
Data science is a field at the convergence of statistics, computer science and business. It is highly valued by organizations as they strive to remain competitive, increase revenues and delight customers because data scientists are able to coax insight on how to improve decision making by the business out of the vast stores of data created by the business. Its value is so significant that scaling data science has become the new business imperative with organizations spending tens of millions of dollars on data, technology and talent.
In this article, take a deep dive into data science and how Domino’s Enterprise MLOps platform allows you to scale data science in your business.
What is Data Science and How is it Used?
Data science is an interdisciplinary field within STEM that combines math and statistics, computer science, and business acumen to find patterns in complex datasets that can be used to improve decision making.
In its current form, data science is limitless in terms of industry and application; the only requirement is data, compute power, data scientists, and a desire to become model-driven. This becomes increasingly easier as more types and volumes of information are digitally collected at all levels of business and computing power is easier than ever to obtain. Today, data is generated constantly through multiple channels including transactional systems, sensors, cameras, and online interactions. Improvements in storage have made it possible to capture, manage and use this data in as fast as real time.
These advances have had huge ramifications across industries ranging from finance and banking to healthcare and insurance. They have enabled new cross-industry applications, such as in customer analytics and fraud detection. For example, advances in natural language processing have allowed healthcare professionals to have visits with patients automatically transcribed, reducing time spent on documentation and mitigating ambiguities that may arise long after the patient has left the clinic. Rare event detection such as a rare disease diagnosis and credit card fraud, have seen drastic improvements in accuracy
What are Data Scientists?
A successful data scientist has a rare combination of technical skills in statistics and computer science domain expertise, out-of-the-box thinking and strong communication skills. Communication cannot be emphasized enough, for it is this trait that ensures results are effectively translated from the white board to impact on business metrics. The information being communicated is usually how a model, process or algorithm that pulls insights from data and applies them to critical issues within a business works. Only when the business understands the models will they trust them to drive decisions in the business. Models could be consumer-centric, like identifying key consumer groups. They can also be internal, like identifying what branches had the highest output or who in the company might deserve a raise.
The combination of skill sets needed to perform this role and the potential for transformational business impact has led it to be labeled the “Sexiest Job of the 21st Century”. Data scientists have also been called unicorns because of the complex variety of skills they need. Since unicorns rarely if ever exist, organizations instead tend to balance the skills across a team of data scientists.
Data Science Techniques
Data scientists have a wide variety of techniques at their disposal and are typically only limited by the quality and quantity of data and processing power.
Today, the most advanced techniques used in data science are grouped under the term Artificial Intelligence (AI) Due to their information-acquiring nature, machine learning, deep learning, natural language processing (NLP) and computer vision are all considered branches within the field of AI. None of these techniques are new. In fact, deep learning was first described theoretically in 1943. But it has taken the availability of low cost, high power compute and memory to make these techniques broadly used.
The most commonly used techniques today are under the umbrella of machine learning. According to the folks at DeepAI, “machine learning is a field of computer science that aims to teach computers how to learn and act without being explicitly programmed.” By this definition, even a logistic regression model qualifies as a machine learning technique. Machine learning techniques can be thought of in three groupings: supervised learning, unsupervised learning and reinforcement learning.
- Supervised learning encompasses techniques such as regression and decision trees that focus on predicting a target variable. Common examples include prediction (of anything) and classification.
- Unsupervised learning doesn’t have a target variable and techniques such as clustering are used to find groups of similar records or behaviors. Common examples include creating customer segments and anomaly detection.
- Reinforcement learning focuses on optimizing a specific decision. The algorithms are trained on past decisions and effectively learn how to optimize the decision through being rewarded for the right choice and punished by the wrong choice. Common examples include recommendation engines and self-driving cars.
The Data Science Toolkit
Data scientists and IT staff leverage tools at all stages of the data science lifecycle (DSLC). This includes accessing and preparing data, building and testing models and deploying them into production. There are many commercial and open-source packages available for a given task. Further, these tools may require the user to write code or use a menu with drag-and-drop. Typically data scientists have preferred tools based on their education, experience and the problem they are tackling. Additionally, new tools and packages are constantly being developed.
Tools that employ drag-and-drop usually have minimal (if any) prerequisites in knowing how to code, but they can also restrict what one can accomplish. On the other hand, writing code requires more prerequisite knowledge yet can yield considerable benefits in optimizing a solution. Drag-and-drop versus coding is like choosing whether to buy a sweater off the rack or knitting it yourself; buying it off the rack is easier but will give a more cookie-cutter result so that the sleeves might be too short or the waistline too long. On the other hand, knitting the sweater takes much more time but allows you to create the exact end product you want.
No matter which type of tool your data science team goes with, the key to success is making sure the tools being used are centrally available, can interoperate, match the skillsets of your team and allow you to build the type of models required to solve your business problem.
The Data Science Lifecycle (DSLC)
The DSLC encompasses the steps a project goes through from ideation to use in the business. in its simplest form has four stages:
- Manage: The manage stage focuses on understanding a project’s objectives and prioritizing tasks to meet time and budget requirements.
- Develop: The develop stage is where data scientists build and assess models and investigate new techniques to improve their previous work.
- Deploy: The deploy stage moves the model into a state where the data can be used within business processes for decision-making.
- Monitor: The monitor stage is the final operational phase of the DSLC, where organizations ensure that the model is delivering on its expected performance.
