Trending Toward Concept Building - A Review of Model Interpretability for Deep Neural Networks




We are at an interesting time in our industry when it comes to validating models - a crossroads of sorts when you think about it. There is an opportunity for practitioners and leaders to make a real difference by championing proper model validation. That work has to include interpretability and explainability techniques. Explaining how deep neural networks work is hard to do. It is an active area of research in academia and industry. Data scientists need to stay current in order to create models that are safe and usable. Leaders need to know how to avoid the risk of unethical, biased, or misunderstood models. In this post, I breakdown trends in network interpretability applied to image data. Some of the approaches covered apply to non-image-based networks as well.
From Pixel Influence...
Most of the model explainability work for deep neural networks has been based on analyzing the influence inputs have on classification. For image data, this means looking at the importance of each pixel. The typical result is a saliency map, like those shown here.
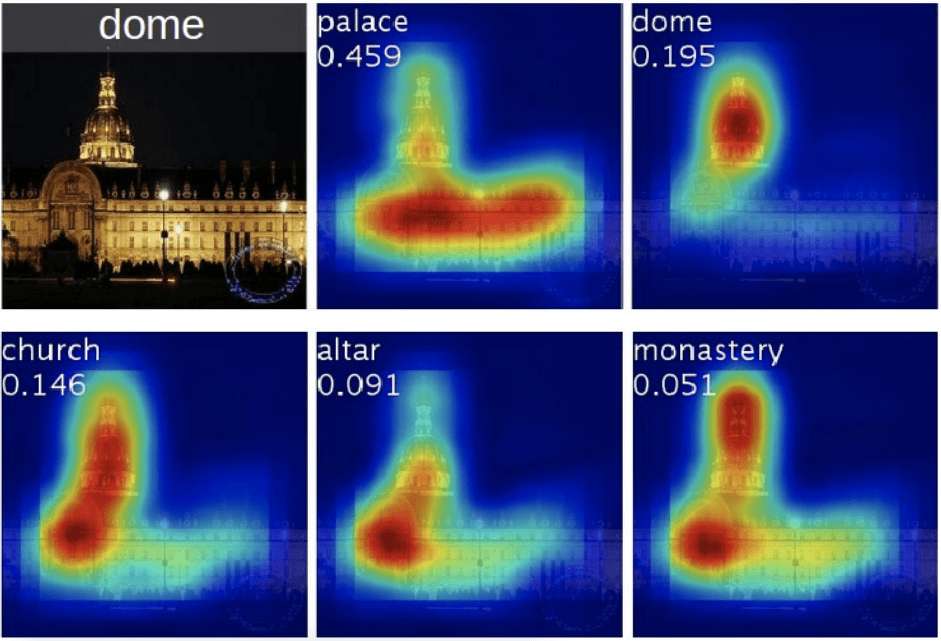
There are many ways to build a saliency map. Here we see the top 5 predicted categories for an image using a technique called Class Activation Mapping explained in this paper: https://arxiv.org/pdf/1512.04150.pdf
In their paper introducing TCAV (discussed later), the authors point out limitations to pixel-based approaches.
- Provides local explainability only
- No control over the concepts these maps pick
- Saliency maps produced by randomized networks are similar to that of the trained network (Adebayo et al., 2018)
- Simple meaningless data processing steps, may cause saliency methods to result in significant changes (Kindermans et al., 2017).
- Saliency maps may also be vulnerable to adversarial attacks (Ghorbani et al., 2017).
… On to Concept Extraction and Building
New research suggests a better way - focusing on concepts. Concepts are the building blocks of images stored in higher-level layers of a network. They can be foundational like corners, edges, curves, texture, hue, position, size, etc. They can also be collections of components like the face of a cat or the roof of a car.
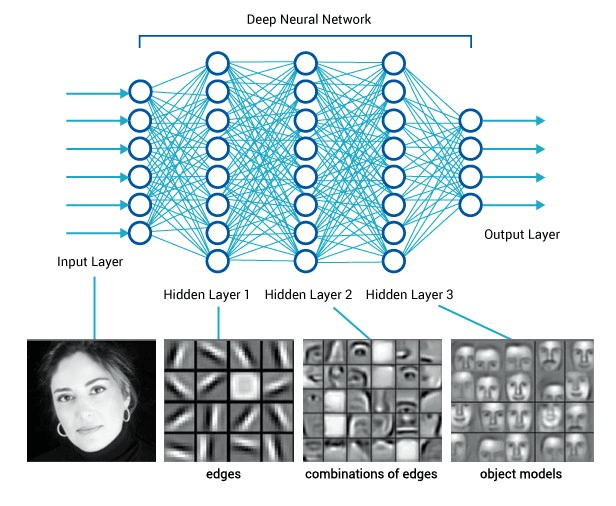
Networks do a good job of learning concepts that increase in complexity with each layer. Source: Medium
Initial interpretability work focused on extracting the concepts that a network discovered in the natural process of trying to classify images. Lately, however, there is very exciting research emerging around building concepts from first principles with the goal of optimizing the higher layers to be human-readable. Instead of optimizing for pure accuracy, the network is constructed in a way that focuses on strong definitions of high-level concepts. In other words, we optimize for interpretability rather than for prediction accuracy. Signs are pointing to the possibility that doing this will give better prediction accuracy in the end.
In the following sections, I introduce various approaches associated with the techniques just discussed. Be sure to make it down to the last section on concept building. It is exciting to see what is coming down the pipe.
A Review of Approaches Based on Pixel Influence
Saliency Maps
An introduction can be found at https://arxiv.org/pdf/1312.6034.pdf
Deep SHAP
“DeepLIFT was recently proposed as a recursive prediction explanation method for deep learning [8, 7]. It attributes to each input a value that represents the effect of that input being set to a reference value as opposed to its original value… [We’ve] adapt[ed] DeepLIFT to become a compositional approximation of SHAP values, leading to Deep SHAP.” https://proceedings.neurips.cc/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf
LIME
“When using sparse linear explanations for image classifiers, one may wish to just highlight the super-pixels with positive weight towards a specific class, as they give intuition as to why the model would think that class may be present.” (https://arxiv.org/pdf/1602.04938.pdf)

