Build, Deploy, and Monitor Models in Snowflake




Introducing End-to-End Data Science with Snowflake Snowpark
By Vinay Sridhar, Senior Product Manager at Domino, on June 13, 2022, in Product Updates
Increasing pressure on data science teams to build models that improve decision-making and drive business outcomes means playtime for data scientists is over. Building a model-driven competitive advantage starts with data, and Snowflake is now the canonical data store.
Data science teams innovate the most when they focus on building, deploying, and monitoring breakthrough models, iterating quickly to maximize prediction accuracy. The distracting complexities of data and infrastructure access create silos and prevent effective collaboration.
Orchestrating the movement of data takes custom development work and introduces manual workarounds, increasing risks for data scientists and ML engineers. Moreover, if production data is not co-located with models, performance degradation creates bottlenecks.
Domino and Snowflake have addressed these challenges by combining the flexibility of Enterprise MLOps in Domino with the scalability and power of Snowflake’s platform for in-database computation. Customers can develop models in Domino, train them in Snowflake using Snowpark, then deploy models directly from Domino into the Snowflake Data Cloud for in-database scoring, accelerating time to value.
The rise of in-database scoring comes with many advantages, namely simplified enterprise infrastructure with a common platform across IT and data science teams, resulting in:
- Simplicity. Typical Snowflake use cases operate at a large scale with high volumes of data. Moving data from Snowflake to where your model is deployed and writing predictions back to Snowflake requires complex data pipelines that can be difficult to build and manage.
- Better performance. Moving such large volumes of data in and out of the Snowflake server can be expensive and impacts overall performance. Complex DB engines like Snowflake optimize for proprietary data formats which can be used during ML inference that can give a performance edge over a general purpose compute platform.
How to Build Models with Snowflake and Domino
Domino offers a native integration with Snowflake such that Domino users can select Snowflake as a datasource. This is a newer capability than using environment variables or user credentials directly within their Domino workspaces.
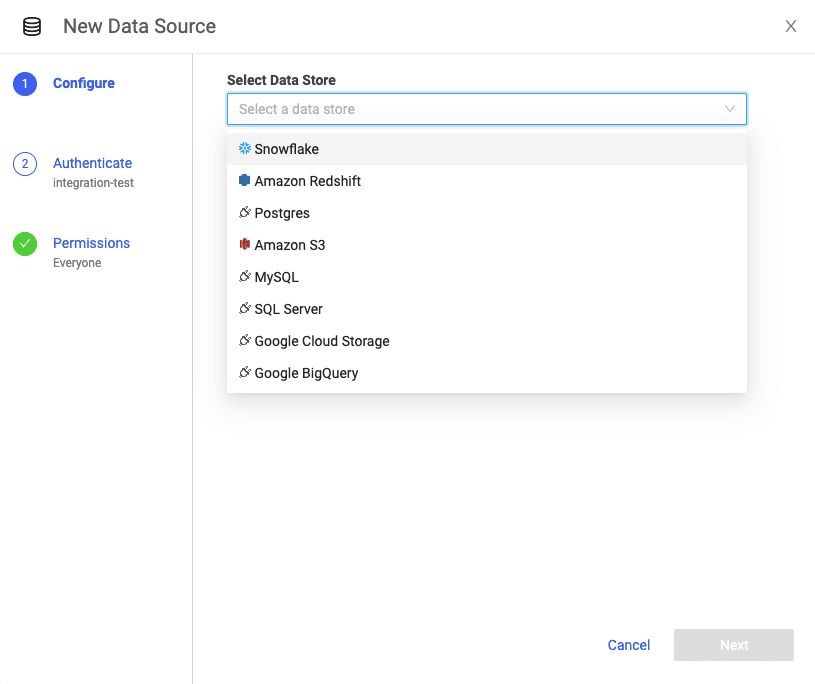
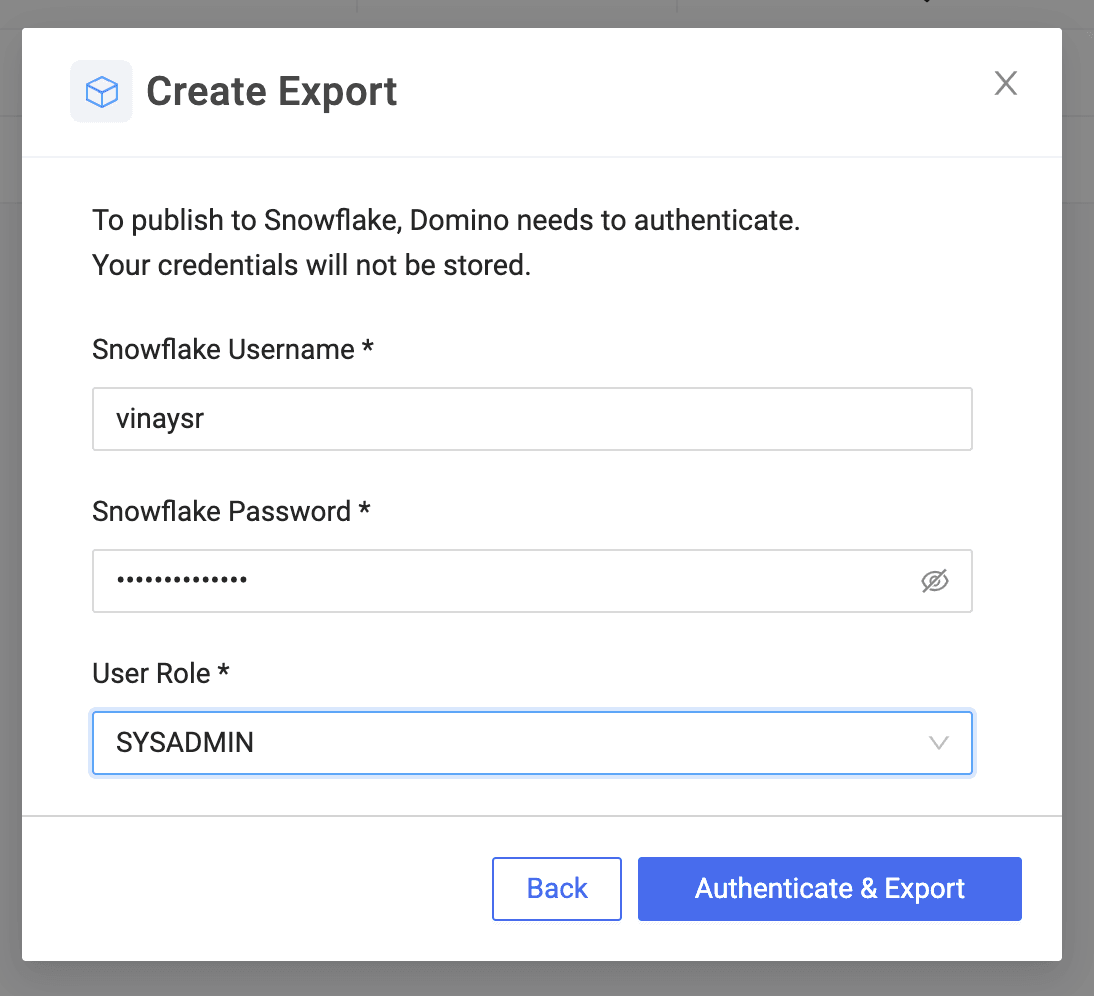
After selecting Snowflake as a datasource, users have the option to either 1) enter their Snowflake credentials or 2) select OAuth, an open-standard protocol that allows supported clients authorized access to Snowflake without storing user login credentials. Note: OAuth has to be pre-configured by a Domino administrator for users to have the option to select it.
