Subject archive for "model," page 4

Scaling Machine Learning to Modern Demands
This is a Data Science Popup session by Hristo Spassimirov Paskov, Founder & CEO of ThinkFast.
By Grigoriy34 min read

Benchmarking Predictive Models
It's been said that debugging is harder than programming. If we, as data scientists, are developing models ("programming") at the limits of our understanding, then we're probably not smart enough to validate those models (“debug”) effectively.
By Eduardo Ariño de la Rubia13 min read

Principles of Collaboration in Data Science
Data science is no longer a specialization of a single person or small group. It is now a key source of competitive advantage, and as a result, the scale of projects continues to grow. Collaboration is critical because it enables teams to take on larger problems than any individual. It also allows for specialization and a shared context that reduces dependency on "unicorn" employees who don't scale and are a major source of key-man risk. The problem is that collaboration is a vague term that blurs multiple concepts and best practices. In this post, we clarify the differences between repeatability, reproducibility, and whenever possible the golden standard of replicability. By establishing best practices of frictionless in-team and cross-team collaboration, you can dramatically improve the efficiency and impact of your data science efforts.
By Eduardo Ariño de la Rubia17 min read

Introducing the Data Science Maturity Model
Many organizations have been underwhelmed by the return on their investment in data science. This is due to a narrow focus on tools, rather than a broader consideration of how data science teams work and how they fit within the larger organization. To help data science practitioners and leaders identify their existing gaps and direct future investment, Domino has developed a framework called the Data Science Maturity Model (DSMM).
By Mac Steele2 min read
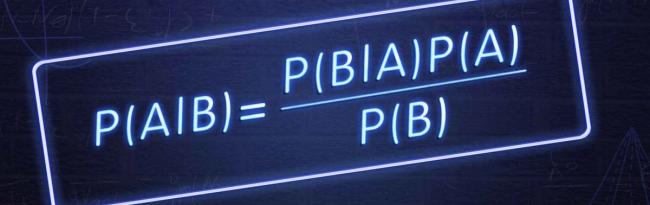
An Introduction to Model-Based Machine Learning
This blog post follows my journey from traditional statistical modeling to Machine Learning (ML) and introduces a new paradigm of ML called Model-Based Machine Learning (Bishop, 2013). Model-Based Machine Learning may be of particular interest to statisticians, engineers, or related professionals looking to implement machine learning in their research or practice.
By Daniel Emaasit15 min read

Providing Digital Provenance: from Modeling through Production
At last week's useR! R User conference, I spoke on digital provenance, the importance of reproducible research, and how Domino has solved many of the challenges faced by data scientists when attempting this best practice. More on the topic, and a recording of the talk, below.
By Eduardo Ariño de la Rubia1 min read
Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.