









Enable self-service data science
Self-service access to tools, data, and compute
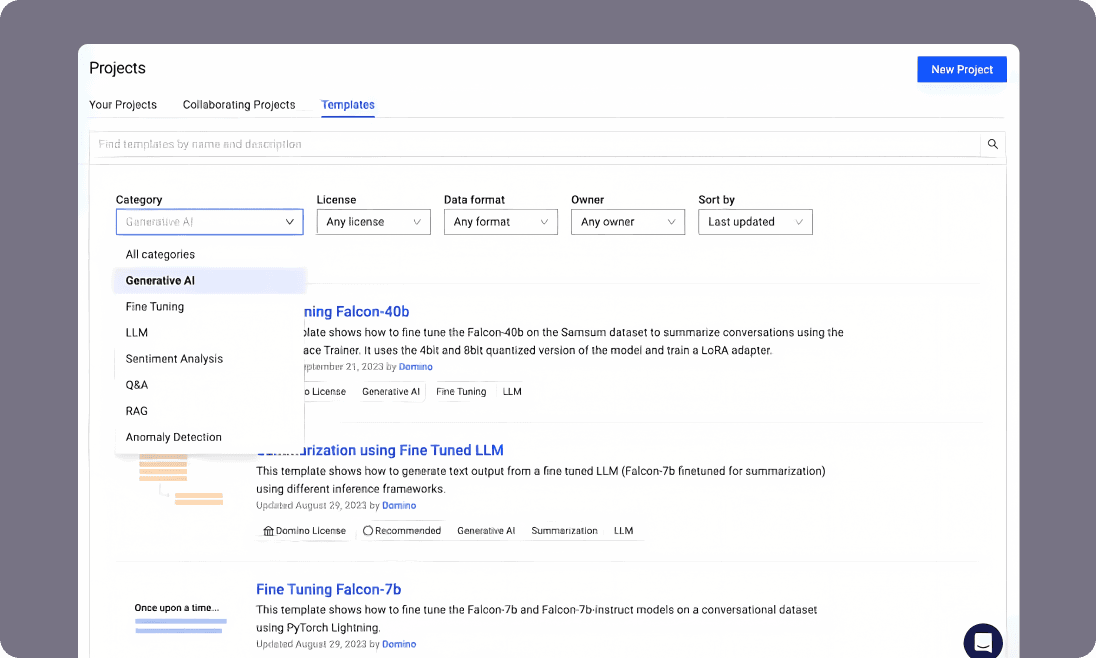
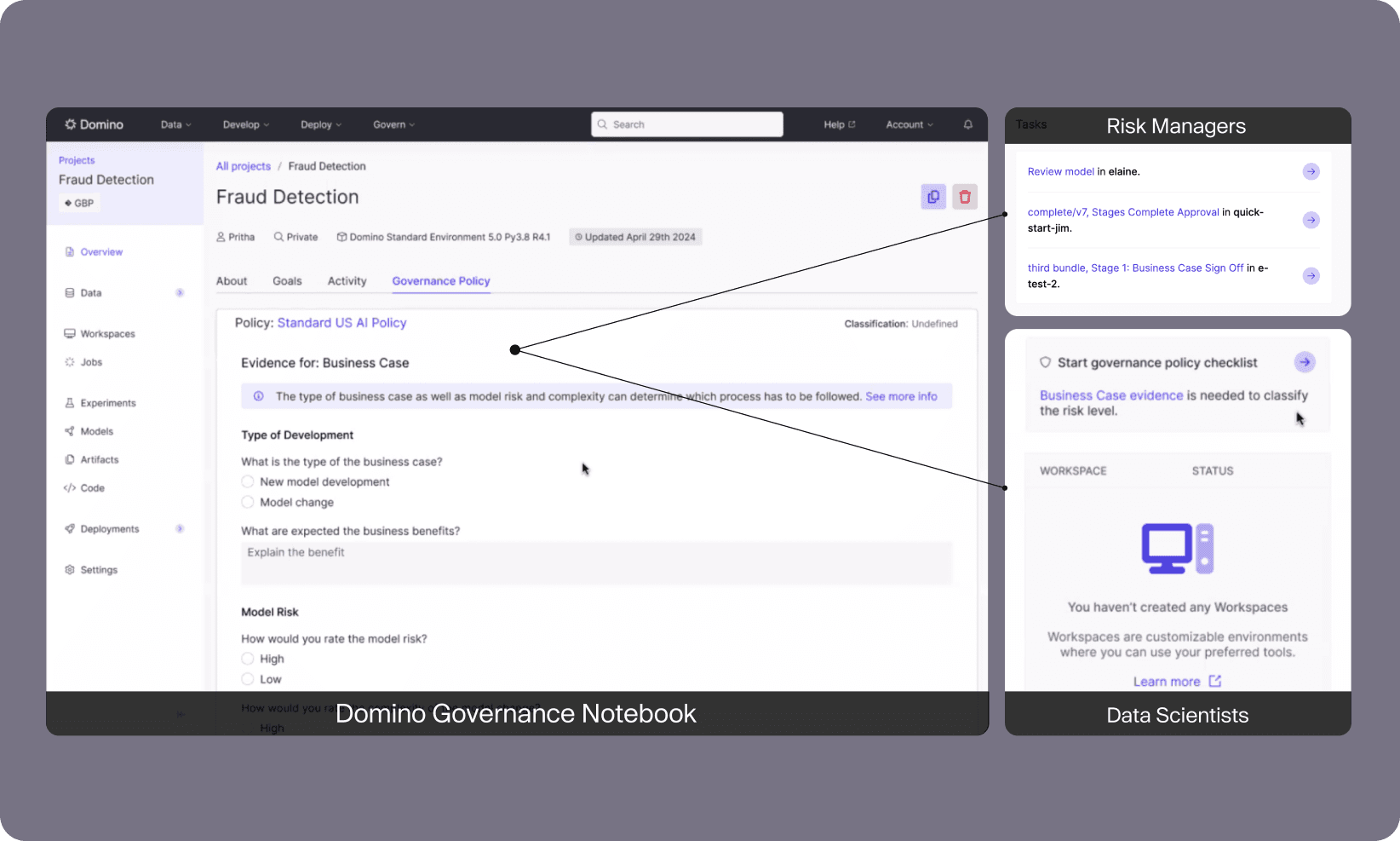
Domino gives data scientists instant, governed access to everything they need: one-click access to IDEs like Cursor, Jupyter, RStudio, and VS Code, secure self-service connections to enterprise datasets, and elastic compute from CPUs to powerful GPU clusters — all with IT guardrails.
