
For companies investing in data science, the stakes have never been so high. According to a recent survey from New Vantage Partners (NVP), 62 percent of firms have invested over $50 million in big data and AI, with 17 percent investing more than $500 million. Expectations are just as high as investment levels, with a survey from Data IQ revealing that a quarter of companies expect data science to increase revenue by 11 percent or more.
While most firms have seen some success with data science, scaling is not coming easily and not for technical reasons. According to NVP’s data, 92 percent of respondents face significant challenges in scaling data science due to corporate culture – specifically with people, processes, organization, and change management related to data science.
This is a major issue given that 75 percent of surveyed executives in a recent survey by Accenture believe that their companies will most likely go out of business if they can’t scale data science successfully within the next five years.
The Challenges of Scaling Data Science
It’s obvious that scaling data science is of paramount importance. If it’s not done successfully, both costs and risk increase. Vital data science and IT resources become trapped doing repetitive manual tasks, timelines elongate and new business opportunities come and go undetected.
As with every emerging business capability in its early years, data science grew organically. While this has led to exciting discoveries and identified unlimited opportunities, it has also created three significant challenges: complex processes to operationalize models, knowledge silos, and a wild west of tools and infrastructure.
Complex Processes
Organic growth in different pockets of data science has created a tangle of complex, inconsistent procedures for moving models from one phase of the data science lifecycle (DSLC) into another. This is particularly evident when it comes to moving tested models from development into deployment. Models essentially sit on the shelf as data scientists work with developers and infrastructure engineers to deploy models on an ad hoc basis, causing significant and costly delays.
This lack of governance and standardization creates technical debt in each project, increases risk, and fails to create a repeatable – and measurable – business model.
Silos of Knowledge
Organic growth also leads to silos. Every team tackles projects and moves on to the next one. The knowledge gained typically doesn’t get retained or shared to benefit the broader organization. In fact, it's often lost if a team member leaves. Collaboration is limited and often teams start from scratch or repeat work previously done simply because they had no way to discover prior outcomes
It also limits the ability for projects to easily flow through the DSLC. Each team member has to be updated on what was done which can be time consuming and limit productivity. If projects sit for any period of time, the knowledge about how they were developed can disappear.
The “Wild West” of Tools and Infrastructure
When data science grows organically it inevitably leads to a chaotic mix of tools being used across bespoke laptops or locally maintained infrastructure. This creates a lot of friction which increases costs and reduces productivity and collaboration. It also creates an assortment of technical issues that increase IT support requirements and opens the door to an assortment of security threats.
The Role of Enterprise MLOps in Scaling Data Science
To properly scale data science, companies need a holistic approach that allows them to develop, deploy, monitor, and manage their models at scale – all supported by a system of record for their data science. We call this approach Enterprise MLOps. It connects the people, processes, and technology across the entire DSLC to accelerate and scale data science within an organization.
MLOps as a practice is not new. But organizations are finding that implementing MLOps at the enterprise level is a much more complex problem than just implementing MLOps for a few models or a single team. Scaling data science and MLOps best practices swiftly, safely, and successfully across an enterprise requires a broad version that encompasses the entire data science lifecycle and meets the requirements of various teams both now and in the future.
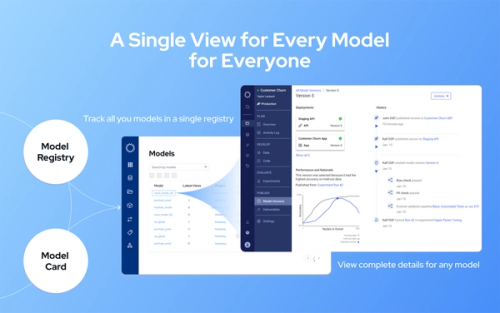
To successfully implement Enterprise MLOps, organizations need enabling technology that delivers a system of record for all data science artifacts, standardizes and automates processes, provides an easy way to collaborate and manage projects, and makes it simple for data scientists to access the tools and compute they need to do their work. That’s what Domino’s Enterprise MLOps platform delivers.
Silos Are Demolished
Breaking down silos is key for scaling data science. That’s why Domino's workbench provides a notebook-based environment where data scientists can collaborate, share knowledge and perform all their model research and development in one place. This means that it doesn’t matter which specific tools one data scientist prefers to use compared to another, they can all seamlessly work together. Knowledge is retained and built upon to drive innovation.
Practices and Patterns are Standardized
When every project leverages the same patterns and practices, regardless of how it was built or where it is going to be deployed it eliminates friction and the support burden from data science.
Domino’s Enterprise MLOps Platform offers easy-to-navigate tools used by each team member throughout the DSLC to build, deploy, monitor, and manage models. Security and administration are centralized, freeing up IT resources. Automation improves productivity and reduces technical debt. Monitoring thresholds, for example, can be established at the outset, so that models are analyzed automatically for performance and data drift.
Tools and Infrastructure Are Centrally Provisioned
Data scientists shouldn’t have to file a ticket with DevOps each time they need a new tool or need to access infrastructure resources like GPUs. Domino gives everyone on the team access to the tools they need and the ability to scale resources on demand. This not only accelerates research, it also drives overall productivity by minimizing burdens on IT support. And, because all available tools are pre-approved for use and governed by IT, this significantly reduces risks and security concerns, without inhibiting innovation.
Domino’s Enterprise Grade Capabilities Are Built to Scale
Just as a thriving company will need to scale its CRM when it increases the size of its sales team and the number of clients it serves, a thriving model driven organization needs the ability to scale its tools and resources as needed. Using Domino the data science team can increase the size and scope of its platform as needed, to accommodate:
- Increasing the size of teams
- Adding multiple teams to the organization
- Changing governance, or industry compliance requirements
- Facilitating audit requirements
- Changing security requirements
- Increasing collaboration with key stakeholders
By orchestrating these types of changes across the entire DSLC, rather than one phase at a time, the need for using a disparate array of tools — or verbally transferring important information from one team to another — are eliminated, along with all the additional inconsistencies and bottlenecks such workarounds always entail.
Adopting an Enterprise MLOps Platform
With millions of dollars at stake and the future of your company on the line, becoming a model-driven organization will be the key to success. Adopting Enterprise MLOps to scale data science sooner rather than later will decrease costs and increase efficiency. It will give you the ability to become more competitive, more innovative and enable you to capitalize on new opportunities as soon as they present themselves, rather than focusing on missed deadlines.

David Weedmark is a published author who has worked as a project manager, software developer, and as a network security consultant.

David Weedmark is a published author who has worked as a project manager, software developer and as a network security consultant.
RELATED TAGS
SHARE
Other posts you might be interested in
Announcement
Check out Domino Data Lab's scores in 2024 Gartner® Critical Capabilities for Data Science and Machine Learning Platforms, Machine Learning Engineering
Read More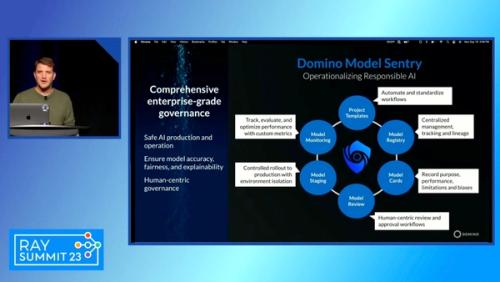
Subscribe to the Domino Newsletter
Receive data science tips and tutorials from leading Data Science leaders, right to your inbox.
By submitting this form you agree to receive communications from Domino related to products and services in accordance with Domino's privacy policy and may opt-out at anytime.