Domino 4.6: Greater Confidence & Flexibility for Model-Driven Businesses
Bob Laurent2021-09-16 | 10 min read

Over the last five years, data science has become significantly more complex:
- The volume of data that data scientists have to work with has increased exponentially
- The techniques data scientists use have become so computationally intensive that they require multi-core CPUs, GPUs, and distributed compute
- Models are being relied upon to support the most critical business decisions, with a much higher volume of predictions on a daily basis
Whereas a data scientist was once able to develop and run code locally on their laptop, today they often need a lot more infrastructure to be successful. More infrastructure typically means more requirements for complex DevOps work and wasted time for data scientists. And, with more and more companies becoming model-driven, data scientists are finding they need to allocate even more time to monitoring models in production or risk putting their CIO on the cover of The Wall Street Journal — for all the wrong reasons.
Introducing Domino 4.6
Thankfully, Domino users may not be able to relate to the infrastructure and model monitoring challenges that their peers face on a daily basis. We introduced our next-generation data science workbench in Domino 4.4, and today we’re unveiling Domino 4.6 with additional options for enterprise-scale model monitoring, choice of distributed compute, and a host of other innovations and improvements that I’m excited to be able to share with you. As you’ll see in a moment, Domino 4.6 is all about providing:
- More confidence in the models running your business, at scale across hundreds of features and billions of predictions per day
- Increased flexibility for data scientists to have self-serve access to the best tools and infrastructure for the task/project at hand, including Ray.io and Dask distributed compute
- A seamless user experience to accomplish the important work that data scientists need to do, in a way that is consistent, fully integrated, and aligned to best practices
Enterprise-Scale Model Monitoring
A recent survey by Wakefield Research and Domino Data Lab revealed that 82% of data executives at large US companies (greater than $1 billion in annual revenue) say their company leadership should be concerned that bad or failing models could lead to severe consequences for the company. And yet, another recent survey by DataIQ revealed that nearly 27% of business leaders rely on ad-hoc processes for model monitoring, or just don’t know how models are reviewed. Only 10% use automated model monitoring capabilities to help them ensure that the models running critical business functions reflect today’s current, and fast-changing, business environment.
It’s with these challenges in mind that we’re excited to announce our new Domino Elastic Monitoring Engine. This groundbreaking technology advancement allows Domino Model Monitor (DMM) to compute data drift and model quality across billions of daily predictions – more than 100x the scale of previous versions!
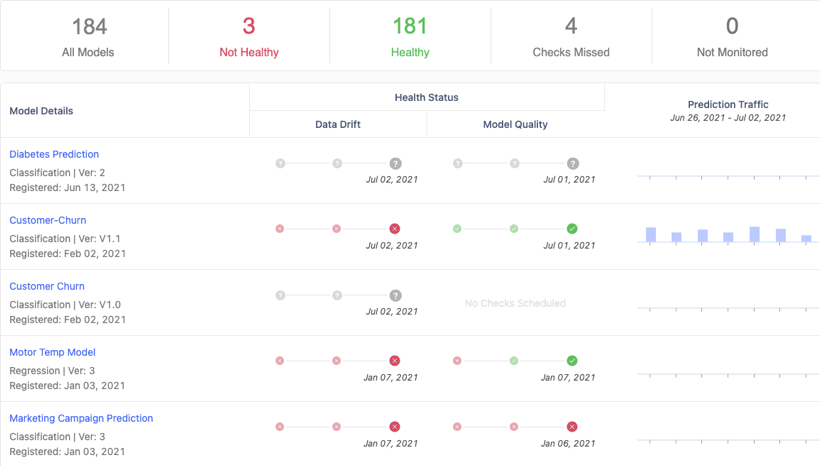
DMM can now scale model monitoring capacity infinitely to support the most demanding monitoring requirements. It can ingest and analyze massive volumes of data from Amazon S3 and Hadoop Compatible File Systems (HCFS), which include Azure Blob Store, Azure Data Lake (Gen1 and Gen2), Google Cloud Storage, and HDFS. There’s no need to copy data between storage locations so data can be analyzed immediately, without concerns over version control, security, and other issues that could call model accuracy into question.
