Machine Learning in Production: Software Architecture




Special thanks to Addison-Wesley Professional for permission to excerpt the following "Software Architecture" chapter from the book, Machine Learning in Production.
Introduction
At Domino, we work with data scientists across industries as diverse as insurance and finance to supermarkets and aerospace. One of the most common questions we get is, “How do I get my model into production?” This is a hard question to answer without context in how software is architected. As data scientists, we need to know how our code, or an API representing our code, would fit into the existing software stack. Only then can we start to have serious conversations with our engineers about incorporating the model into the product.
To lay the groundwork for that conversation with engineers, I worked with Domino’s Head of Content to request permission from Addison-Wesley Professional (AWP) to excerpt the following "Software Architecture" chapter from the book, Machine Learning in Production. Many thanks to AWP for the appropriate permissions.
17.1 Software Architecture: Chapter Introduction
If you consider the total cost of building and running a given application or data pipeline, you’ll realize there are two major factors. The first is the cost of research and development. Building the application itself is essentially human power. The second is the cost of hosting the application, i.e., infrastructure costs. How much does it cost to store the data? How much does it cost to run the servers that respond to queries or build models?
Your understanding of hardware bottlenecks from Chapter 15 [in the book] is useful in predicting infrastructural costs because avoiding different bottlenecks will have different impacts. What about the cost of development? Besides administrative, managerial, and procedural practices, software architecture can help alleviate some of the cost of production and balance the readability and organization of code with hardware bottlenecks.
There are many software architectures to choose from that result in different levels of granularity or modularity of an application. Each one has trade-offs, balancing savings in cognitive overhead with savings in infrastructure costs. Several of these are discussed in the following sections.
17.2 Client-Server Architecture
In the most basic client-server application, there are two components: the client and the server. The client sends requests to the server, and the server listens for and responds to those requests.
In the vast majority of applications, communication between the client and the server takes place on a socket. There are many types of sockets, but the most common you’ll have experience with are the UNIX domain socket and the Internet socket.
UNIX sockets communicate by writing and reading information to and from operating system buffers on a single node. Internet sockets read and write information from a network interface. Sockets are APIs over lower-level operating system functions, which are themselves APIs to hardware functionality.
Some examples of clients that use Internet sockets are your favorite web browser, a peer-to-peer download tool like Napster, your OpenSSL client you use to log into remote machines, or your database client you use to interact with remote databases from an API host.
A few web servers you’re probably familiar with are nginx, apache, and lighttpd. A few database servers are mysqld, postgresql, and mongod. There are many other servers, such as OpenVPN, openssh-server, and nsqd, to name a few.
You may notice that many servers end with a d. This is short for daemon, which is a long-running process that is intended to (almost) never be stopped for as long as the application is run. Exceptions to this are related to maintenance, such as when updating the server software, updating the host hardware, or reloading configurations after a change. Generally speaking, most, if not all, servers are daemons.
Clients, on the other hand, are typically short-lived processes. They open connections to sockets servers listen on and close those connections when they are finished. Take your browser, for example. When you request a web page from a web server, the browser establishes a connection on port 80 (HTTP) or an encrypted connection on 443 (HTTPS). It sends a request to the server for the data that makes up the web page and displays it to you. When you close your browser, the client is shut down, but the server continues to run.
To complete a request, the client must first send it to the server. Once the server has received the request, it must process it and then send a response. This is pictured in Figure 17.1. The amount of time it takes for the request to arrive at the server and be sent back is referred to as latency.

Figure 17.1 A simple client-server interaction
Since clients and servers tend to use sockets, they are subject to the hardware and/or network bottlenecks that impact latency, as we discussed in the previous chapter [in the book].
17.3 N-tier/Service-Oriented Architecture
A more complicated version of the basic server-client architecture is the n-tier or service-oriented architecture. The tier is intended to indicate there are many levels of servers and clients, each potentially serving as well as sending requests. Tiers can be third-party services, or they can be services run in the local network.
An example is the typical web application, where a browser sends a request to a web server, and the underlying database client sends a request to a database server to fulfill that request. This complicates the basic server-client interaction by adding a layer of interaction that must be fulfilled serially. Now you don’t just have the round-trip (and resulting latency) from the client to the server and back. You have a round-trip between both clients and servers.
Since the database result is required to fulfill the client request, it usually has to happen before the server can begin responding to the request. This is pictured in Figure 17.2.
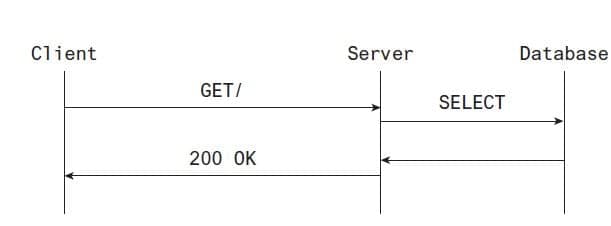
Figure 17.2 A client-server interaction backed by a database
As you can see, the latency between the client and server at each tier adds a layer of latency to the application since the requests happen serially. This can be a major drawback to service-oriented architectures, especially when there are many dependent requests happening serially.
Typically services are partitioned by some concern. For example, you may have one service responsible for basic interactions with user records (name, address, email, etc), while another third-party service could be responsible for providing demographic information about those users.
If you wanted to populate a web page with that user and their demographics, your web application would have to query both the User service and the Demographics service. Since the Demographics service is a third-party service, it uses a different lookup key than your application stores. For this reason, you have to look up the user record before querying the third party.