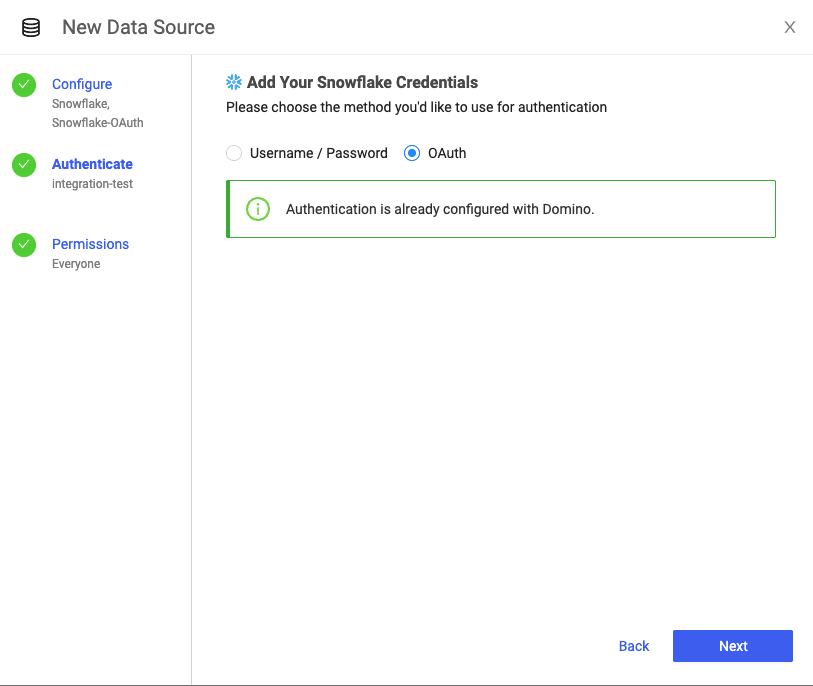
Once Domino is connected to Snowflake’s Data Cloud, data scientists can leverage Snowpark libraries to quickly build models. Snowpark lets users build applications (using a high level language like Python, Scala, or Java), optimized to run in Snowflake compute environments - where the data resides.
How to Use a Snowpark UDF to Deploy Models Built in Domino