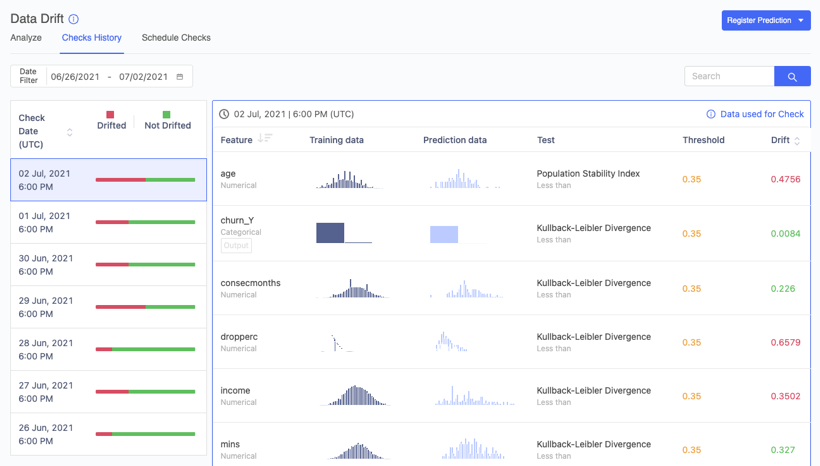
If you’ve been putting off adding automated model monitoring, you jeopardize your company’s reputation, competitiveness, and most of all, its bottom line. So, here’s another incentive. With Domino 4.6, DMM can be installed in any environment alongside our core product, including all of the major cloud platforms (AWS, GCP, and Azure), and on-premises if that’s more your thing. And with Single Sign-on (SSO) and other integrations across the entire Domino Enterprise MLOps platform, users are in store for a seamless experience, from model development to deployment to monitoring.
Choice of Distributed Compute
Choice and the ability to use the best tool for a particular job is extremely important for data scientists. That’s why a guiding principle for Domino over the years has been to embrace the best open-source and commercial tools, packages, languages, data sources, and more — and incorporate them into Domino in a way that eliminates the typical DevOps challenges. This philosophy extends to distributed compute environments where we have supported ephemeral Spark for over a year to give data scientists an extremely easy way to add Spark to their workspace environments.
With Domino 4.6, we’re adding support for both on-demand Ray and Dask – two of the hottest forms of distributed compute that have emerged from the open-source community. If you’re not familiar with distributed compute, it allows data scientists to process large volumes of data for machine learning and other complex mathematical calculations such as deep learning. Both frameworks leverage state-of-the-art machine learning libraries to make it easy to scale single machine applications to solve more powerful machine learning problems, with little or no changes to the underlying code.
At the heart of Ray is a set of core low-level primitives (Ray Core) that offer tremendous value for distributed training, hyperparameter tuning, and reinforcement learning. Ray has been adopted as a foundational framework by many open source ML frameworks which now have community-maintained Ray integrations. Dask also offers a number of integrations with existing data science libraries to make it an excellent choice for parallelizing existing Python-based data science code with minimal adaptation. It’s a particularly good choice for computations that make heavy use of manipulating large amounts of data using the Pandas and NumPy libraries or the Scikit-learn training interface. For more information about the pros and cons of Ray and Dask as compared to Spark, check out this recent blog.
It’s extremely easy to add Ray and Dask clusters (or Spark for that matter) when spinning up a workspace in Domino. All a user has to do is specify a handful of parameters, such as the number of workers and the capacity of each worker. From there, Domino will do all of the heavy lifting behind the scenes to set up the cluster on the underlying Domino infrastructure, establish networking and security rules, and automatically manage the cluster throughout its lifecycle. No DevOps experience is required!