Since there can be many third-party services your application uses, it’s usually not a reasonable solution to update your application to use the third-party user ID. There are a few ways, still, to make this process faster.
Realizing most of the latency in the application is spent waiting to read on a socket, you can implement asynchronous requests for the user and demographics data. Now the total latency is roughly the greater of the two, rather than the sum.
The second approach to making this faster is to decompose the two services into one. Rather than querying the third party for demographic data, you could make that request once for all your users and query it along with the user record in your database. This makes what were two requests into one with the overhead of additional storage (Figure17.3).
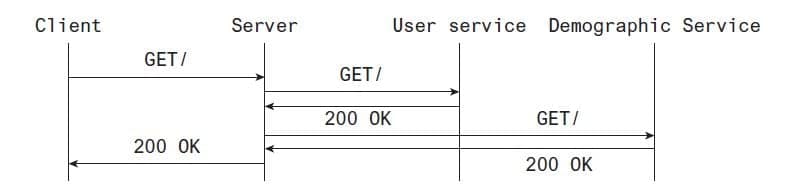
Figure 17.3 A client-server interaction backed by multiple services
17.4 Microservices
Microservices are similar to n-tier architectures, except that they’re not strictly tiered. Services can interact with whichever services they need, with whichever interdependencies are required. Figure 17.4 depicts an example network diagram.
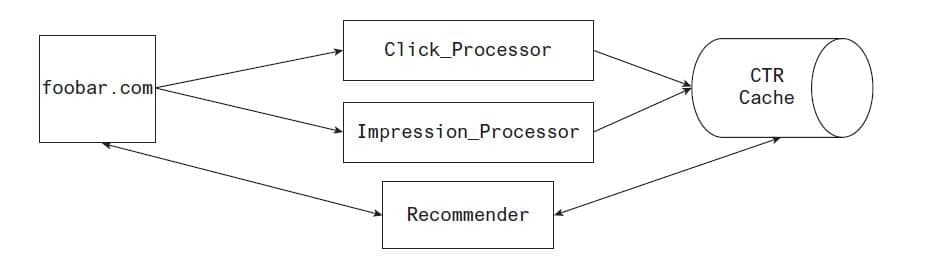
Figure 17.4 An example microservice architecture
Microservice software architectures are typically organized as a large set of individual applications, each running as independently from the other as possible. Code is laid out at a root directory either for all the applications (when the code base isn’t prohibitively large) or by product concern.
With hundreds or even thousands of small applications, the most common complaints with microservice software architectures are maintainability and readability. This method of code organization stands in contrast to monolithic architectures.
17.5 Monolith
If microservices are the smallest possible applications, decomposed to separate their business concerns from each other, a monolithic architecture is close to the opposite in terms of organization.
There is an ease of development when boilerplate, or repeated code, can be avoided in favor of implementing a new feature in the existing code base. This is one reason monolithic architectures are so popular and also a natural reason they’re adopted.
One of the problems with monolithic architectures comes when a deeply nested dependency needs to change its function signature. Either all code implementing that feature has to be updated to match the signature or a bridge has to be built to make the legacy code compatible. Neither of these outcomes is desirable.
On one hand, code in a monolithic architecture can be organized according to objects and functional utility (e.g., user objects, authentication, database routing), making it easy to find and extend. On the other hand, having all the tools you might need right in front of you can result in the yo-yo problem of having to climb up and down the call stack to figure out bugs or add new features, which add a lot of cognitive overhead.
17.6 Practical Cases (Mix-and-Match Architectures)
Depending on the application you’re building, one or the other architecture might be most appropriate for you.
If your code base has clear product separations, a microservice architecture as is might be best.
If your application is expected to reuse many common data-access components for a common, complex product purpose, you may choose a monolithic architecture.
If both these things are true, you may choose a combination of architectures, as shown in Figure 17.5. To the left you can see components of a web page, and to the right is a diagram of the services serving those components.
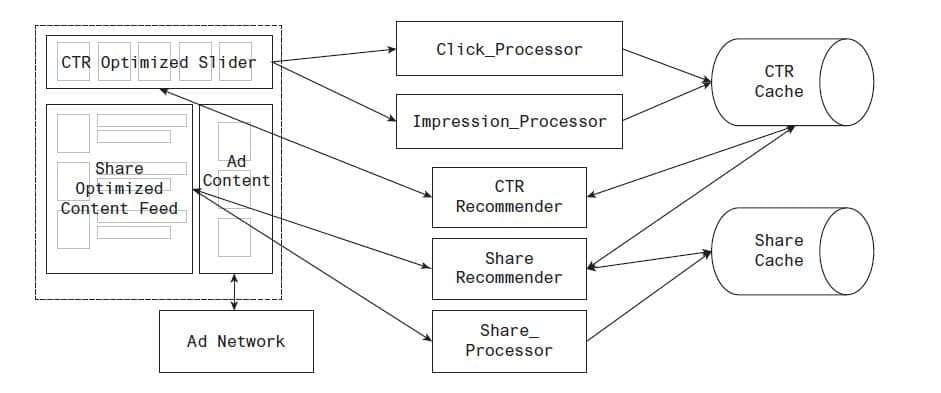
Figure 17.5 An example polyglot architecture
17.7 Conclusion
In this chapter, we discussed several software architectures that can help you organize your code as your application grows. Each has a few benefits and drawbacks. Regardless of your choice of architecture, it should be a choice. The default is typically a monolith, which is not suitable for every occasion.
Knowing the difference between n-tier, microservices, monoliths, and basic client-server applications, your choice of architecture is sure to be well-informed.