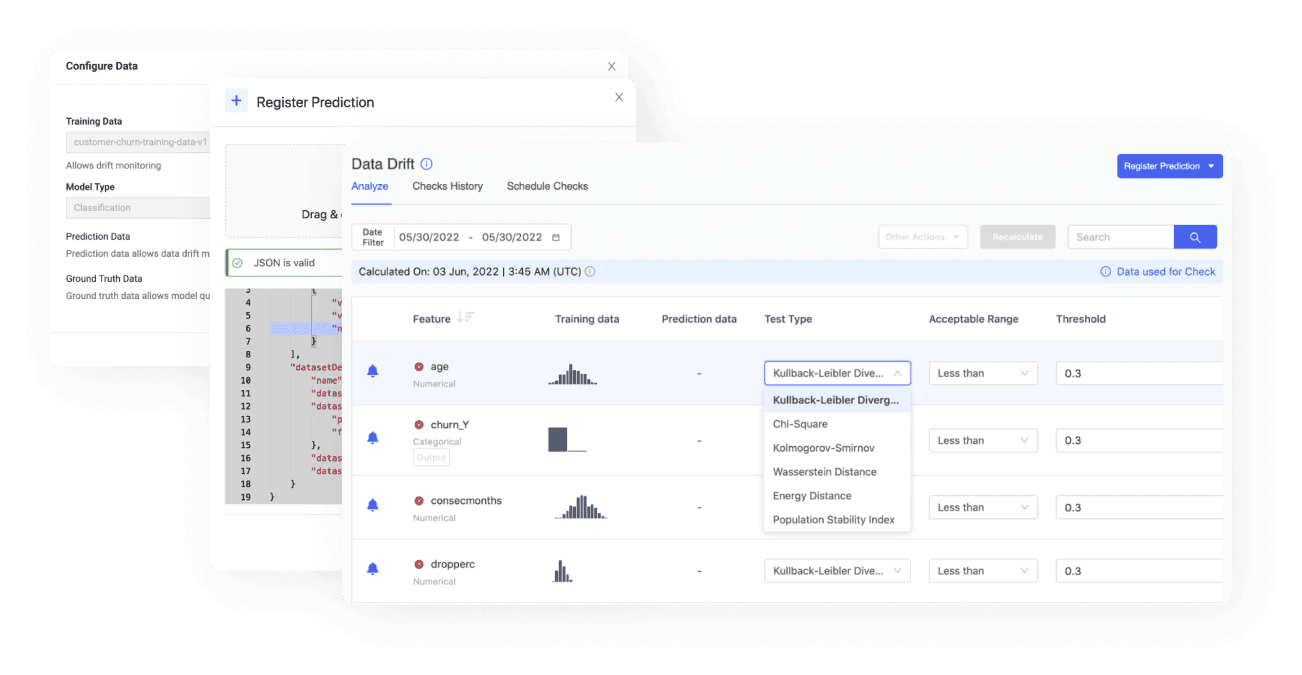
Data & Infrastructure without DevOps
Accelerate Model Development
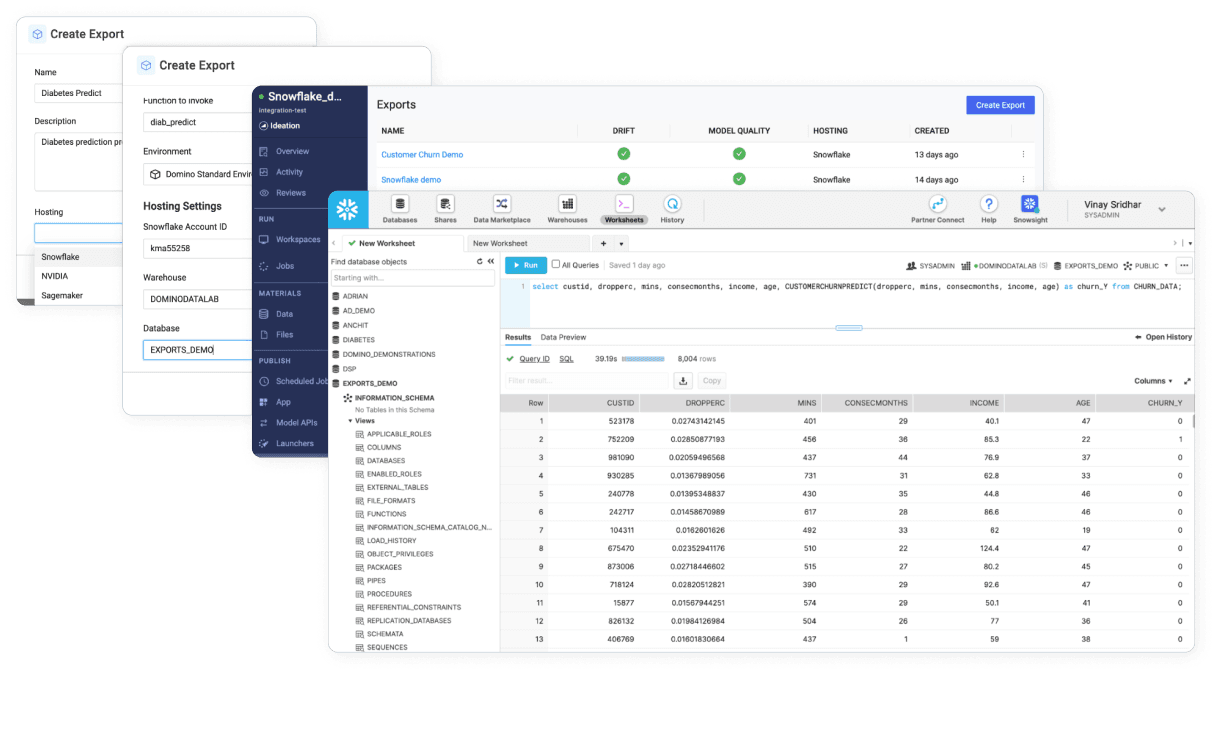
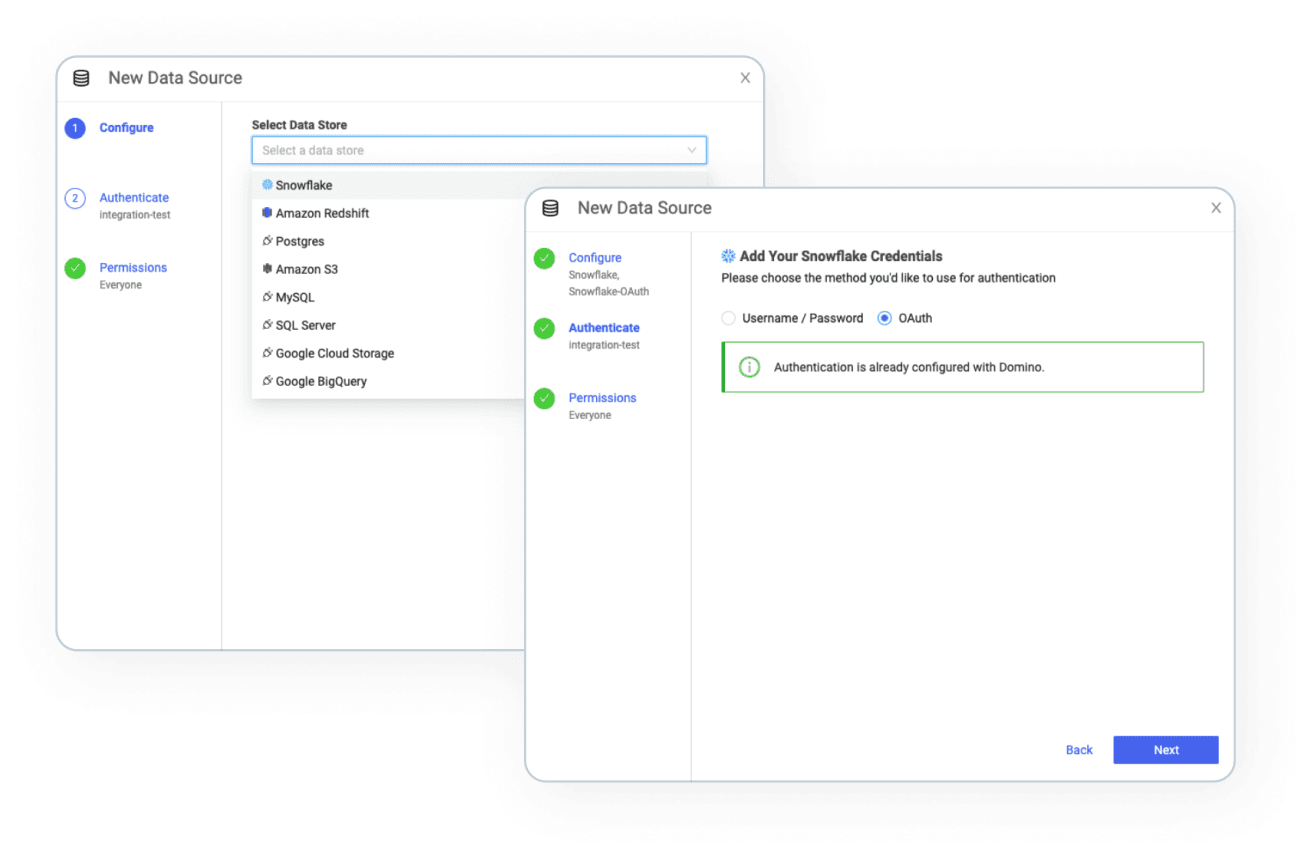
Domino natively integrates with Snowflake - with credentials or OAuth. With just a few clicks, data science teams have immediate access to data residing in Snowflake - without having to orchestrate the movement of data through manual workarounds.
From Domino, Data scientists can build and train models using Snowflake Snowpark, using Python-based libraries in Snowflake’s compute environments where the data resides.