The core abstraction in Snowpark is the DataFrame, so in addition to using the built-in capabilities in Snowpark libraries, Domino users can also create user-defined functions (UDFs) for ML inference using native Domino interfaces. Both the DataFrame and UDFs are optimized to execute asynchronously on the Snowflake server.
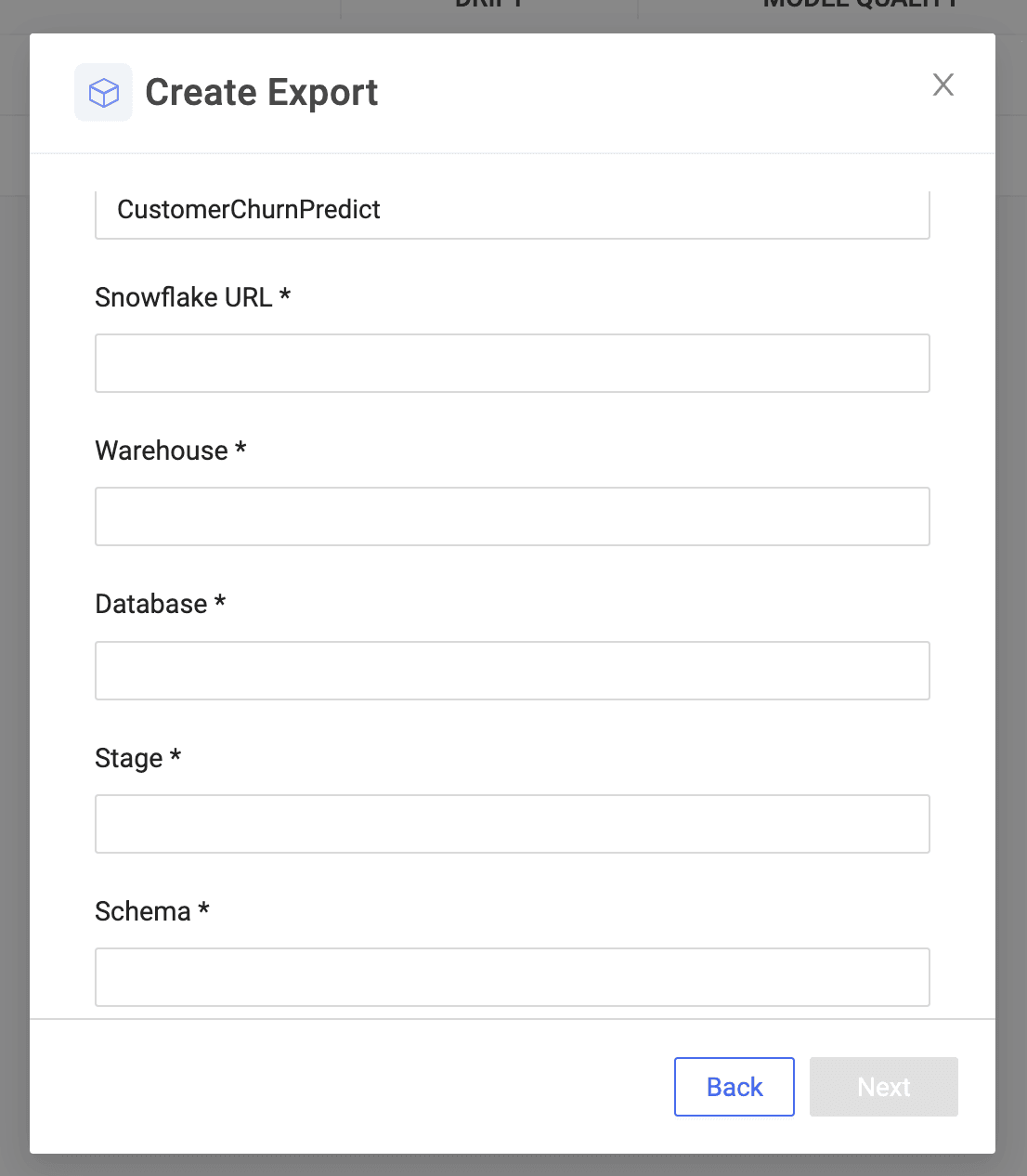
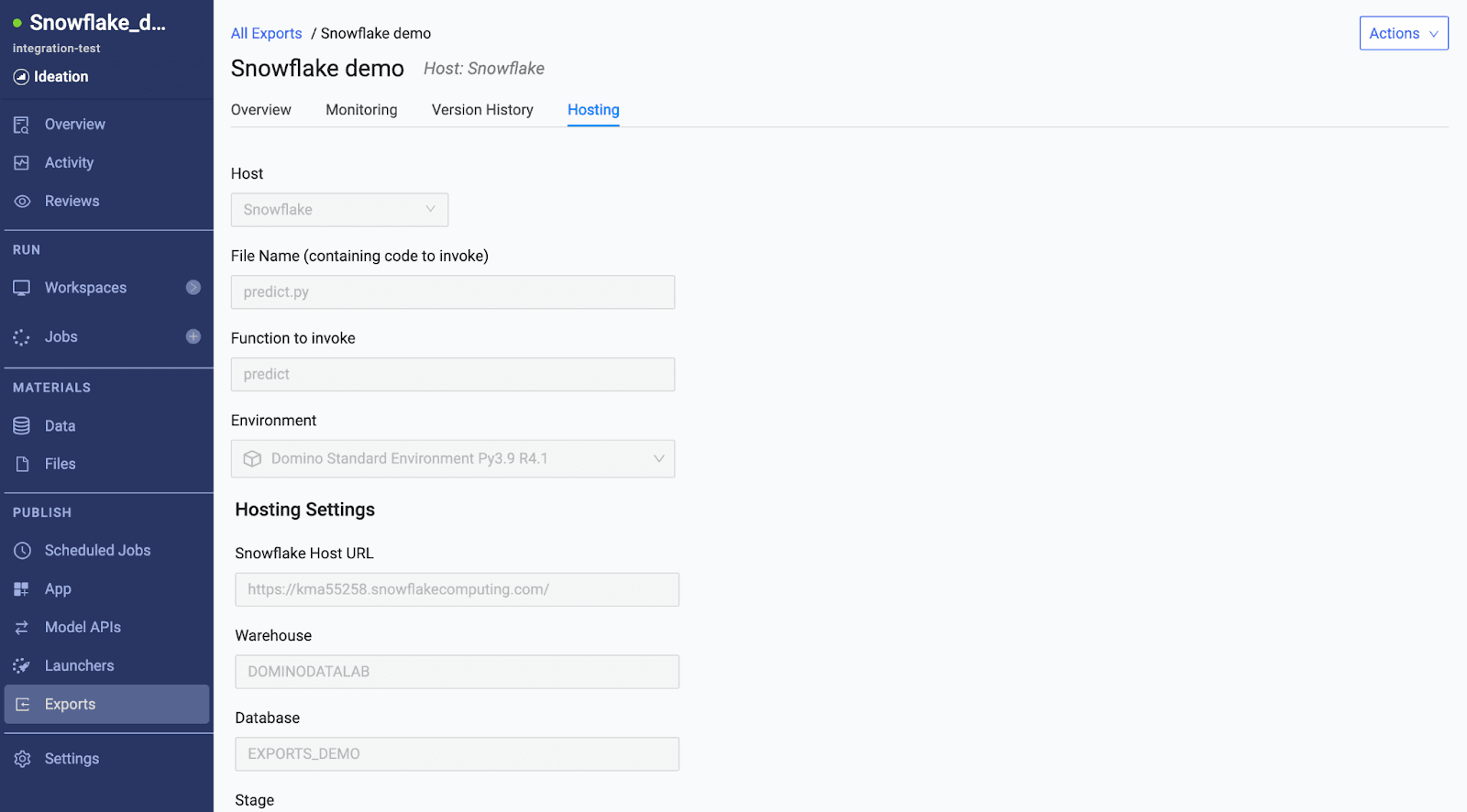
