Increasing model velocity for complex models by leveraging hybrid pipelines, parallelization and GPU acceleration




Data science is facing an overwhelming demand for CPU cycles as scientists try to work with datasets that are growing in complexity faster than Moore’s Law can keep up. Considering the need to iterate and retrain quickly, model complexity has been outpacing available compute resources and CPUs for several years, and the problem is growing quickly. The data science industry will need to embrace parallelization and GPU processing to efficiently utilize increasingly complex datasets.
Any business doing machine learning (ML) on large datasets will eventually face this challenge, given the growing intricacies of the newest models. A model like AlexNet has 61M parameters and over 600M connections. Try to fit this against the 1.2M images in ImageNet and you have a substantial computational challenge. And AlexNet is one of the simplest models in the plot below — just think of what SOTA models require today.
The problem is compute demand — this is what slows down model training. Computational demand is a function based on model complexity and the size of the dataset, and the CPU demand for training complex models has been increasing faster than Moore’s Law. If we look at the compute demand from AlexNet to AlphaGo Zero we will see an exponential increase with a three to four-month doubling time. By comparison, Moore’s Law has a two-year doubling period. Since 2012, computational demand by the latest models has grown more than 300,000x — Moore’s Law would only yield a 7x increase.
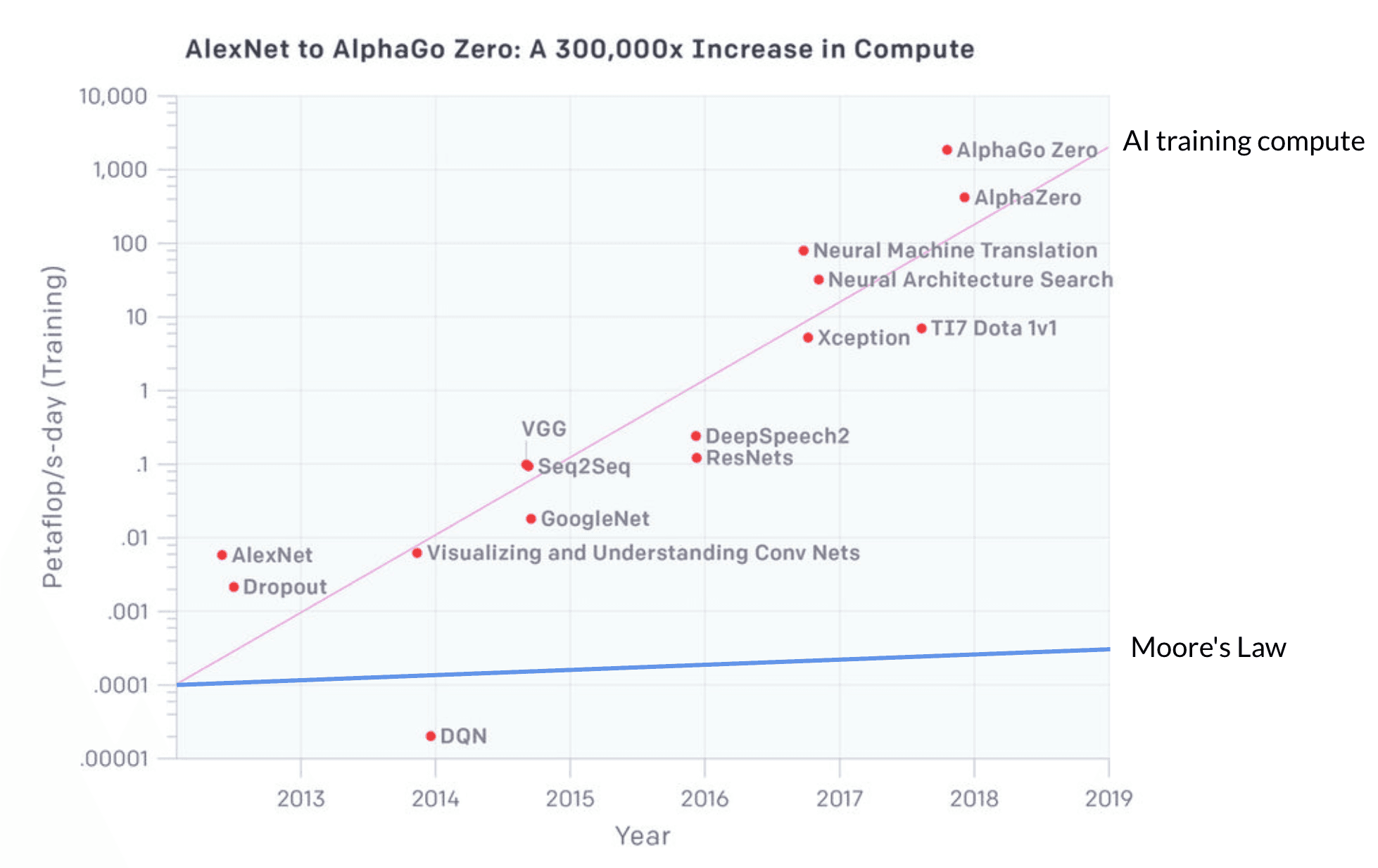
Illustration of the increasing compute demand from AlexNet in 2013 to AlphaGo Zero today; the exponential fit of the data points gave a doubling time 3.43 months, as given in Kozma, Robert & Noack, Raymond & Siegelmann, Hava. (2019). Models of Situated Intelligence Inspired by the Energy Management of Brains. 567–572. 10.1109/SMC.2019.8914064
Find the right framework for the task
When you’re training a predictive model, you go through stages from pre-processing to model training, model validation, and operationalization. A traditional approach would be to use Spark end to end, throw more compute resources at the problem, and wait for the results. But if you use different frameworks for different parts of the pipeline, you can divide up the work and process each stage using the best tool for each job.
