Data scientist: Still the “Sexiest job of the 21st century”?




Back in 2012, Harvard Business Review declared: “Data Scientist: The Sexiest Job of the 21st Century.” Authors Thomas Davenport and D.J. Patil (now the U.S. Chief Data Scientist at The White House) devoted much of their article to defining what a data scientist does. Back then, large enterprises were just waking up to the importance that data science could have in unlocking the power of data. As a relatively new discipline, they noted that the demand for data scientists far exceeded its supply, and “the shortage of data scientists is becoming a serious constraint in some sectors.”
Combined, its growing influence and talent shortage that Davenport and Patil predicted have given data science more visibility, especially after the subsequent labor market surveys conducted by Glassdoor. The organization’s widely anticipated annual reports analyze jobs by three factors: 1) median base salary, 2) the number of job openings across U.S. companies, and 3) the overall job satisfaction of employees who hold that position. Not surprisingly, Glassdoor ranked “Data Scientist” as the “Best Job in America” in 2016, 2017, 2018, and again in 2019. Although it has slipped to #3 in 2020, it’s clear that this is still a great time to be a data scientist.
For data scientists, it’s exciting to see salaries, job opportunities, and job satisfaction on the rise. They’ve certainly earned this as data science has become a key differentiator for many Fortune 500 companies and earned data scientists a seat in the boardroom as critical business decisions are being made. But…does the lack of supply that Davenport and Patil predicted eight years ago still hold true? Or, have technology advances and changes in the business environment given companies more opportunities to build a data science team at scale?
A Data Scientist is a Unicorn by Definition
Before we dive into these questions, let’s look at one of the major factors that contributed to the perceived shortage of qualified data scientists in the first place. There are many definitions of data science and what a data scientist is, but no matter the source there’s general agreement that data scientists require three very important sets of skills:
- Math and Statistics. The end-to-end process for data science is deeply rooted in math and statistics. For example, creating understanding from often messy and disparate data requires statistical analysis. And, the techniques that data scientists apply, including all of machine learning, are largely based on mathematical formulas.
- Domain Expertise. Knowledge about a particular industry or department, including its business challenges and respective terminology, significantly increases the likelihood that a data scientist can find (and then solve) the right business problems.
- DevOps. Data scientists have highly specialized needs for data, storage, compute, and more during the R&D phase of their work. Later, they need to apply important DevOps steps to put their models into production.
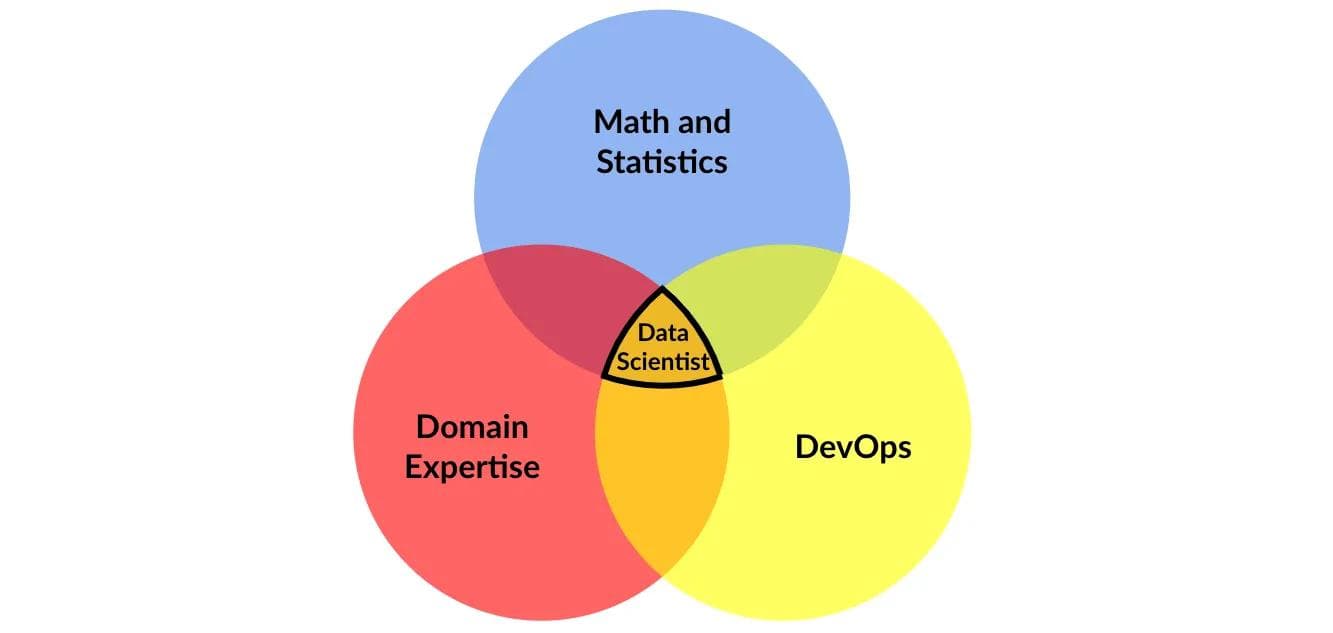
Given the diverse skills that a data scientist has to master, it’s no wonder that companies have had a hard time finding them!
