of what feature stores are (For a deeper discussion, look here). Then, we will cover the problems they solve and how they work. Domino now incorporates a feature store into its platform. Finally, we will briefly introduce how you can use it. So let's get started!
What is a Feature Store?
In data science and machine learning, features are individual data building blocks used in the model development process. For example, in a weather forecast model, daily high and low temperatures, air pressure, and precipitation are all features. In many situations, The quality of features often determines the model's effectiveness.
A feature often consists of data stored across multiple systems. For instance, companies store a customer's address in one system, product preferences and interests in another, and her billing information and purchase history in a third. As a result, data scientists and analysts must access all three systems to get a complete view of what a customer is. To complicate matters, they may need access to these systems. Worse, companies may have differing opinions across different groups: Sales teams view a customer differently than customer support or accounting.
A feature store can help resolve these problems. It acts as a central, authoritative hub for data. They no longer need to comb through repositories, negotiate permissions or endure philosophical discussions about the meaning of a 'customer.' Instead, the feature store has the data ready and curated for their use.
How a feature store works
The data and analytics teams collaborate to create a pipeline to make feature stores work. The pipeline starts with raw data sources, includes processing steps, and ends with ready-to-use features. Such pipeline creation commonly requires the following steps:
- Data Ingestion: The first step is to ingest data from sources like databases, data lakes, and event streams, to name a few. The raw data is then reshaped and processed into a form that would make it more usable.
- Feature Engineering: The team then transforms the data into features. This work involves applying mathematical and statistical operations to the data. Specialized tools and some custom code help with this work. Ideally, this results in meaningful attributes.
- Feature Storage: Now that the data preparation steps are defined, the computed features must be stored somewhere - the feature store. Feature stores typically support two types of storage:
- Offline feature stores typically hold large-scale historical feature data. Machine learning model training usually relies on this feature store type. The offline feature store often resides in a data lake or a distributed file system.
- An online store stores the latest version of feature data. They serve data with low latency and withstand high request volumes. Such feature data is critical for real-time predictions and scoring. Online feature stores often reside in a low-latency database or a key-value store.
- Feature Serving: Feature serving aligns with use cases: Batch predictions (for example, scoring all users overnight) will retrieve the features from the offline store. Real-time predictions (e.g., in response to a web request) will retrieve features from an online store.
- Feature Discovery and Governance: Feature stores offer feature management and discovery tools. These tools include a feature catalog with descriptions and metadata, version control for feature computation code, monitoring for feature statistics, and mechanisms for ensuring data governance and compliance.
Domino's Feature Store
Domino is an open platform. Consequently, customers can and do integrate various open-source and proprietary third-party tools. These include feature stores. Many opt for comprehensive SaaS tools like Tecton. Others are exploring the open-source feature store Feast.
Given the growing need to support feature storage, Domino's MLOps platform now integrates Feast. With Feast, users can create and publish features to a global registry for others to discover and reuse. Feast is a code-first feature store. Python files describe feature definitions. A Git repository stores and versions this code.
Once enabled, Domino mounts the feature store's Git repository into Domino projects. The project team can then access features from workspaces and executions. Currently, Domino supports Snowflake, Amazon Redshift, Google BigQuery, and Domino datasets as feature data sources.
Users create and publish features right from Domino workspaces. As Feast's Git repository is accessible from the workspace, you can follow Feast's standard feature definition process. With the features defined, users can push them into Feast's repo. Domino will then make the features available to the project team. It will also be available for later use by others in the organization.
Finally, users will see the newly-defined features listed in a new panel under the workspace data panel. To access the features in actual analytics code, click the 'Copy code snippet' link. Once pasted, it will add a 'standard' snippet to the file. It will then offer access to features as variables in your environment.