Hybrid pipelines address modern challenges
If you try to orchestrate your entire model lifecycle around a single tool, you’ll be substantially constrained by the “What can this tool do?” mentality. Switching to a hybrid pipeline grants you the freedom to choose the best and most efficient tool for each individual stage. Maintaining clusters can also be quite expensive. If you have an on-prem Spark cluster with 50 worker nodes, your administrators will want to put as much workload as possible on that cluster, because the business pays for its compute and maintenance. This in turn means that the cluster may be heavily utilized and resource-bound.
On the other hand, if you’re retraining your model every week or month, instead of maintaining assets that will sit there draining money until you need them, you can look for ways to spin up and then de-provision clusters as needed. For example, if you are collecting data daily and retraining models on a weekly basis, you could set up a GPU-accelerated Spark cluster that is auto-provisioned on Sunday, executes the pipeline, and gets de-provisioned after its completion. This saves money not only because you pay for the cluster only when you need it, but more crucially — using GPU acceleration guarantees that the cluster will complete the pipeline in a shorter period of time, yielding additional savings.
Spark was created at UC Berkeley as a general-purpose computation engine, and is the established leader when it comes to parallel big data processing. The SparkSQL engine is unmatched by anything else. But Spark’s ML library is not as advanced as other frameworks and there is a somewhat steep learning curve to Spark because of its specific data processing paradigms and APIs. In that sense, Spark lives in its own universe, while challengers like Dask and Ray have been steadily gaining traction.
In contrast to Spark, the initial design principle of Dask was “invent nothing.” The idea behind this decision is that working with Dask should feel familiar to developers who have been using Python for data analysis, and the ramp-up time should be minimal. Ray, another project from UC Berkeley, consists of two major components — Ray Core, which is a distributed computing framework, and Ray Ecosystem, which broadly speaking is a number of task-specific libraries that come packaged with Ray (e.g. Ray Tune — a hyperparameter optimization framework, RaySGD for distributed deep learning, RayRLib for reinforcement learning, etc.)
Spark is still great for ETL workloads, but Ray is better for specific tasks like reinforcement learning, and Dask gets the lead on out-of-the-box support for Pandas DataFrames and NumPy arrays. You need to be able to pick the best of breed.
For more on the differences between frameworks, see: Spark, Dask, and Ray: Choosing the Right Framework
Accelerating velocity
Using multiple tools and frameworks has not been a common practice due to the legacy infrastructure most companies are working with. If you have a Spark cluster that IT is looking after, you likely have to use Spark — getting anything else provisioned is an IT hassle. But in data science, you need to be agile and, if push comes to shove, have the freedom to fail fast.
Data science is a very dynamic field. If you want to try a new parallel processing framework you don’t want to wait 6–7 weeks for IT to provision and configure a cluster. Worst case scenario, if your idea doesn’t pan out after engaging IT resources and waiting for weeks, you lose all that time, and your credibility in the company could be impacted. You want to make it easy to try new approaches.
In addition, to solve a computationally-heavy problem, you can’t rely on fast CPUs and hybrid pipelines alone. For a task like grid search and hyperparameter tuning in general, you need to retrain your model hundreds to thousands of times. You can either do your computations in parallel, or use GPU acceleration, or do both. If you don’t use parallelism, you’ll need a larger and larger compute instance. Instead of retraining your model in a day, it takes a month. That’s not good for model velocity.
Shifting to parallelism and GPU processing
For ML projects, many of the problems are matrix-based algebra computations, with a large number of simple math calculations. One advantage of GPUs is that instead of having a dozen or two dozen cores to calculate values, GPUs have hundreds of cores which can do very basic computations very quickly. This is a good fitting solution for ML workloads — you can offload matrix math to the GPU while using CPUs for more sequential calculations. MIT’s Neil C. Thompson and Kristjan Greenewald wrote about the challenges of CPUs and benefits of GPUs in The Computational Limits of Deep Learning.
People have been using GPUs for model training for a while. But trying to set up an infrastructure that can coordinate multiple machines with GPU acceleration is quite complex — writing the code to distribute and manage GPU execution over multiple machines is really hard. The innovation here is that we’re getting specific accelerators created to manage distributed parallelization frameworks. NVIDIA introduced the RAPIDS Accelerator for Apache Spark, which adds GPU acceleration to Spark. Frameworks like Dask and Ray can now handle the parallelization and integrate with GPU frameworks like Tensorflow and PyTorch to provide parallelized GPU execution. We have the capability to combine parallelization and GPU acceleration in ways that were not possible before. The capability to harness GPU-accelerated distributed processing is becoming crucial in breaking the limits of training complex models in a reasonable amount of time.
Conclusion
Looking to the future, model size and complexity are only expected to grow. Companies across the landscape are not trying to get model-driven because it’s new and fancy, they do it because competitive pressure leaves them no choice.
If you want to be a leading-edge company that stays in the lead, you should take an approach that makes the best of current and emerging tools by partitioning your data, setting up multiple machines using GPUs to process the algebra at lightning speed, and deploying an infrastructure that will support your ability to provision and manage different frameworks and tools easily.
When you’re ready to take the next step in accelerating your data science program, think about how you would implement a hybrid pipeline with distributed processing supported by GPU acceleration. As you approach your next project, you can think about the different capabilities of each approach, and think about ways to incorporate multiple frameworks without too many management or IT headaches. By considering the points I’ve discussed above, you will be able to deliver timely results using increasingly complex models.