With a simple UI, you can select the file and prediction function that invokes the model built in Domino. This is the function that will be registered as a Snowpark UDF that can be used inside Snowflake applications or in SQL queries to run batch scoring.
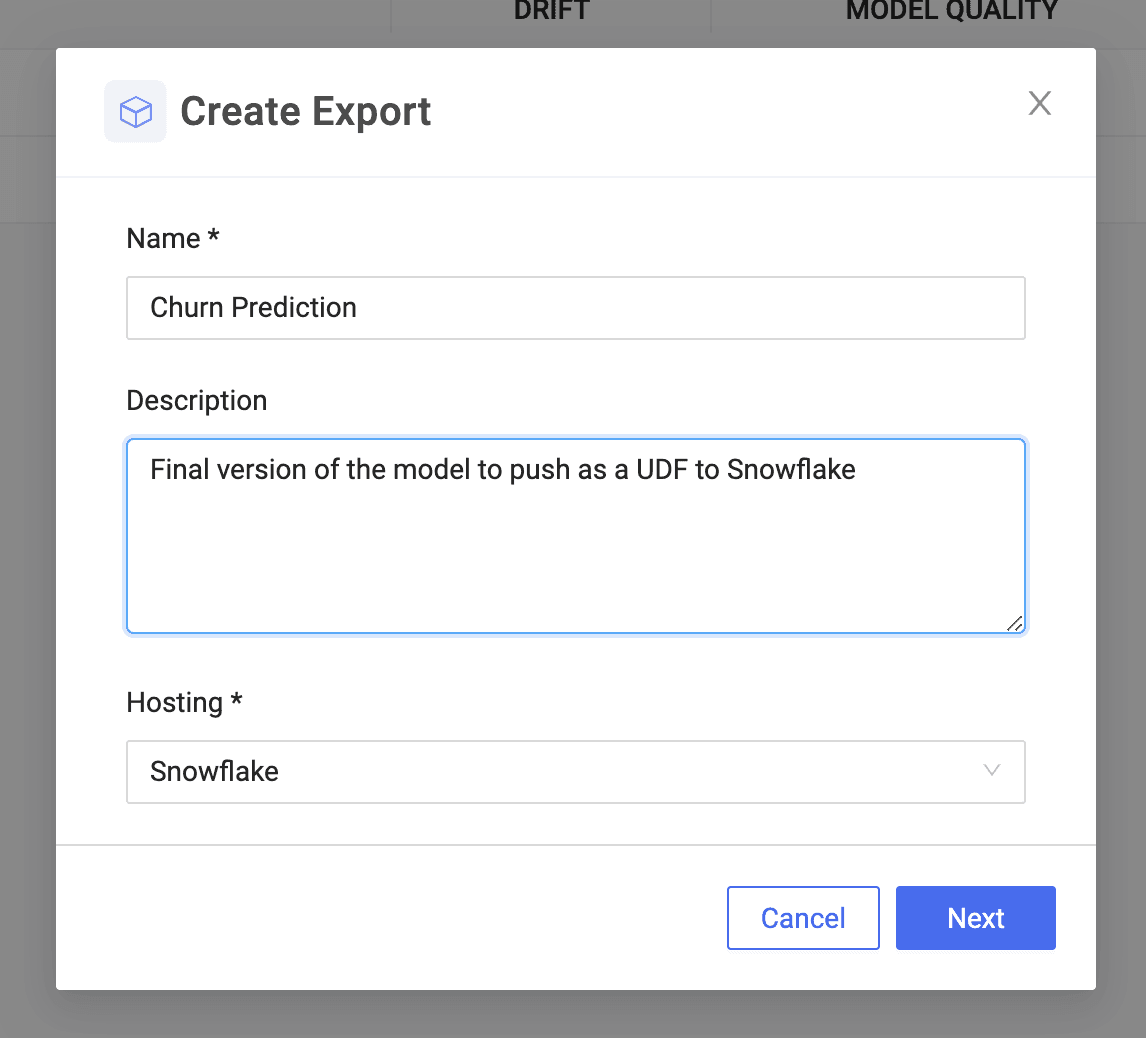
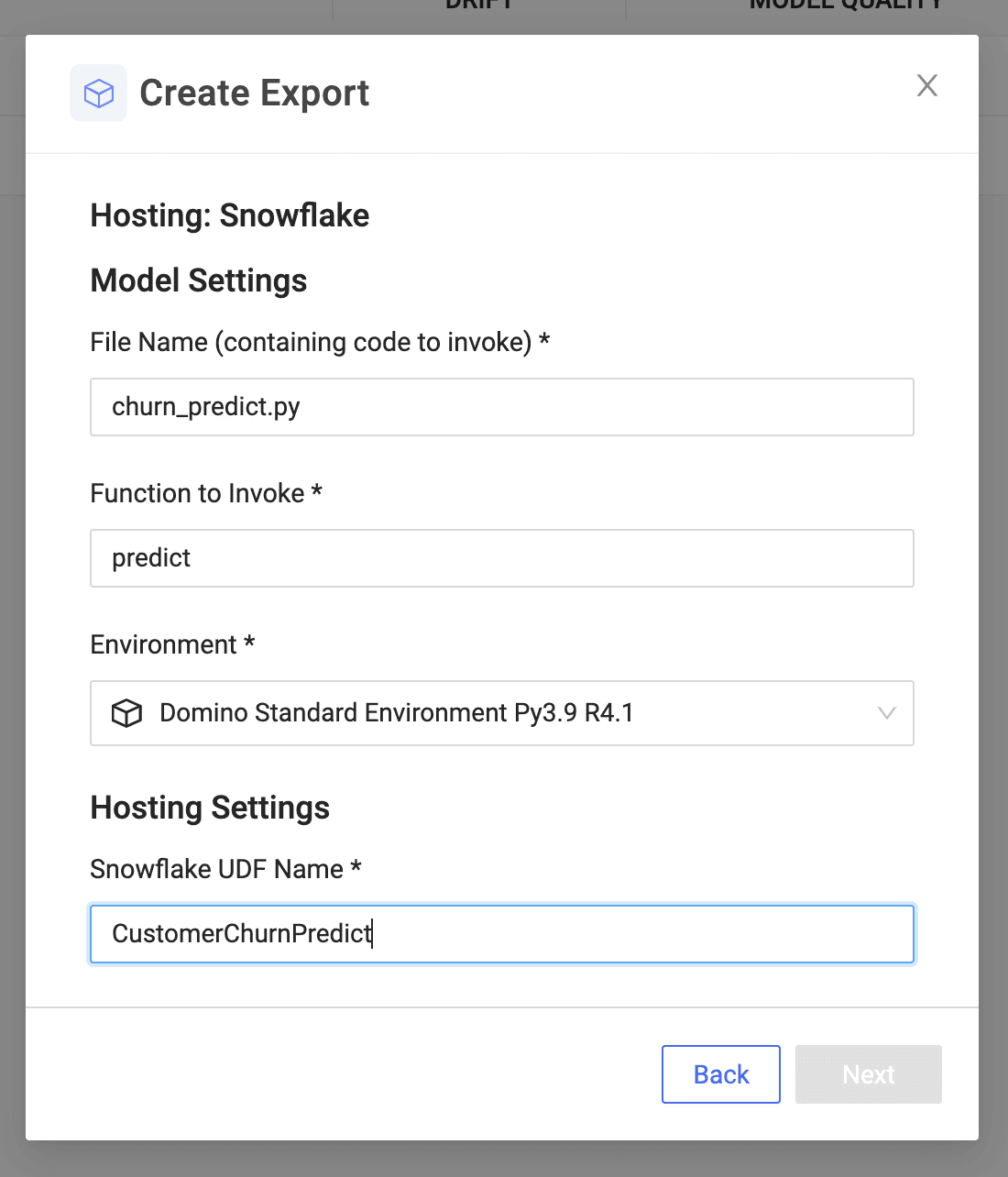
Once you specify Snowflake server settings, Domino persists the model, package dependencies ,and necessary files in Snowflake and registers the UDF.