This image was incorrectly classified as a black bear. The collection of positive weight pixels on the right shows what the network focused on for this image. Image source: https://arxiv.org/pdf/1602.04938.pdf
Anchor
“An anchor explanation is a rule that sufficiently “anchors” the prediction locally – such that changes to the rest of the feature values of the instance do not matter. In other words, for instances on which the anchor holds, the prediction is (almost) always the same.”

What part of the beagle image does the network think is most influential in deciding to apply the label of beagle? In other words, if we superimpose that part of the image on any other image it will still predict a beagle. Image source: aaai.org
A Review of Approaches Based on Concept Extraction
TCAV
Allows a researcher to test the importance of high-level, human interpretable concepts in their network. Testing with Concept Activation Vectors (TCAV) makes it easy to look for concepts that could pose an ethical problem or are suspected of confounding the classification. One example the authors gave was checking for the presence of a ping-pong ball when identifying the ethnicity of a person in an image. Three models were created. After TCAV, researchers have data to discard models that are confounded with the presence of a ping-pong ball thus avoiding a poorly generalizing and unethical model.
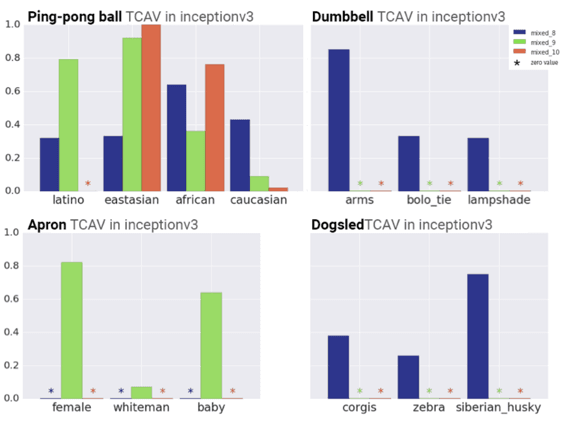
Image source: https://arxiv.org/abs/1711.11279
ACE
Automated Concept-based Explanation (ACE) is a hybrid approach that relies on pixel influence but also tests for the presence of concepts. It seeks to eliminate the need for hand-designed concepts and human bias in concept selection such as used in TCAV. It takes a trained classifier and a set of images of a class as input. It then extracts concepts (usually in the form of pixel groups) in that class and returns each concept’s importance.

Image source: Cornell
Influence-directed explanations
This approach combines traditional input influence for a single instance with activation neuron identification (concept extraction) for higher-level concepts. It identifies neurons with high influence and provides visualization techniques to interpret for the concept they represent. When you stitch many images together you get global explainability which is hard to achieve for most networks.