The Data Science Lifecycle:
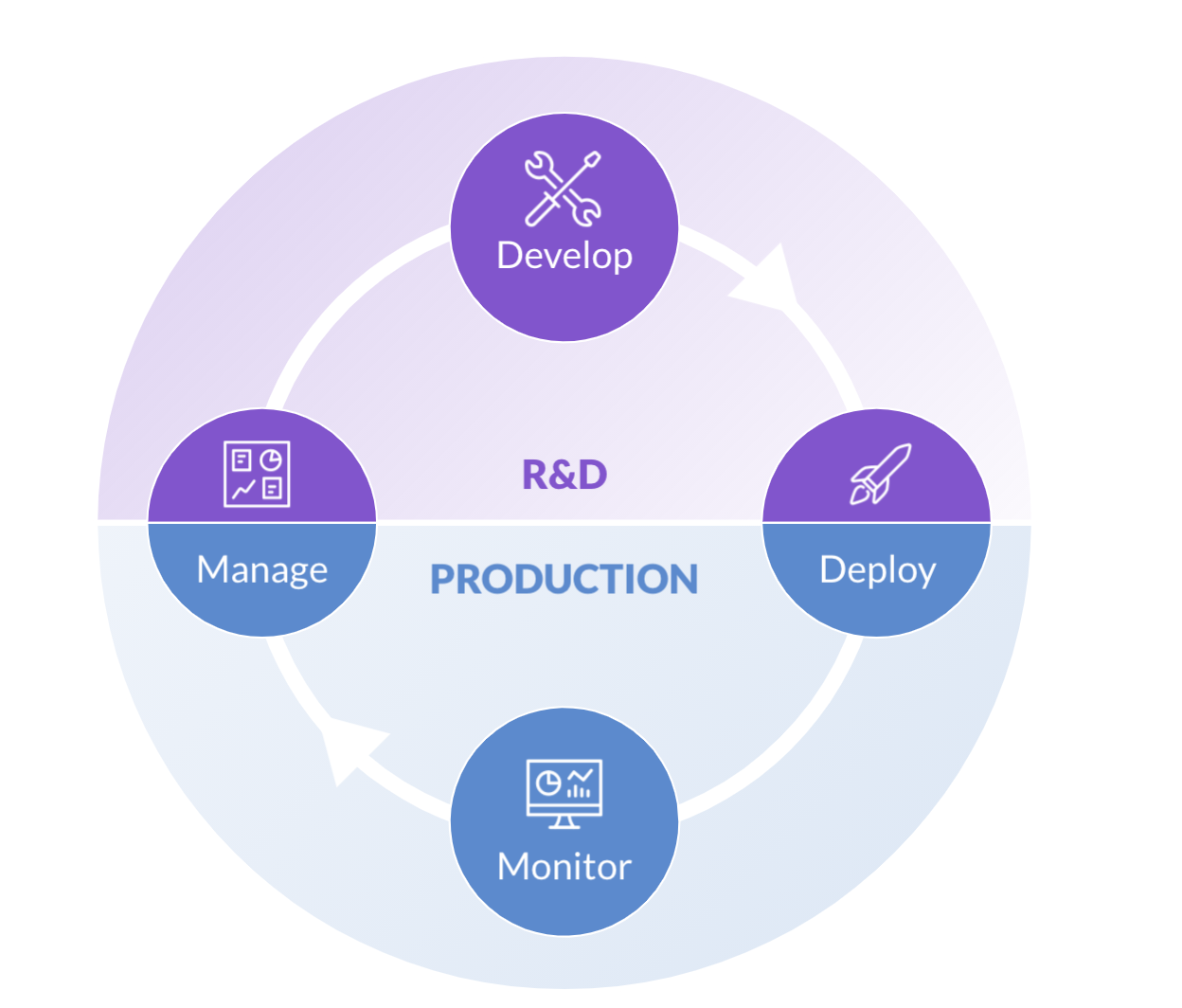
In order to scale data science, the DSLC has to move at high speed, so models can be developed and deployed in days or weeks, rather than months or years. We call that Model Velocity. There are many handoffs that happen from data engineers to data scientists to the business to DevOps engineers, which can slow the process if not properly architected and supported by technology.
Key competencies needed to achieve high model velocity include:
- Effective collaboration between data scientists, IT and the business
- Centralized tooling and compute instantly available to data scientists
- Governance and security across the DSLC
- Standard patterns and practices driven by automation and a system of record for data science
- Knowledge repository
- Visibility into all data science projects
- Monitoring and management of models in production
Data Science with Domino Data Lab
Perhaps too frequently cited as the sexiest job of the 21st century, data science is one of the rare disciplines that deserves the hype; it is multidimensional, interdisciplinary and multifaceted. Data science is truly revolutionizing the way businesses are run and organized, and applications have only become more accurate with advances in technology. Domino helps data science teams thrive by offering a platform that enables them to achieve high model velocity while also ensuring security, governance and reproducibility of data science.
Amanda Christine West is a data scientist and writer residing in Boulder, Colorado. She received her bachelor’s from the University of Michigan and her master’s in data science from the University of Virginia. Within the field of data science, she is most passionate about predictive analytics, data visualization, big data and effective data science communication.

Amanda Christine West is a data scientist and writer residing in Boulder, Colorado. She received her bachelor’s from the University of Michigan and her master’s in data science from the University of Virginia. Within the field of data science, she is most passionate about predictive analytics, data visualization, big data and effective data science communication.
RELATED TAGS
SHARE
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.