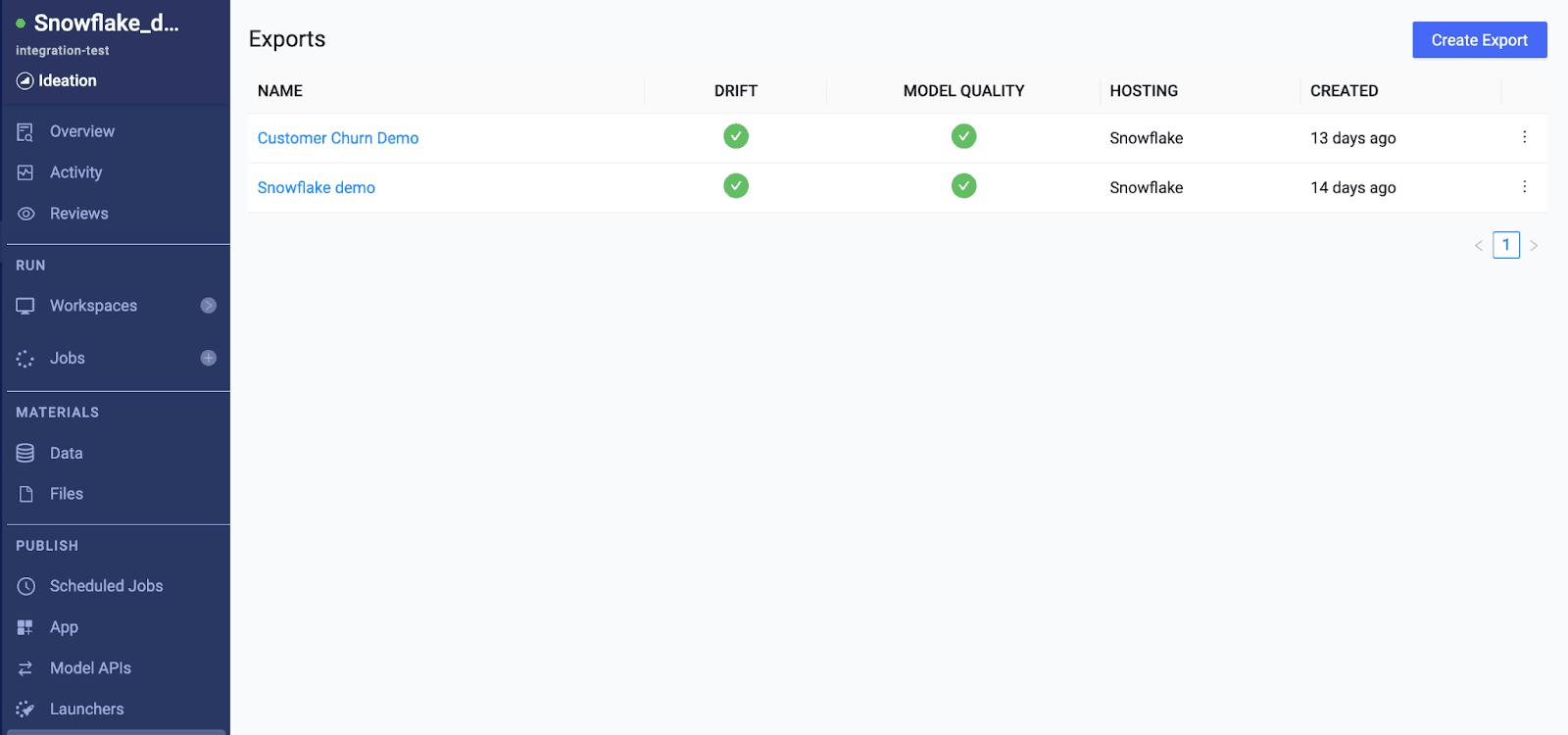
You can view all exported models in Domino’s Export Catalog. With a single pane of glass, all exports and their model performance indicators are shown, in addition to a host of other details including the hosting settings, metadata, and monitoring information if configured.
You can invoke Snowpark UDFs from within a Snowflake SQL query. In this example, the command invokes a customer churn prediction model via the inference code - both built in Domino - exported as a UDF in Snowflake.
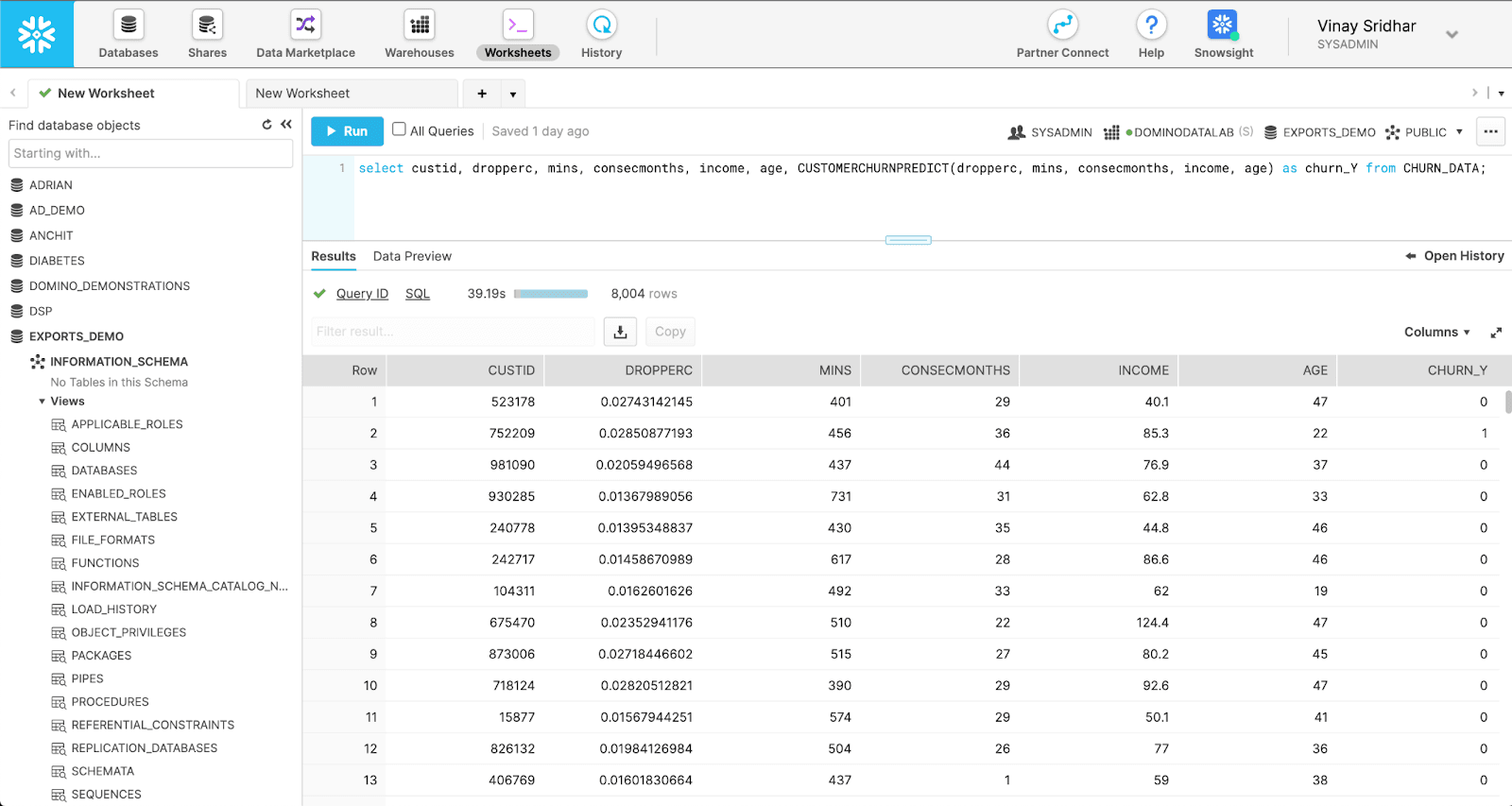
How to Configure Domino Model Monitoring
Back in Domino, you can configure model monitoring with a few easy steps. Once you select the training dataset and inform Domino about the table that contains the prediction output, Domino automatically fetches data from this table each time a new batch of prediction is made and computes drift metrics.
