Why Kubernetes is great for data science workloads
Bob Laurent2020-11-16 | 9 min read

Kubernetes is an open-source container orchestration system that is quickly becoming essential to IT departments as they move towards containerized applications and microservices. As powerful as Kubernetes is with general IT workloads, Kubernetes also offers unique advantages to support bursty data science workloads. With the help of containers, data scientists can make their modeling portable and reproducible, and massively scale these same, containerized machine learning models.
Kubernetes: The new substrate of computing
Docker and containerized applications have become extremely popular in enterprise computing and data science over the last few years. Docker not only enables powerful new DevOps processes, but it has also elegantly solved the problem of environment management.
Containers need to be managed and connected to the outside world for tasks such as scheduling, load balancing, and distribution. Kubernetes (aka K8s) was developed to manage the complex architecture of multiple containers and hosts running in production environments. It provides the orchestration required to schedule containers onto a compute cluster, and manage the workloads to ensure they run as intended. Kubernetes helps you manage containerized applications (e.g., apps on Docker) across a group of machines. K8s is like an operating system for your data center, abstracting away the underlying hardware behind its API:
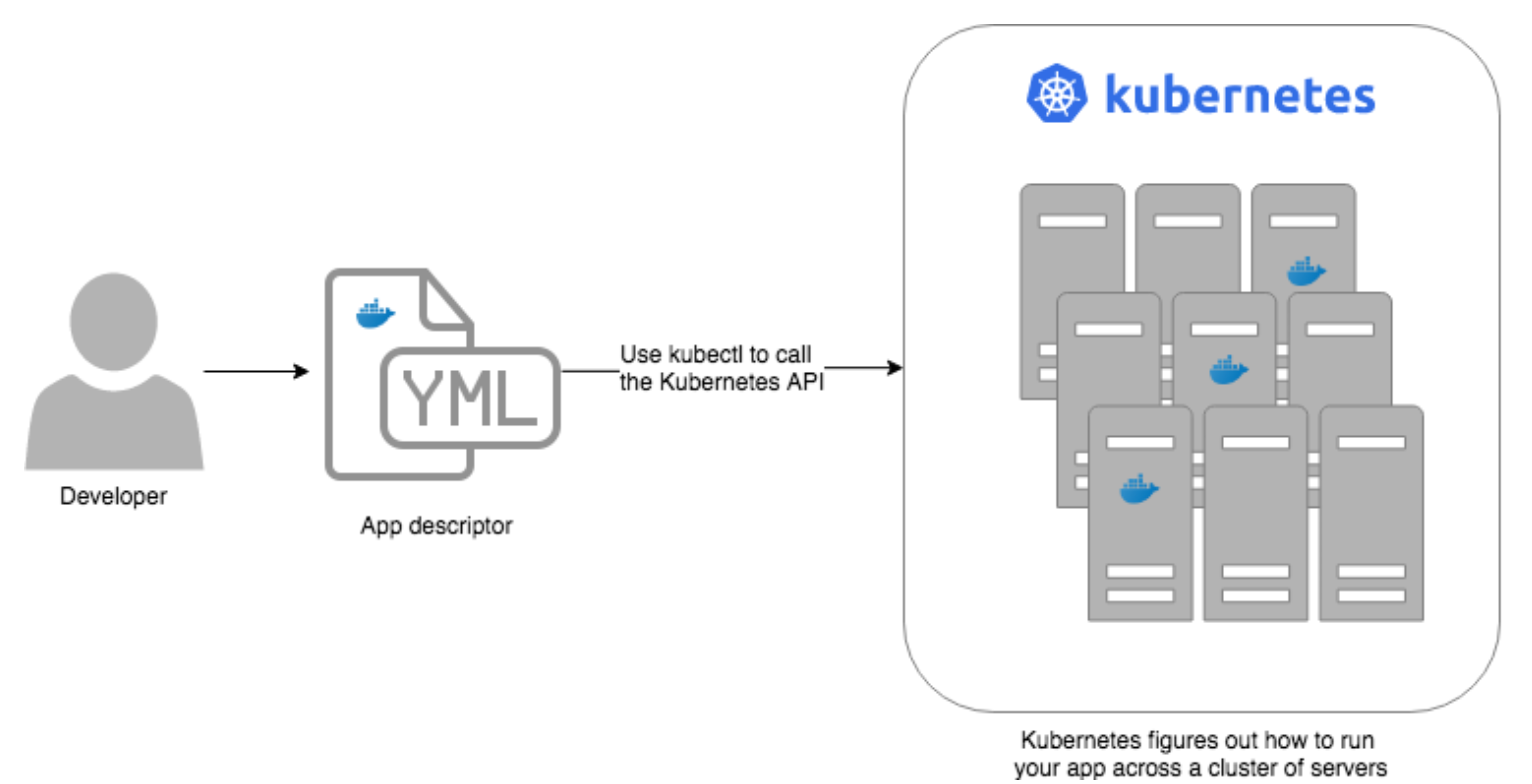
Source: Gruntwork
Kubernetes is also becoming the platform infrastructure layer for the cloud. Before K8s, when you had to deploy multiple virtual machines (VMs), you might have had arbitrary load balancers, networks, different operating systems, and so on. There was so much variation, even within a single cloud service, that you couldn’t take a distributed application and make it truly portable. Kubernetes, on the other hand, can be used as a consistently programmable infrastructure. Kubernetes makes networking, load balancing, resource management, and more deployment considerations consistent.
Gaining popularity in enterprise IT settings
Among IT professionals, Kubernetes is becoming the consensus API for infrastructure future-proofing. According to the Cloud Native Computing Foundation, K8s is now the second-largest open source project in the world, just behind Linux. And in a recent 451 Research/StackRox survey of over 400 IT professionals, 91 percent are using Kubernetes, up from 57 percent just two years earlier:

