Crowdsourced language understanding at Voicebox




We recently caught up with Dr. Daniela Braga, Director of Data Science and Crowdsourcing at Voicebox.
Thank you for the interview, Daniela. Let’s start our time together by talking about your background.
My background is in speech science. I’ve worked in this area for fifteen years. I spent six years in academia in Portugal and Spain. In the last nine years, I’ve worked in the industry, including seven years at the Microsoft Speech Group, in Portugal, Beijing and Redmond, Washington. More recently, I’ve been focused on data science, having introduced crowdsourcing into speech at the Microsoft group and more recently in Voicebox Technologies. These efforts saved both organizations nearly 50%-80% in costs. I’ve worked on building high quality control workflows and scalable throughputs in a world of data-driven technologies, which need an endless data supply.

How did you get interested in speech recognition and, more specifically, natural language understanding?
It’s a funny story because it happened on accident. When I finished my BA in linguistics, I came across a job posting on the job wall at my university in Portugal. The Faculty of Engineering of Porto was looking for a linguist to help them develop the first Text-to-Speech and Automatic Speech Recognition systems in European Portuguese. This took place in the middle of July in 2000. The job application deadline had passed and the university was completely empty. A friend of mine encouraged me to call the number anyway, right on the spot. I thought it would be pointless, but I did it. A deep male voice picked up the phone, and it turned out that nobody had applied yet. So I got the job. My interview was with the head of the Speech Lab at the University of Porto and he told me, “It’s become a new trend to hire Linguists to work with Engineers in this new field (Speech Technology). It’s happening all over Europe. We don’t yet know how and why linguists can be useful, but if you can help us figure it out, you have the job.” Here I am, still working in the field of Speech Technology. I guess I found the answer.
You have a very rich academic and professional background, can you share some career highlights?
Let me see. I believe that the first one was the topic of my PhD. This was before data-driven techniques were fully mainstream in Speech Science. Even today Text-to-Speech (TTS) technology has a lot of rule-based techniques. I was the first to develop an fully rule-based front-end for a Text-to-Speech and apply it successfully to European Portuguese, Brazilian Portuguese and Galician, a language spoken in Spain, which shares a common past with Portuguese. This was quite unique considering that until that moment, several attempts had been made with data driven technologies, none of them achieving the same results.
The second one was being able to convince the Speech Group at Microsoft to handle the development of TTS systems and significant language components for most of the European languages in Portugal. Within two years, my team was able to ship them Project Exchange 14 (encompassing 26 languages).
The latest highlight was being able to convince Voicebox Technologies that crowdsourcing allied to Machine Learning is the best way scale Speech Technology products and have global reach faster, cost effectively while keeping quality up.
What kind of work are you doing at Voicebox?
I’ve re-structured the Data team at Voicebox. When I came in, the company used to depend on customers to supply the data. I changed the company’s capability on data, enabling us to have Data Services that will be exposed to customers via web-services and APIs, along with our conversational understanding products. In the last two years, I’ve been growing a team of 15 people that serve the company’s demand for multilingual data collection, data cleanup/processing/tagging, machine learning, data evaluation, ingestion, storage, databases, security, reporting and analytics.
What has been the most surprising insight or development you’ve found?
Coming from a rule-based mindset (because of my background in Linguistics), the most surprising development I’ve witnessed is the switch of Speech Technology’s scientific paradigm from rule-based to data-driven techniques. Now it makes sense, but it wasn’t always obvious. I quickly adapted from rule-based to crowdsourcing, which is all about serving the growing needs of data-driven technologies.