Less DevOps = More Qualified Candidates
On this blog site, we talk a lot about the benefits that a data science platform can bring to organizations that want to scale data science and machine learning. For example, my colleague David Bloch wrote a great blog back in June with some guiding principles about how a company can increase its chance of being successful in its machine learning practices. He mentioned the importance of giving data scientists the freedom of experimentation, backed by a robust process for validating and reproducing new modeling approaches. But, can the presence of a data science platform such as Domino actually help companies improve how they recruit and onboard qualified data scientists in the first place?
Among the many benefits of data science platforms, they give data scientists self-service access to scalable compute for robust experimentation. Powerful resources, including multi-core CPUs, GPUs, and the latest distributed compute frameworks such as Spark and Ray, can be spun up easily with just a few clicks, all without having to know very much about DevOps. Domino will automatically distribute all required packages and dependencies so there are no more DevOps headaches and wasted IT time.
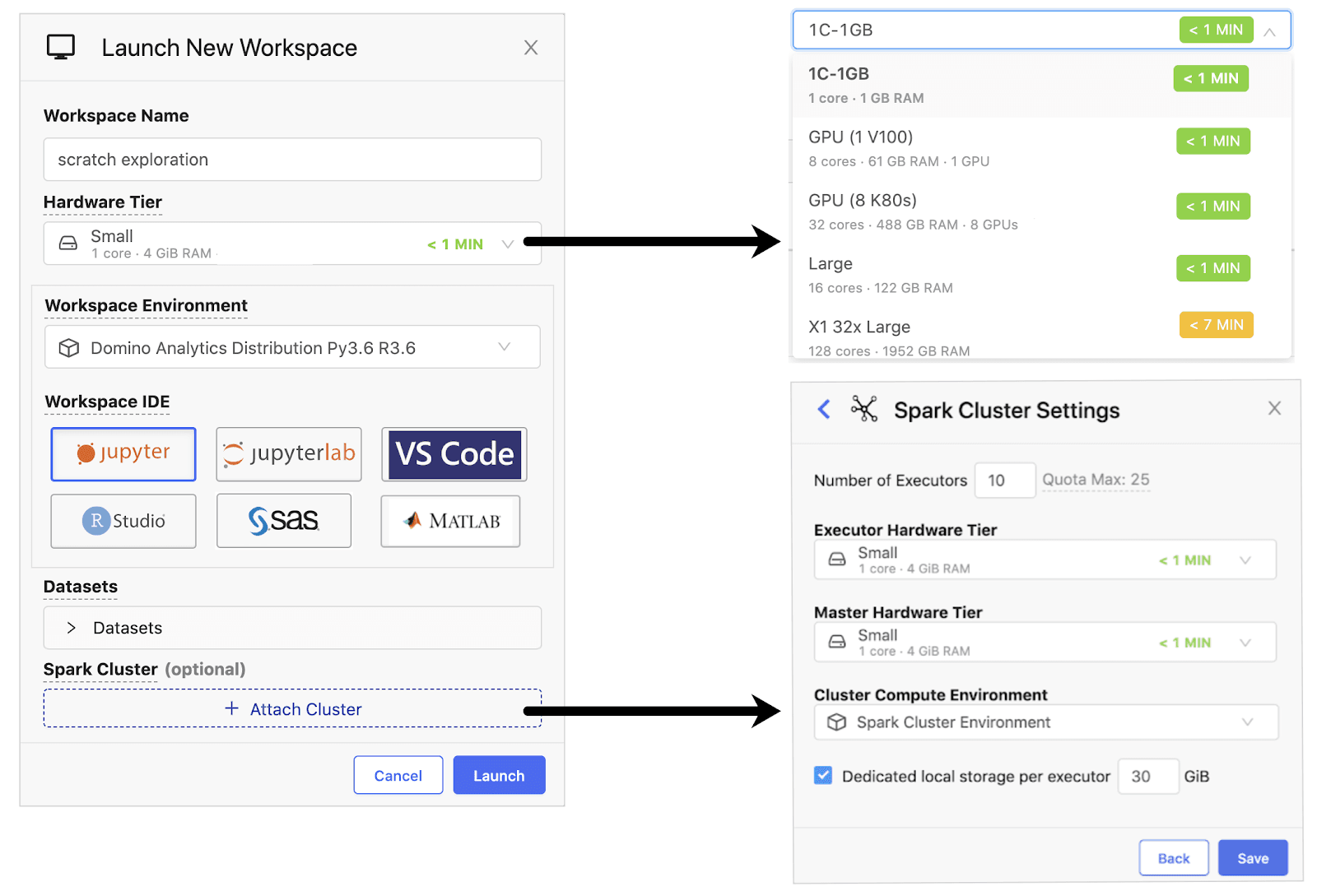
Over the last few years we’ve seen growing concern about the ability of data science models to make it into production where they can add business value. In fact, some estimates have placed the number of models that never reach production as high as 80-90%! In response, any commonly accepted DevOps practices for security, scalability, integration, and more are being applied to the world of models. The resulting systems and processes, which are commonly known as ModelOps or MLOps, seek to get models into production faster as well as overcome the barriers that have traditionally prevented models from reaching deployment.
Some companies have established separate teams to handle the deployment of machine learning models, but we’re also seeing many companies moving to a framework that puts data scientists in charge of the end-to-end process. In these cases, a data scientist has to make the shift from the familiar world of data science and start to work with a new breed of tools (e.g., Kubernetes, Docker, and EC2), constraints and skills.
A data science platform simplifies the deployment process with the ability to put models into production with just a few clicks. For example, you can deploy and host models in Domino using an easy, self-service method for API endpoint deployment. Deploying models within Domino provide insight into the full model lineage down to the exact version of all software used to create the function that calls the model. It also provides an overview of all production assets (APIs, apps, etc.) and links those assets to individuals, teams, and projects so usage can be tracked and assets can be easily reused within other projects.
Data science platforms create an ideal environment for scaling data science, including a wide variety of R&D options and MLOps for data scientists, plus improved governance for IT. They remove the need for data scientists to be masters of DevOps, and allow them to focus more time on data science and less time on overcoming DevOps hassles and fighting with IT. The benefits for data scientists are clear, but for HR recruiting teams, the use of a data science platform removes the requirement to hunt for unicorns. It allows them to focus their search on a much deeper pool of potentially qualified candidates.
