Comparing the functionality of open source NLP libraries




In this guest post, Maziyar Panahi and David Talby provide a cheat sheet for choosing open source NLP libraries.
What do natural language processing libraries do?
Natural language processing (NLP) is essential in a growing number of AI applications. Extracting accurate information from free text is a must if you are building a chatbot, searching through a patent database, matching patients to clinical trials, grading customer service or sales calls, extracting facts from financial reports or solving for any of these 44 use cases across 17 industries.
To build such systems, your software must understand the vocabulary, grammar and semantics of the text's human language. It needs to know how sentences are composed – so that the period in “It’s $7.25 per hour” doesn’t start a new sentence. It needs to know how verbs are conjugated – to infer whether a breach of contract has happened, will happen or might happen. It needs to know how negation is expressed – to understand if a patient is or is not diabetic. It even needs to understand social context -- to deduce whether a message saying “get lost” is a violent threat or a friendly jab between buddies.
A good NLP library will, for example, correctly transform free text sentences into structured features (like cost per hour and is diabetic), that easily feed into a machine learning (ML) or deep learning (DL) pipeline (like predict monthly cost and classify high risk patients). Other use cases may involve returning the most appropriate answer to a question, finding the most relevant documents for a query or classifying the input document itself. A good NLP library will make it easy to both train your own NLP models and integrate with the downstream ML or DL pipeline.
A good NLP library should also implement the latest and greatest algorithms and models – not easy while NLP is having its ImageNet moment and state-of-the-art models are being outpaced twice a month. It should have a simple-to-learn API, be available in your favorite programming language, support the human languages you need it for, be very fast, and scale to large datasets including streaming and distributed use cases.
Did we mention that it should also be free and open source?
The open source NLP shortlist
This post aims to help you choose the right open source NLP library for your next project. We assume that you need to build production-grade software. If you are in research, excellent libraries like Allen NLP and NLP Architect are designed to make experimentation easier, although at the expense of feature completeness, speed and robustness.
We assume that you are looking for widely used, proven-in-the-field NLP libraries that are in production – code that just works because many others have tested it already. You’re also looking for a library with an active community – one that can answer your questions, resolve bugs and most of all keep adding features and improving accuracy and speed. We’ve therefore narrowed the shortlist to these five libraries:
Obviously, there are many more libraries in the general field of NLP – but we focus here on general purpose libraries and not ones that cater to specific use cases. For instance, gensim is a popular NLP library that was initially created for topic modeling and cannot be used to build a full NLP Pipeline.
More specifically, our shortlist only includes libraries that provide this core feature set:
- Sentence detection
- Tokenization
- Stemming
- Lemmatization
- Part of speech (POS)
- Named entity recognition (NER)
- Dependency parser
- Training domain-specific models
They also provide some or all of these features:
- Spell checking
- Sentiment analysis
- Text matcher
- Date matcher
- Chunking
- Other features
All five of the libraries compared here have some notion of an NLP pipeline that can be defined – since most NLP tasks require combining several of these features to get a useful result. These can be either classical or deep-learning-based pipelines.