Explore on-demand infrastructure
Securely access, explore, and transform your data anywhere
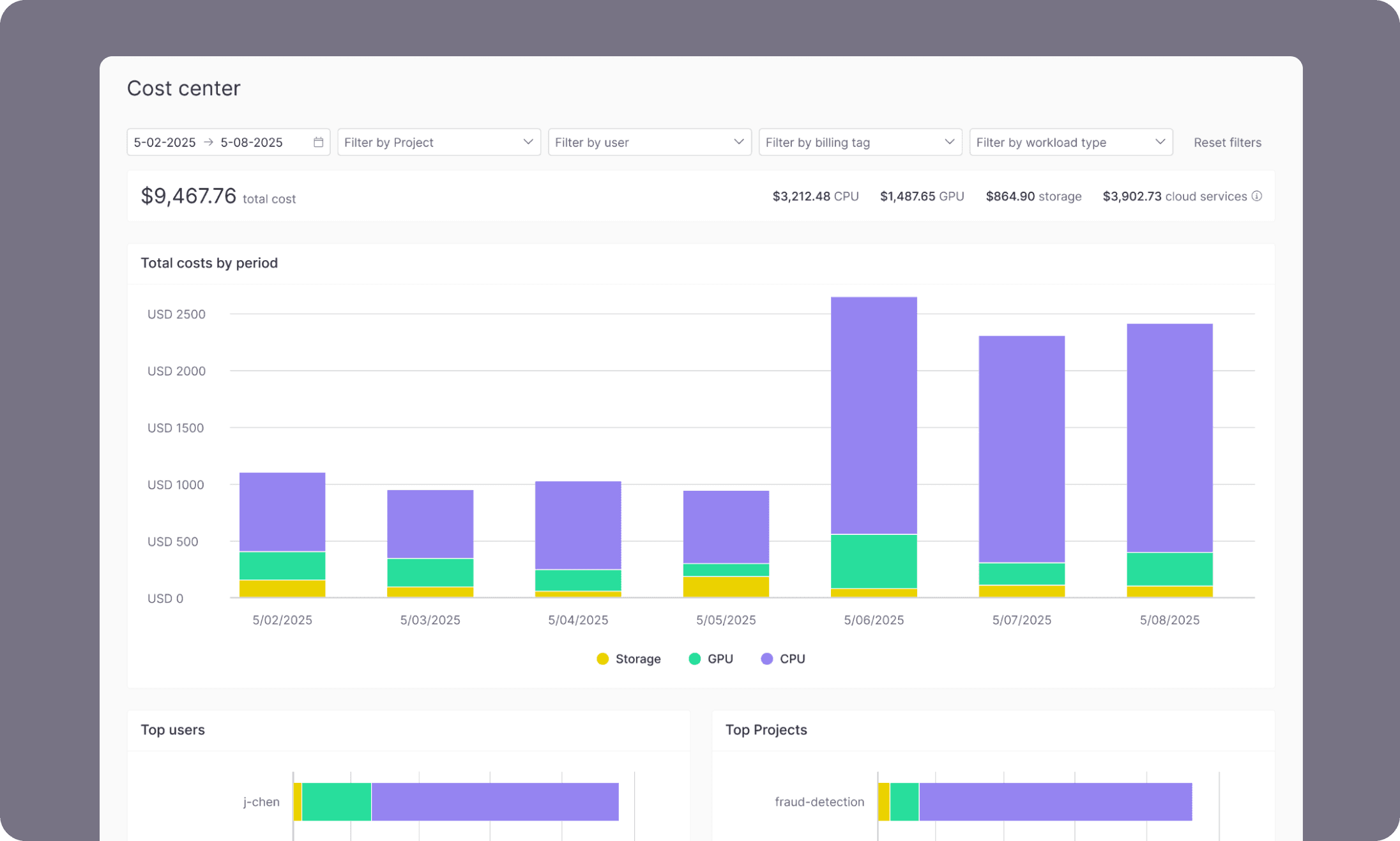
Data scientists and engineers can instantly work with structured or unstructured data — without copying it. Build features, embeddings, and AI-ready datasets with governance and speed.