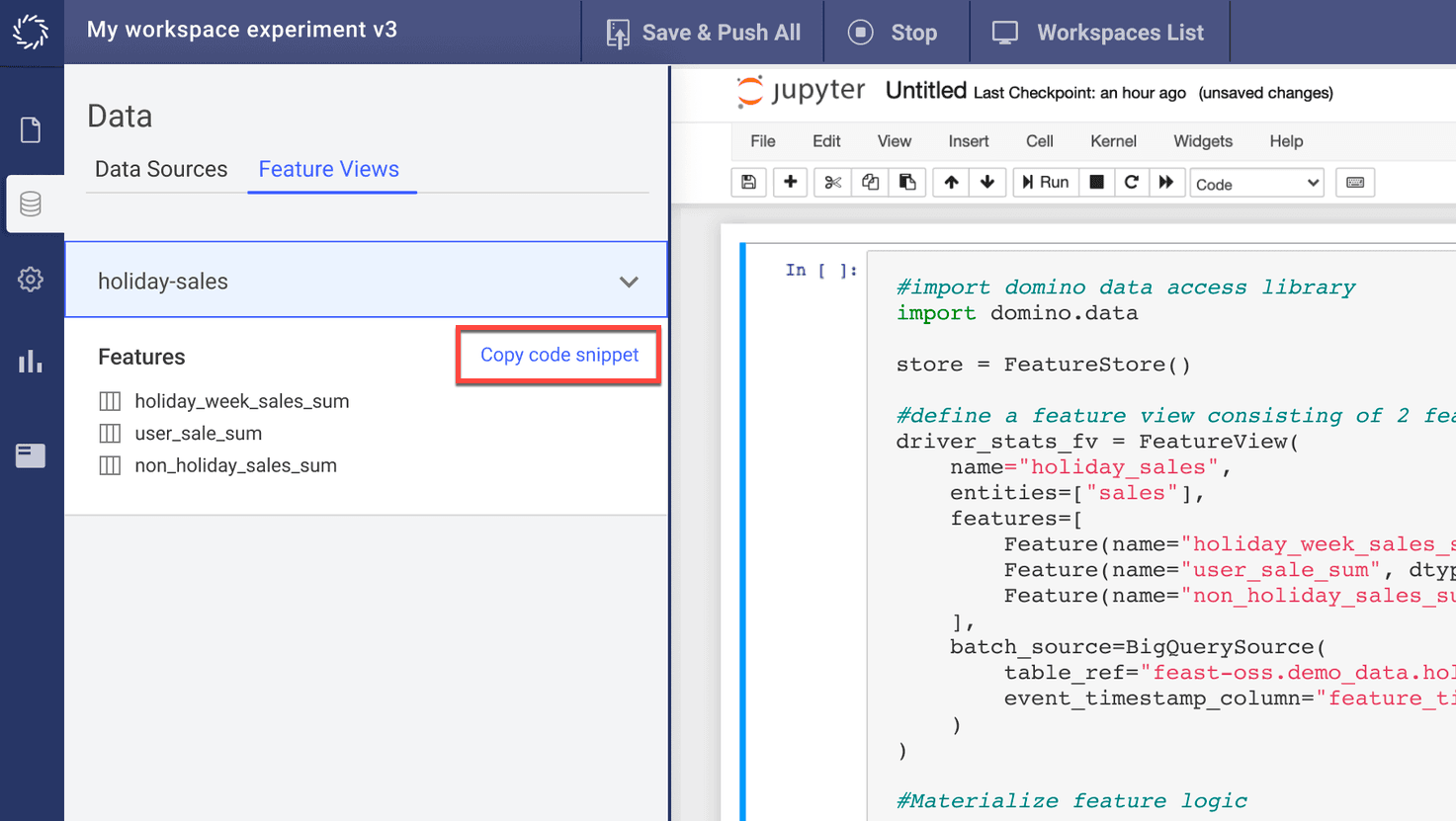
Domino offers both offline and online data stores using Feast. With the offline data store, data remains on the original data source. Therefore, data is pulled and processed on request. In contrast, Feast retrieves online feature store data from the data source to Domino's Feast-managed infrastructure periodically or upon the user's command.
Summary
Feature stores improve data science workflows in many ways. They simplify data access. Data scientists no longer need to worry about repository location or permissions. Feature stores also improve organizational consistency. Feature stores make data lineage clearer too, with a well-defined path from sources to models. They institute a single global definition for data assets. Model training and inference are simplified, accelerating access to pre-computed data. By using Feast, Domino is enabling customers to use a best-of-breed tool while ensuring its integration with the rest of Domino's features and workflows.
We look forward to collaborating with customers who incorporate the feature store into their projects and seeing how it helps them unleash the power of data science and AI.
Want to learn more about Domino? Join our weekly demo. And coming soon - a demo of Domino’s feature store.