Source: StackRox
A great fit for data science workloads
If you recall the requirements of the data science department before Docker/containers, environment and package management were onerous. IT would frequently have to install new packages. Code would work differently (or sometimes not at all) for different people because their environments were different. Old projects became unusable, and old results became impossible to reproduce because the environment had changed since the code was written. Docker elegantly solved that as its images contain the set of software and configuration files that should be in place when analytical code is run. Docker has helped tremendously with package and environment management, as well as reproducibility.
Efficiency and resource utilization: Kubernetes brings a whole new set of benefits to containerized applications, including efficiency and resource utilization. K8s allows data scientists scalable access to CPUs and GPUs that automatically increase when the computation requires a burst of activity and scales back down when finished. This is a tremendous asset, especially in the cloud, where costs are based on the resources consumed. Scaling a cluster up or down is quick and easy because it’s a matter of just adding or removing VMs to/from the cluster. This dynamic resource utilization is especially beneficial for data science workloads, as the demand for high-powered CPUs, GPUs and RAM can be extremely intensive when training models or engineering features, but then the demand can scale down again very quickly.
Kubernetes also helps in implementing infrastructure abstraction and can provide data scientists a layer of abstraction to compute services without worrying about the underlying infrastructure. As more groups look to leverage machine learning to make sense of their data, Kubernetes makes it easier for them to access the resources they need.
Cloud flexibility: Another benefit of Kubernetes for data science workloads is that all major cloud vendors – including Amazon, Google, and Microsoft – offer managed services to provide Kubernetes clusters that are built on their flexible and elastic infrastructure. Each of these vendors frequently introduces new infrastructure innovations, like new and more powerful GPUs and TPUs, new cost structures, and so on. As K8s enables application portability and flexibility between infrastructures, its support for cloud portability and promise around hybrid and multi-cloud options is particularly important for data science workloads. IT leaders charged with supporting data science capabilities understand that preserving cloud flexibility is very important.
Tailoring Kubernetes for data science
While Kubernetes provides a great foundation for tool agility, faster iterations, and reproducibility within a data science platform, a fair amount of customization is required before it is optimized for data scientists. Tailoring K8s for data science should address the following features:
- Usable interface for data scientists: The declarative YAML syntax of K8s is powerful for engineers and DevOps folks, but it is not the most intuitive interface for data scientists. Data scientists need an intuitive interface and APIs that abstract some of K8s’ concepts.
- Containerized environment management: To be able to achieve reproducibility as described above, data scientists need to be able to create, update, and manage images that will be used for their work. K8s needs to be adapted to allow for building container images.
- Integrated user management and permissions: K8s provides a set of authorization primitives, but this is often not sufficient to provide true user isolation for colocated workloads, as well as proper mechanisms for managing sensitive information to use workloads (e.g., access credentials for data connections).
- Data science-specific scheduling: K8s alone is often not sufficient to properly schedule complex multi-pod workloads commonly used in data science.
- Resource controls: K8s needs to be augmented to enable administrators to balance user access to scalable compute resources, and sufficient controls to manage costs and prevent monopolizing capacity.
We completed much of this customization ourselves when we rebuilt our compute engine on top of Kubernetes. In the process, we also added high availability, horizontal scalability, enterprise security, and more – all based on a scalable foundation of Kubernetes.
Conclusion
If you’re planning any new IT initiatives to support your data science workloads/teams, Kubernetes support should be an important requirement. With Kubernetes’ rapid growth, orchestration capabilities, and its interoperability across clouds and on-premises systems, it offers both unparalleled management power and portability. It ensures that your systems can work with any cloud vendor moving forward. And it efficiently manages the burstiness of data science workloads.
Domino is the first enterprise data science platform that is fully Kubernetes native. That means that you can run Domino workloads on any cloud or on-premises infrastructure. Domino is well-aligned with your IT strategy and infrastructure vision, and can be a key enabler as you move towards a full cloud, or hybrid on-prem and cloud deployment. With Domino on Kubernetes, you can future-proof your data science organizations’ ability to use the next generation of tools and distributed computing frameworks.
For additional details about Kubernetes and why forward-looking IT departments should be adopting it now or in the near future, check out our new whitepaper.


Bob Laurent is the Head of Product Marketing at Domino Data Lab where he is responsible for driving product awareness and adoption, and growing a loyal customer base of expert data science teams. Prior to Domino, he held similar leadership roles at Alteryx and DataRobot. He has more than 30 years of product marketing, media/analyst relations, competitive intelligence, and telecom network experience.
RELATED TAGS
SHARE