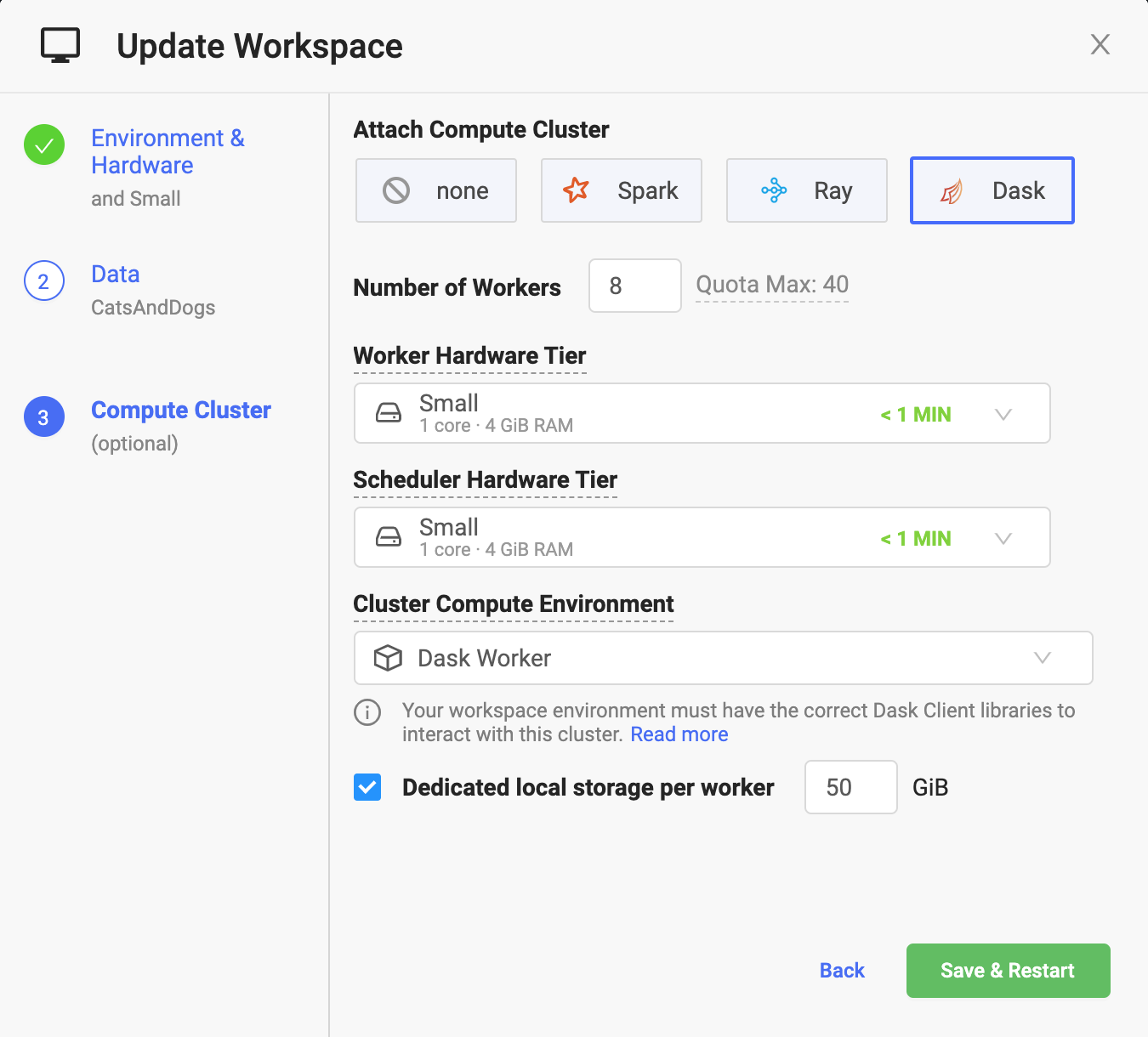
Domino’s DevOps-free support for the three most popular distributed compute frameworks at true enterprise scale is an industry first. It’s all part of our commitment to data science teams to allow them to select the best framework (and tool in general) for the job at hand – without being limited to the single choice dictated by other platforms or having to rely on IT to create and manage the cluster.
More Exciting Enterprise MLOps Capabilities
We’re proud and honored to have over 20% of the Fortune 100 rely on Domino to help them overcome infrastructure friction, collaborate more easily, and help get models into production faster. But with that comes a responsibility to continue to innovate in ways that address many of the unique needs of our enterprise customers.
Additional features in Domino 4.6 include:
- Domino certification of Amazon EKS. We’ve incorporated Amazon’s managed Kubernetes offering, Amazon EKS, into our “Certified” family of highly secure, comprehensively tested, and performance-optimized Domino offerings. With this release, we are enabling cloud-native customers to leverage Amazon EKS to run Domino with the highest levels of confidence and operational performance. The investments they have already made in training people, setting up best practices in infrastructure management, etc. can all be leveraged to streamline the Domino installation and future upgrades.
- Git Repository Creation & Browsing. In Domino 4.4 we announced the ability for users to synchronize data science code with Git-backed repositories (e.g. GitHub, GitLab, and Bitbucket) and align their work with existing CI/CD workflows to improve compliance and governance. We’ve taken that ability to the next level with native support for creating new Git repositories. Users can browse content up and down the Git tree and view the commit history – all without leaving the familiar Domino GUI environment.
- Read/Write Domino Datasets with Snapshots. Domino Datasets provide high-performance, versioned, and structured filesystem storage across the entire Domino platform. Users can now create ‘Snapshots’ – curated collections of large amounts of data for a project – and share them seamlessly with co-workers to preserve the reproducibility of experiments.
Wrap up
Domino 4.6 is the culmination of lots of user research and development work, and I can’t wait for you to get your hands on it. If you’re an existing Domino customer, you can upgrade to Domino 4.6 immediately. But if not, you can experience all of the Enterprise MLOps power that Domino has to offer during a free, 14-day trial.

Bob Laurent is the Head of Product Marketing at Domino Data Lab where he is responsible for driving product awareness and adoption, and growing a loyal customer base of expert data science teams. Prior to Domino, he held similar leadership roles at Alteryx and DataRobot. He has more than 30 years of product marketing, media/analyst relations, competitive intelligence, and telecom network experience.
RELATED TAGS
SHARE
Other posts you might be interested in



Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.