Taking a model trained to classify convertibles, we see that the influence-directed explanation almost always looks at the roof of the car, giving us confidence that the model has learned the right concept. Image source: Carnegie Mellon University
A Review of Approaches Based on Concept Building
Interpretable CNNs
Without any additional human supervision, the network is optimized to use filters to automatically push high conv-layer representations in a network to represent an understandable object part. Each filter must encode a distinct object part that is exclusive to a single category. These object parts are usually human-interpretable. Forcing the layers of the network to represent parts of the object that humans can understand makes it relatively easy to explain the entire network. Predictive loss occurs but is often minimal.
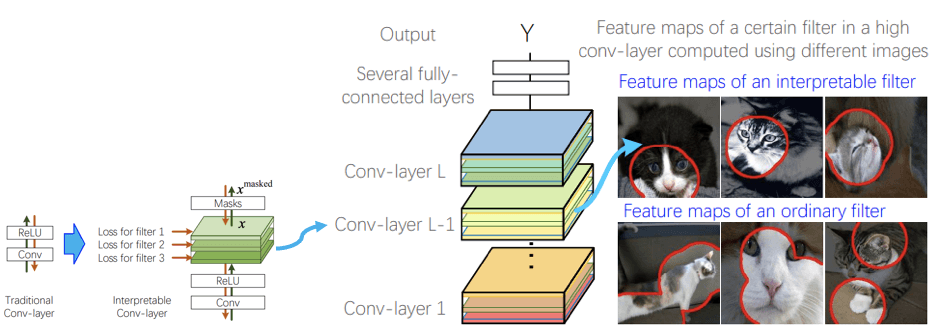
“Interpretable convolutional neural networks (CNN) add a regularization loss to higher convolutional layers of CNN to learn disentangled representations, resulting in filters that could detect semantically meaningful natural objects.” Image and quote source
CapsNet
Capsules represent properties of a particular entity in an image such as position, size, orientation, velocity, albedo, hue, texture, etc. The model learns to encode the relationships between a part and whole which leads to viewpoint invariant knowledge that generalizes to new viewpoints. CapsNet approaches started out purely supervised, but now use unsupervised structure extraction with a simple classifier for labeling. “Research on capsules is now at a similar stage to research on recurrent neural networks for speech recognition at the beginning of this century. There are fundamental representational reasons for believing that it is a better approach but it probably requires a lot more small insights before it can out-perform a highly developed technology. The fact that a simple capsules system already gives unparalleled performance at segmenting overlapping digits is an early indication that capsules are a direction worth exploring.” (https://papers.nips.cc/paper/6975-dynamic-routing-between-capsules.pdf)
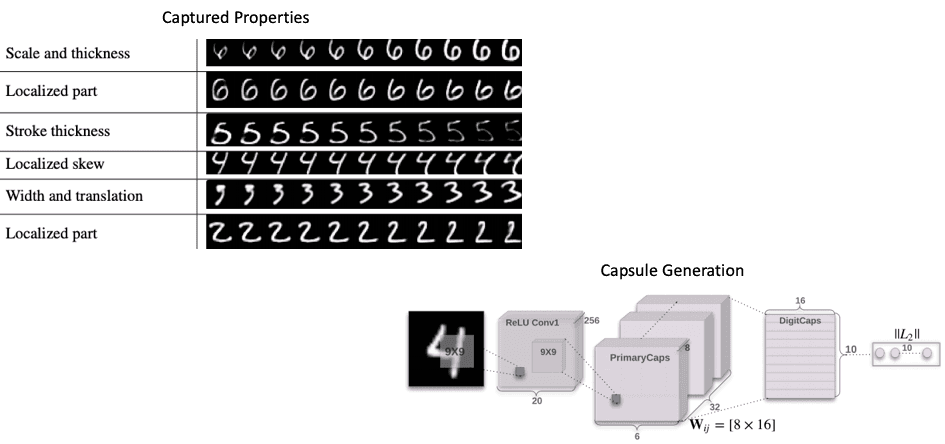
Image source: NeurIPS Proceedings
Where to Go from Here
This is an exciting and important area of data science research. For a broader, and slightly deeper, dive into this topic, I suggest checking out this recording of a recent conference talk I gave on explainability.
Lastly, I’ll note that this is all well and good but of no effect if data scientists and analytical leaders are not focusing on model explainability in their validation workflows. Then, once we, as an industry, get the model validation side of our house in order, we will need to transfer many of the same techniques over to the model maintenance side. Models and input data will drift over time and can introduce biases that were not present in training. Yes, there is a lot of work to do, but that also means there is ample opportunity for each of us to step up and champion proper model validation in our organizations.
Banner photo by Joey Kyber on Unsplash