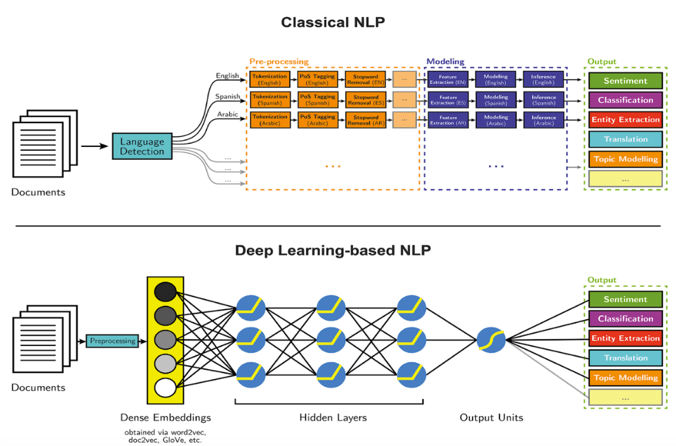
Image Credit: Parsa Ghaffari on the Aylien Blog
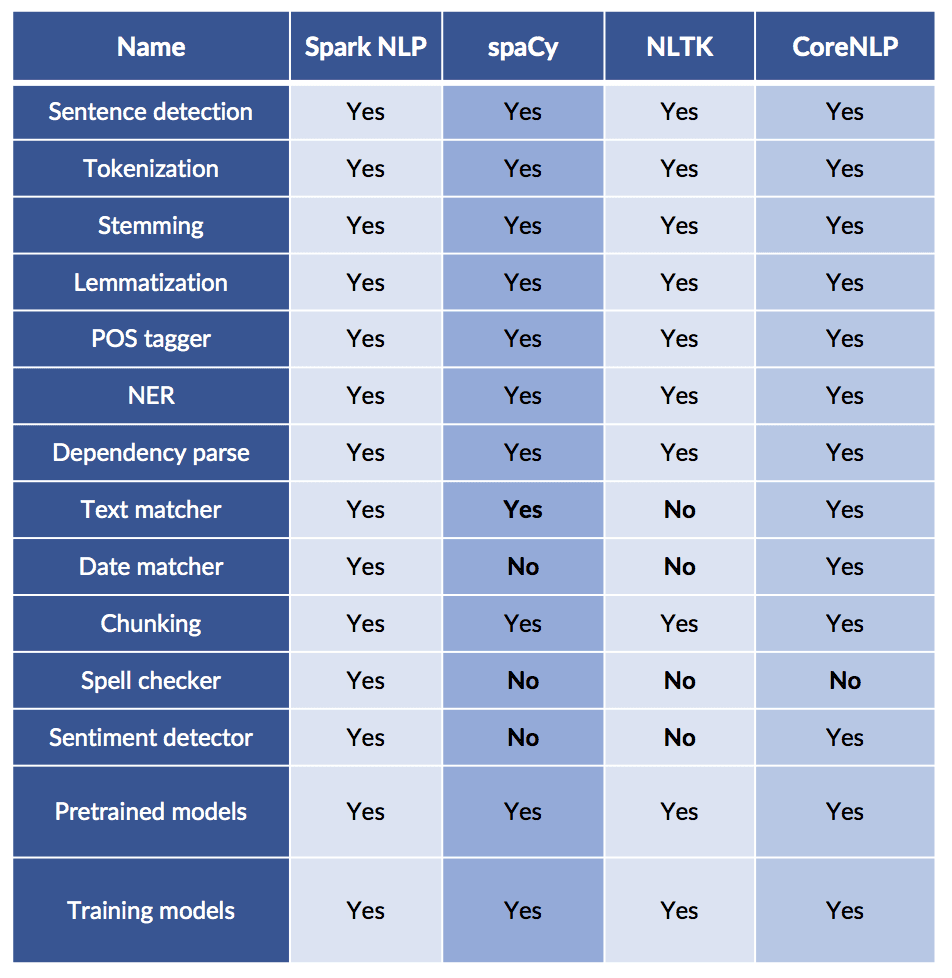
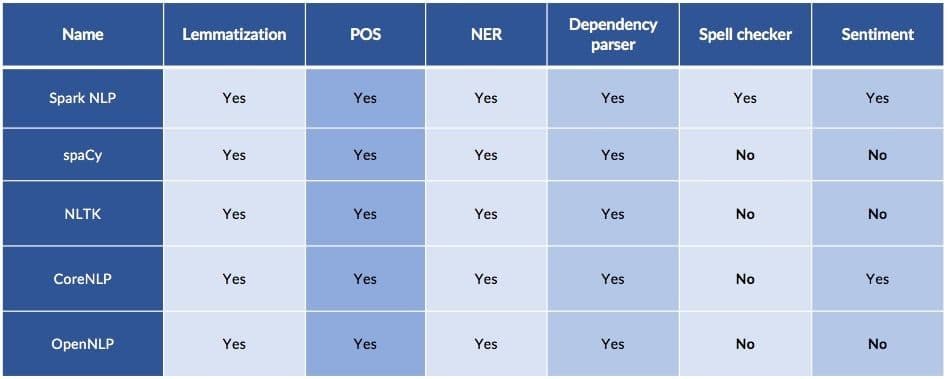
Functionality comparison cheat sheet: sPacy vs. NTLK vs. Spark NLP vs. CoreNLP
This is how the functionality of the most popular NLP libraries compares:
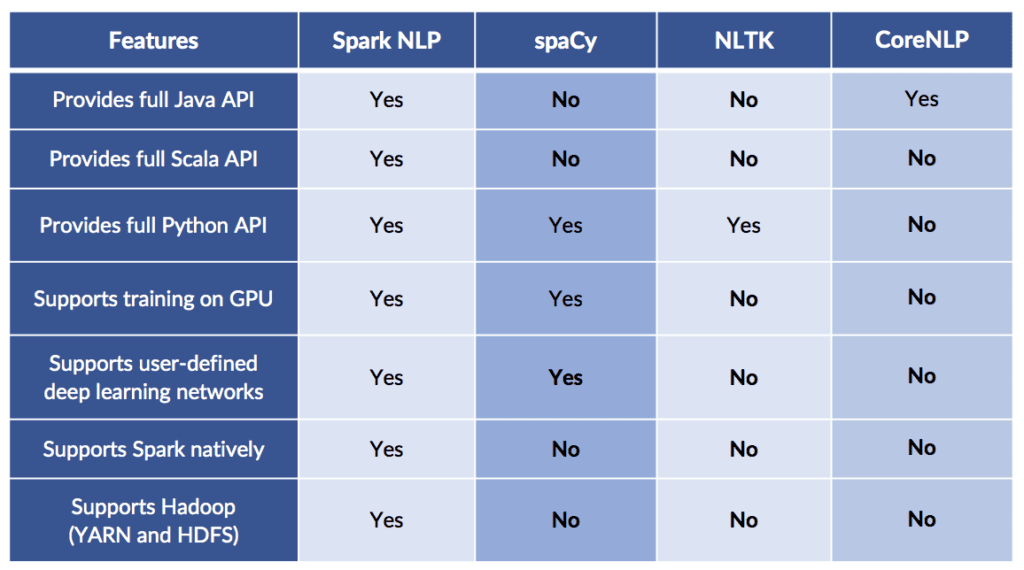
Here is the comparison of technical functionality – the support for modern compute platforms and popular programming languages:
Licensing and support
Open Source doesn’t mean the same thing everywhere – for example, Stanford’s CoreNLP requires a paid license for commercial use, and that license still doesn’t provide commercial support with defined SLAs. Teams looking to build commercial, production-grade NLP solutions need both an active community that keeps improving the core library, as well as the option of paid enterprise-level support.
This is how the libraries compare on licensing and support:
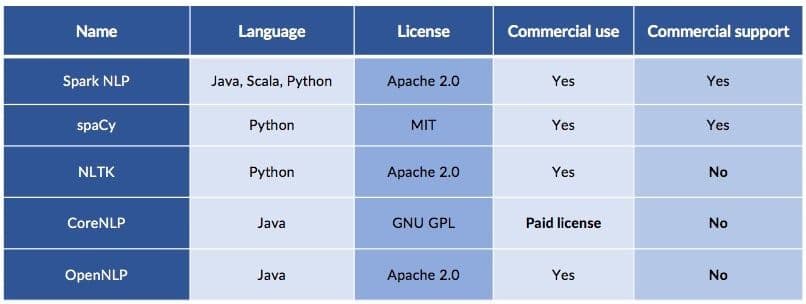
Stanford sells commercial licenses for CoreNLP which are required for commercial use of the library. Commercial licenses and support for spaCy are provided by explosion.ai which also licenses prodigy for fast annotate-and-iterate cycles and the thinc machine learning library. John Snow Labs provides Spark NLP Enterprise which includes onboarding, 24x7 support and premium features such as entity resolution, assertion status detection and de-identification. It also provides Spark NLP for Healthcare which includes a suite of healthcare-specific, state-of-the-art models and datasets for biomedical NLP.
Pretrained models
Although most NLP libraries support training new models by users, it is important for any NLP library to ship with existing pretrained, high-quality models. However, the majority of NLP libraries only support generic pretrained models (POS, NER, etc.). Some won’t allow their pretrained models to be used for commercial purposes because of how models are licensed.

Here are the general pretrained models that come packaged with each of the libraries:
Not all open source NLP libraries are created equal. Not all of them can be used for your project, given your programming language, platform, license and support needs. This article is intended to be a useful cheat sheet for narrowing down your choice. Please help us keep it up to date by telling us when you learn about new libraries or releases that should be reflected here.
Beyond functionality, your next criteria are comparing accuracy, speed and scalability. Good luck in your NLP endeavors!