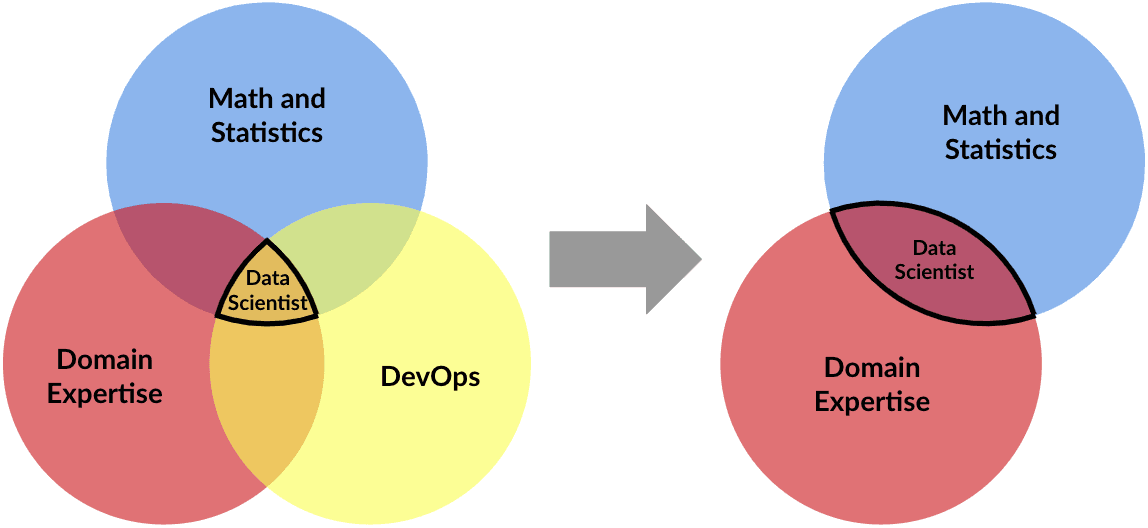
Other Factors When Recruiting a Data Science Team at Scale
Universities have traditionally done a great job at pumping out people with strong math and statistics skills. And now, with data scientists in high demand, there are over 500 universities that provide dedicated data science degree programs. Graduates of these programs enter the workforce with experience working in languages such as Python and R, and are often very familiar with many of the latest open-source packages and tools for data science. In some cases, they even have experience with popular commercial software such as MATLAB or SAS.
Over time these graduates build their domain expertise working closely in a particular field or department with data analysts, business leaders, and other colleagues. They develop an acute understanding about nuances in the data, and instinctively know the right questions to ask so they can develop better models, faster.
Geographic location used to factor heavily into a company’s ability to recruit data scientists. Companies based in areas with high concentrations of data scientists such as San Francisco or New York have deep talent pools to fish in, and could build data science teams with hundreds of data scientists if they wanted to. But, that simply wasn’t a viable option for companies in other parts of the U.S. As companies adapt to new work environments and operating models in response to COVID-19, they are becoming far more open to remote workers. We’re seeing companies in rural areas competing effectively with multinational corporations in large metropolitan areas for data science talent. And, data scientists who live in rural areas have greater opportunities for employment.
We’re also seeing data analysts, software developers, and other non-traditional data scientists using automated machine learning and other tools to expand their skills. These “citizen data scientists” are attempting basic data science tasks as companies seek to apply data science in more facets of their operations. This is a case where supply and demand are increasing simultaneously. In practice, the traditional, code-first data scientists are still working on the same strategic projects they have always had on their plate, but are now taking on the added responsibility of mentoring citizen data scientists plus junior data scientists who are just entering the workforce.
So…Has Supply Caught Up With Demand?
In the eight years since Davenport and Patil wrote their seminal article about data scientists, we’ve seen a dramatic growth both in the number of data science jobs in the U.S., as well as the number of people claiming to be data scientists on LinkedIn. Job site Indeed has reported that data science job postings have more than tripled since 2013, and similar statistics can be found on many other sites. Data skills platform QuantHub did an in-depth analysis in April 2020 and came to the conclusion that job postings were still outpacing job searches by a factor of 3X.
Of course, the emergence of COVID-19 has changed projections about job growth in almost all industries. Data science and other tech jobs have been hit hard, and the gap between demand and supply has narrowed. That said, we’re seeing many of our customers increasing their investment in data science during COVID. Some see data science as a way to further differentiate and create a sustainable advantage, while others see it as their means to survival.
Nobody knows for sure what 2021 will bring, and if “Data Scientist” will once again be near the top of the “Best Job in America” list. But, if past history and the signs we’re seeing from our customers are any indication, I’d bet on data scientists.