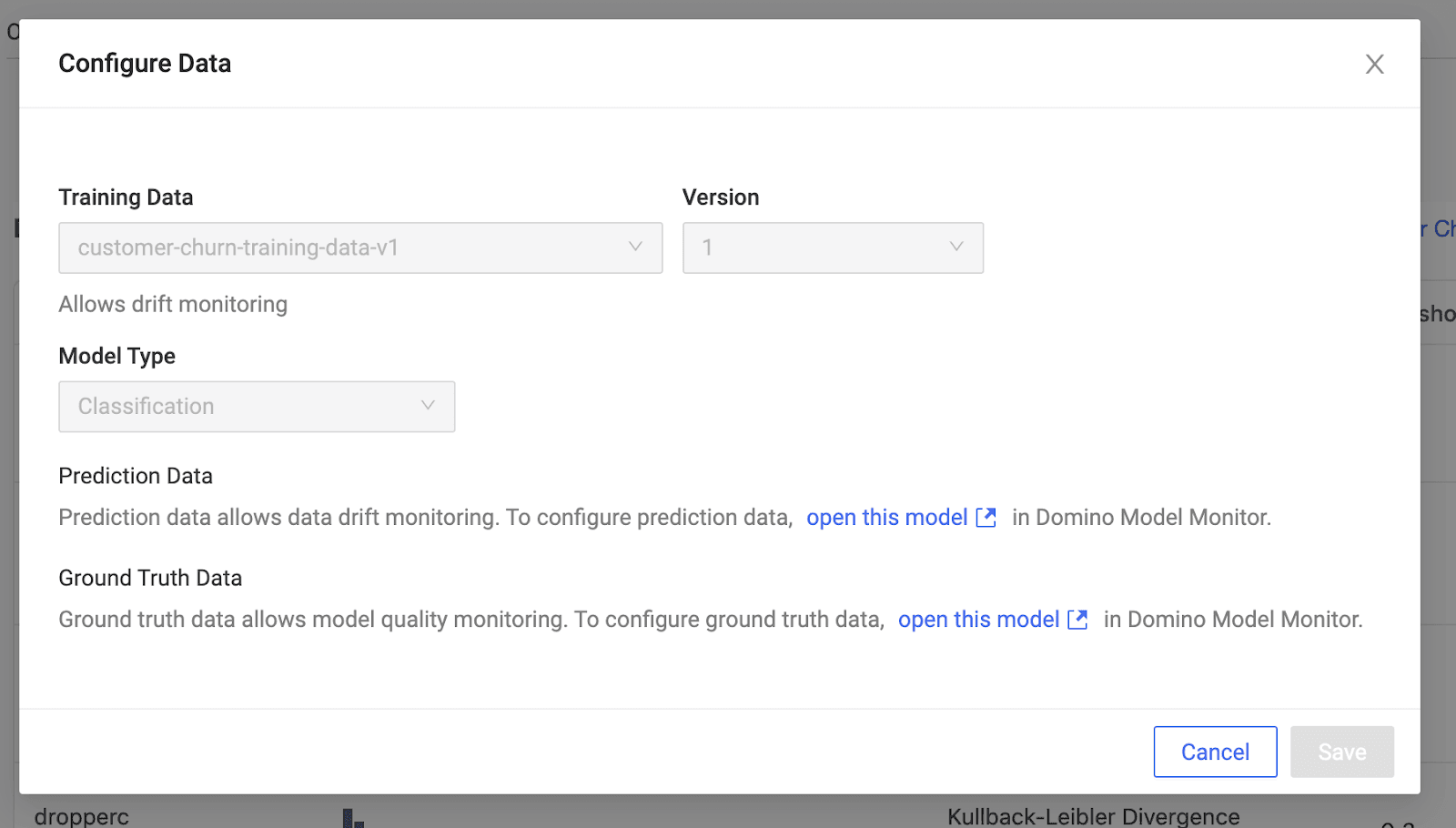
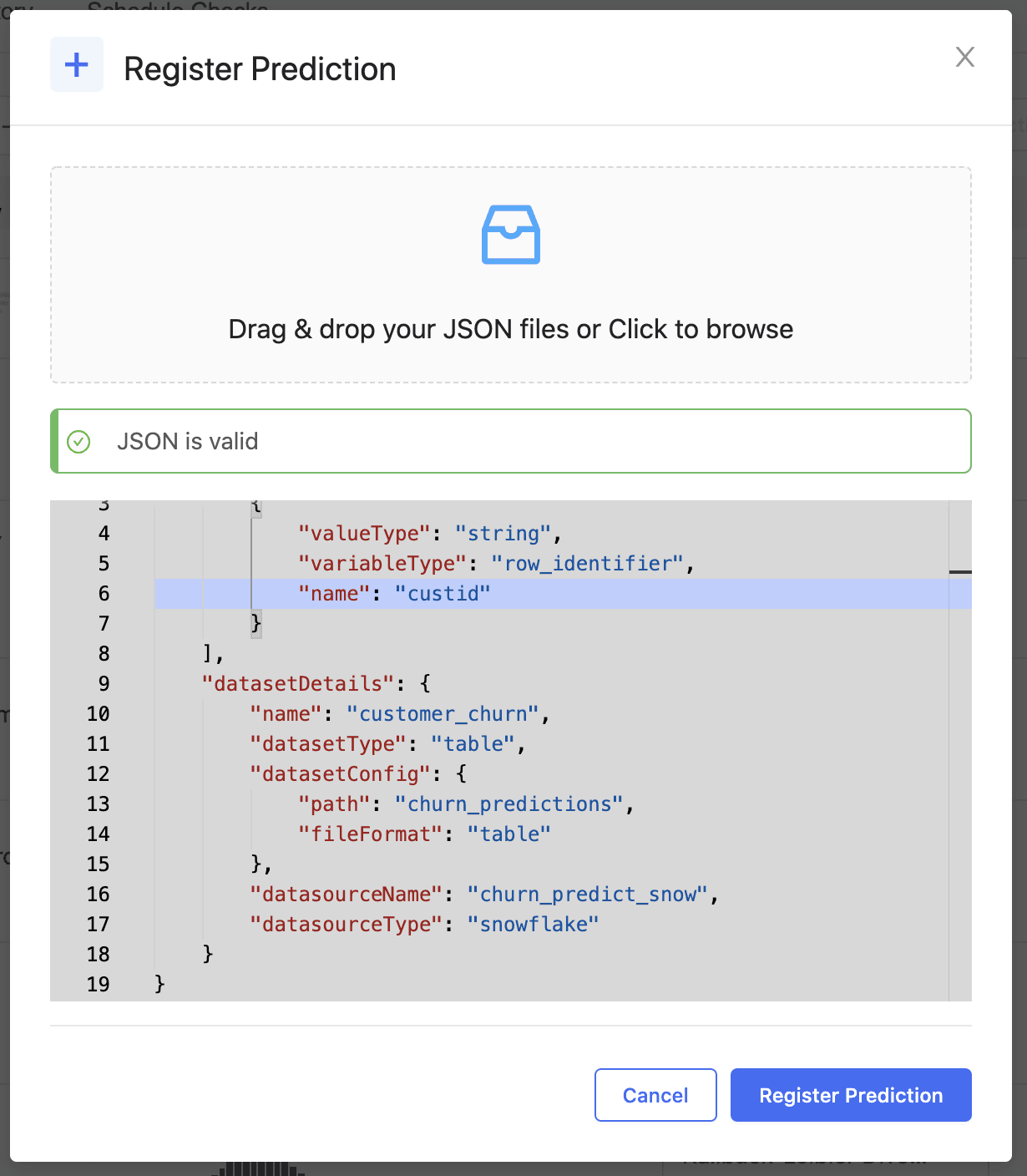
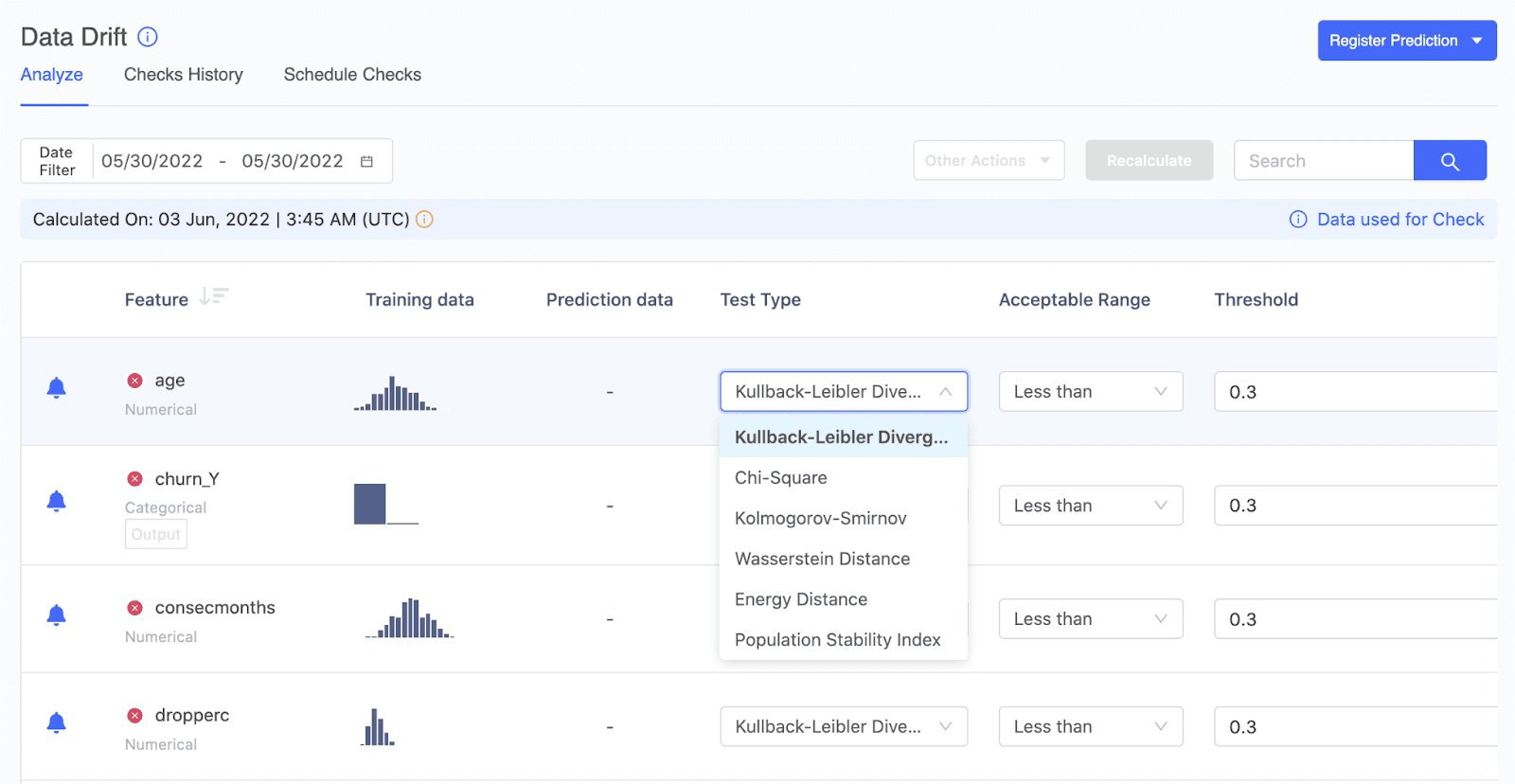
You can also configure drift tests and thresholds on a per-feature basis, and Domino periodically notifies users of any features that have drifted. You can also set up a table to contain ground-truth data and set it up for continuous ingestion the same way. Domino then computes model quality metrics and alerts users anytime thresholds are violated.