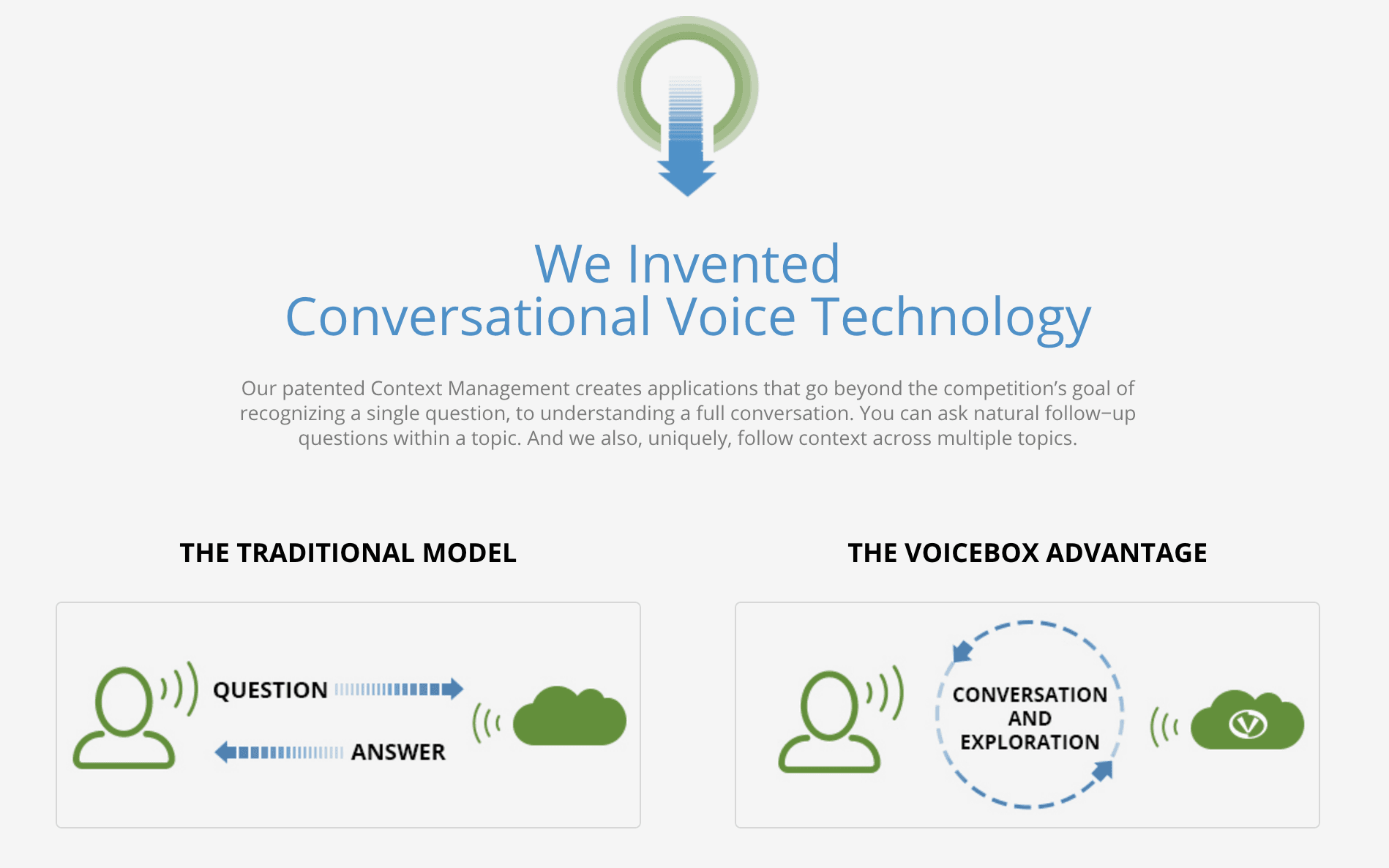
What does the future of Data Science and speech recognition look like? How does crowdsourcing fit into all of this?
It’s no longer only speech recognition; it’s language understanding. Speech recognition handles command and control at the phonetic level, whereas language understanding interprets the intent of the user and responds with a meaningful result. Speech technology requires large amounts of data. Although we can say that natural language understanding is relatively mature in American English, the same isn’t true for the remaining 7000 spoken languages of the world.
Crowdsourcing brings the necessary human judgment piece to the machine learning techniques used by speech technology
The market demands on voice enabled technologies are growing internationally. Current data-driven technologies require huge amounts of data to train and test speech recognition and natural language understanding modules. The data is never complete, since it requires consistently up-to-date lists of businesses, points of interest, celebrities, book and music releases, etc. Crowdsourcing brings the necessary human judgment piece to the machine learning techniques used by speech technology. For example, in order to train an acoustic model (which is a speech recognition component), you need at least 1000 speakers speaking for one hour each. Those speakers need to be balanced in gender, age and region. You can train a system to recognize different dialects and sociolects. That’s where crowdsourcing comes in, and there is still no way to replace humans in this type of variation.
What personal/professional projects have you been working on this year, and why/how are they interesting to you?
Automating our crowdsourcing workflows, creating data visualization via reporting and analytics capabilities and data discoverability. This is a new service that allows internal and external customers to browse and query all of our different databases and types of data, from acoustic to text data.
What publications, websites, blogs, conferences and/or books are helpful to your work?
I follow and attend the traditional speech technology events where you can see the latest and greatest developments in the field (in conferences like Interspeech, ICASSP, ACL, LREC). I read the Google Research blog and the [Microsoft Research blog], the news on [Crowdsourcing.org] and publications like Entrepreneur, Business Insider and TechCrunch. I’ve also been paying attention to what is happening in the Data Science field, but my attention is still very scattered.
What machine learning methods have you found to be most helpful? Do you envision being most helpful? What are your favorite tools/applications to work with?
Currently, Deep Neural Networks are the holy grail of ML techniques for Speech Technology. You can get a paper accepted anywhere if you use DNNs applied to your subject. Word2vec and other techniques have also shown to be very interesting in our field.
Any words of wisdom for data science/machine learning students or practitioners who are starting out?
In the world of big data, where open source data is becoming fashionable, building machine learning packages and making them available as services looks to be one of the best ways to monetize your skill sets.
Daniela, thank you so much for your time! We enjoyed learning about you and the revolutionary work you’re doing at Voicebox.
Follow Daniela on Linkedin.