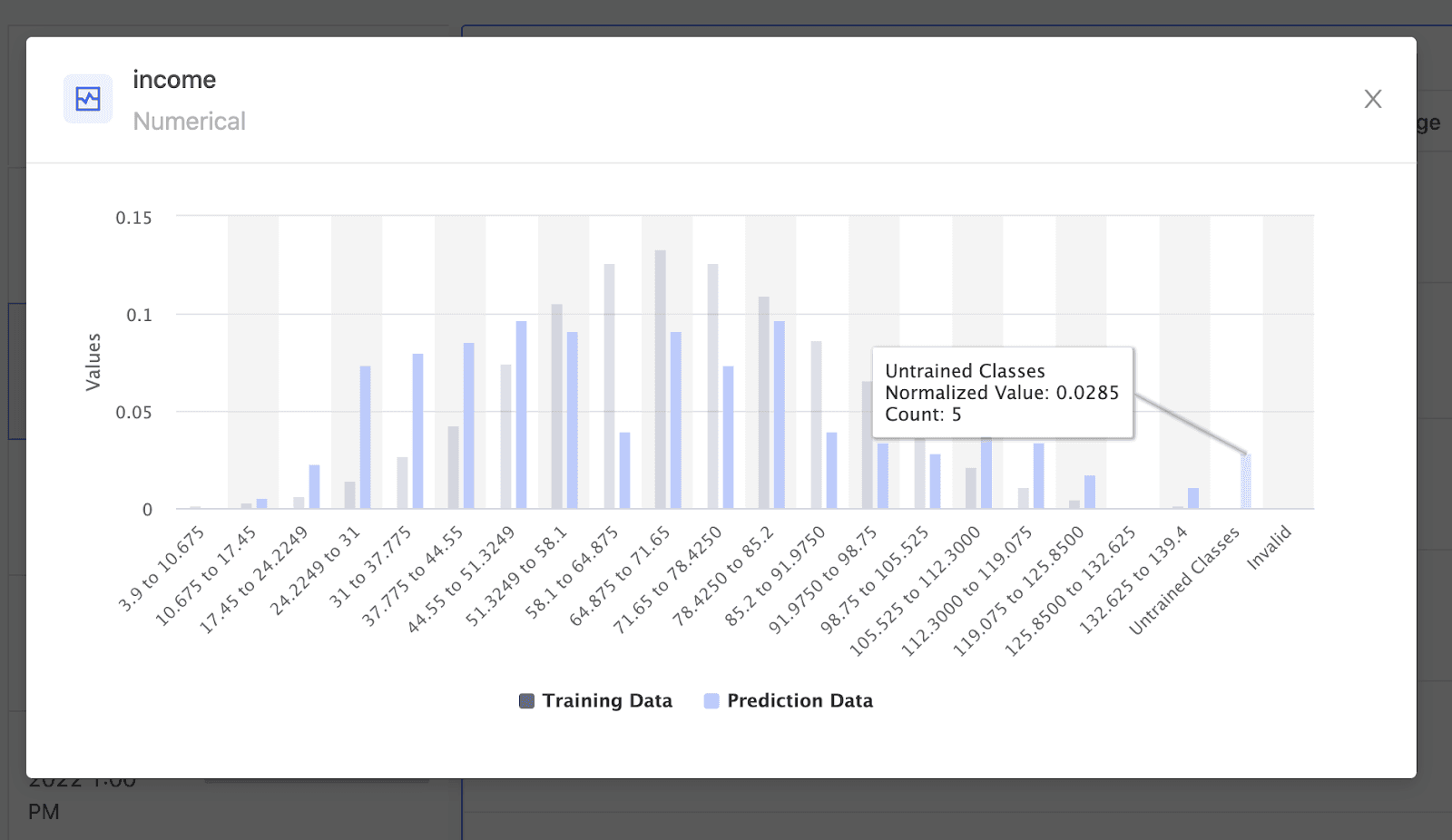
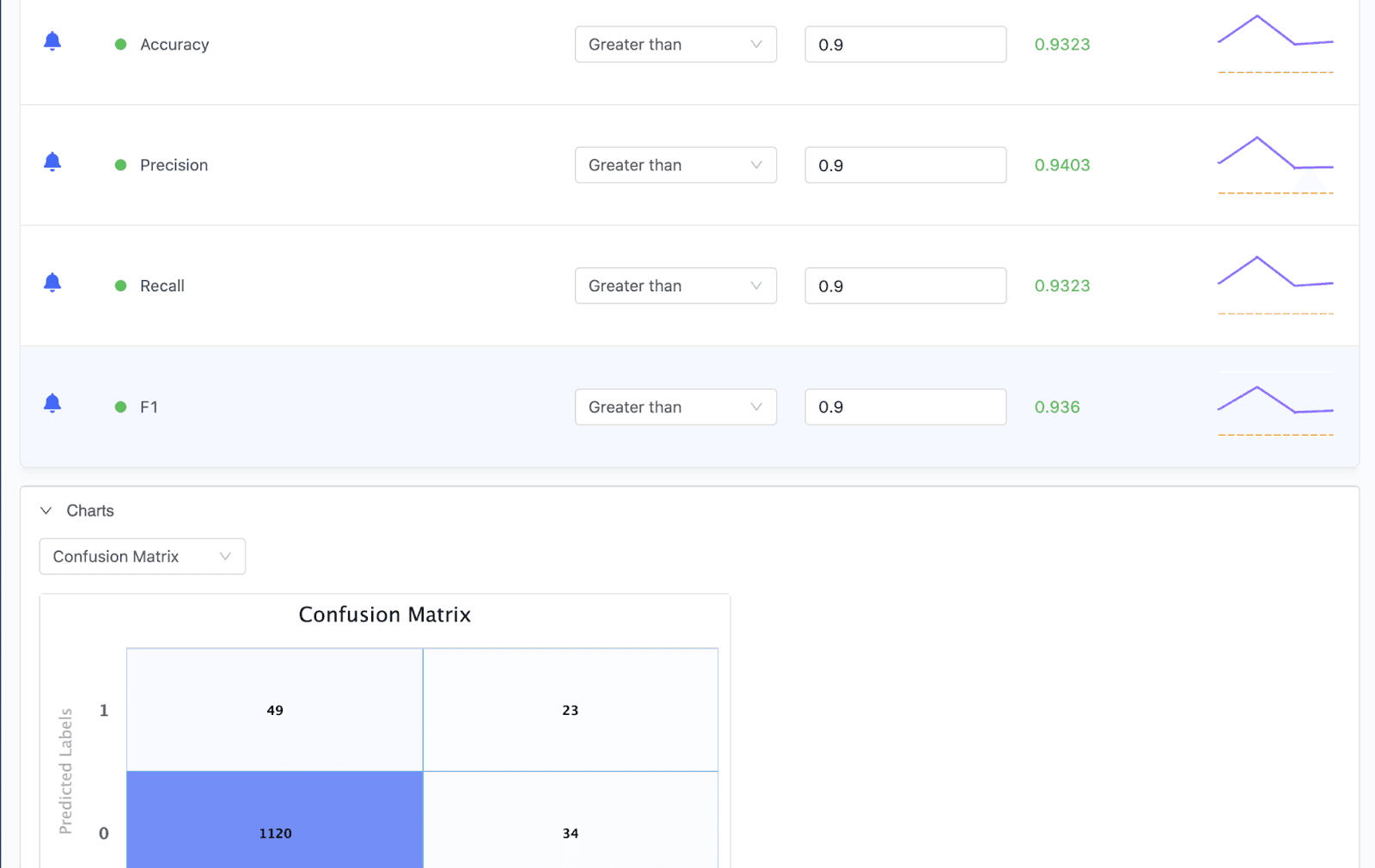
Conclusion
The newest Domino and Snowflake integrations simplify enterprise infrastructure with a common platform across IT and data science teams. Data scientists now have immediate, secure access to the data they need in Snowflake. They have the flexibility of model building in Domino paired with the scalability and power of Snowflake’s platform for in-database computation. Finally, they can automatically set up prediction data capture pipelines for models deployed to Snowflake Data Cloud, ensuring prediction accuracy and maximum business impact.
Learn more about Domino and Snowflake’s partnership at dominodatalab.com/partners/snowflake.
About the Author
Vinay Sridhar is a Senior Product Manager at Domino. He focuses on model productionization and monitoring with an aim to help Domino customers derive business value from their ML research efforts. He has years of experience building products that leverage ML and cloud technologies. |
|---|