A quick benchmark of hashtable implementations in R




UPDATE: I am humbled and thankful to have had so much feedback on this post! It started out as a quick and dirty benchmark but I had some great feedback from Reddit, comments on this post, and even from Hadley himself! This post now has some updates. The major update is that R's new.env(hash=TRUE) actually provides the fastest hash table if your keys are always going to be valid R symbols! This is one of the things I really love about the data science community and the data science process. Iteration and peer review is key to great results!
When one thinks about critical components of a data science pipeline, you are likely to consider modeling APIs or visualization libraries, but it's unlikely that the lowly hashtable would be foremost on your mind. A painful fact of data science is that the majority of effort put into a typical project (reportedly, 80%) is spent sourcing, cleaning, and preparing the data. The remaining "20%" is actual data analysis. One of the most useful data structures available to data scientists is the hash table (also known as an associative array).
The hash table is a veritable Swiss Army Chainsaw. These data structures allow the user to take an arbitrary value, such as a string, a complex object or a data frame, and use it as a lookup to find another value. Common uses for hashtable data structures in the cleaning and preparing data phase of a data science project are feature engineering (for example, keeping a count of how many times you've seen an individual value in a stream), normalization, or even creating simple histograms.
R’s lack of a native (and performant) hashtable
To the surprise of many who come to the R programming language from other backgrounds, R's support for hash tables has been historically lacking. UPDATE: It turns out, R has a perfectly performant hash table implementation, it's just not intuitively named or easy to find. If you create a new environment using new.env(hash=TRUE), R provides you an environment that performs admirably. This makes sense as it's a thin wrapper over a hash table implemented in C, and the performance shows. The list() data structure that R provides does allow for this associative mapping. There are, however, numerous warnings about potential performance implications of using and growing lists on Stack Overflow and similar forums. In this short blog post, we provide a simple benchmark of 4 approaches to managing an associative hashtable in R. We look at the native list(), Michael Kuhn's dict package, Christopher Brown's hash package, Neal Futz's ht package and the default new.env(hash=TRUE).
One of the first differences between the packages is the ability to store complex keys. For example, you may want to map a data.frame to a particular value. The following code demonstrates a simple example:
mydict <- dict()
mylist <- list()
myht <- ht()
myhash <- hash()
myenv <- new.env(hash=TRUE)
mykey <- data.frame(product="domino", value="awesome")
mydict[[mykey]] <- "something" #will fail
mylist[[mykey]] <- "something" #will fail
myhash[[mykey]] <- "something" #will fail
myenv[[mykey] <- "something" # will fail
myht[[mykey]] <- "something" #will succeed
The native R list and the dict package will not allow you to store an entry in the hashtable with a complex key such as a data.frame. They will return the following error:
mykey <- data.frame(product="domino", value="awesome")
mydict[mykey] <- "something" #will fail
Error in mydict[mykey] <- "something" : invalid subscript type 'list'
mylist <- list()
mylist[mykey] <- "something" #will fail
Error in mylist[mykey] <- "something" : invalid subscript type 'list'
The hash package does not provide the same error, however when one looks underneath the surface, the package instead stores the key seemingly incorrectly, and would not actually allow you to look it up given the original values: (UPDATE: This was an error in how I was assigning values. As Hadley pointed out to me in a tweet, [[ is for single values, [ is for multiple values. So this error was completely spurious, and hid the real fact that hashes don't store complex keys.)
# UPDATE - Ignore this code block, read update above!
myhash[mykey] <- "something" #will succeed
myhash[mykey]
Error in get(k, x) : invalid first argument
myhash[data.frame(product="domino", value="awesome")]
Error in get(k, x) : invalid first argument
as.list(myhash)
$`1`
[1] "something"
For some reason, the data.frame which was the key was silently stored as the number 1. This could create some difficult to track bugs if the user was caught unaware.
The ht package uses a digest under the hood, and allows you to look up the value both with the original key, or with an object that generates the same digest value:
] myht[mykey] <- "something" #will succeed
] myht[mykey]
[1] "something"
] myht[data.frame(product="domino", value="awesome")]
[1] "something"
If you need to store arbitrarily complex objects as keys in a hash, the ht package provides the greatest functionality.
Performance of hashtable packages
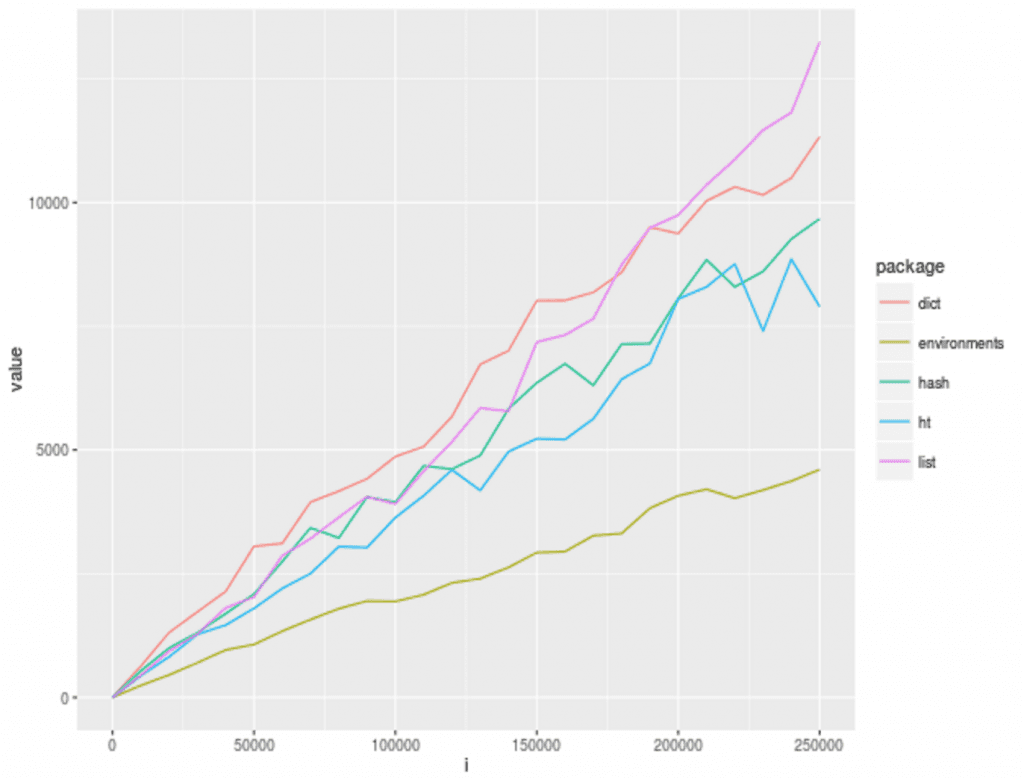
We profiled the runtime performance of these different hashtable implementations. We used the excellent microbenchmark package to perform ten runs of each experiment. In the experiments, we are inserting from 10,000 to ~250,000 unique keys in each hash, in increments of 10k.
microbenchmark provides us with a data structure containing minimum, maximum, mean, and median values for each of the operations, after first warming up the system by running the benchmarked code twice (to get around cold cache issues, for example.) When we look at mean values, the results are clear:
As the number of keys exceeds 100k, the runtimes begin to diverge. The ht and hash packages retain far lower runtimes than the other hash tables. However, the built-in environment performs considerably better than all other implementations. This makes sense considering that ht and hash use environments, but are probably paying some performance penalty on top of the raw implementation for convenience. The performance curves of dict and the list() implementations are quite similar, implying they may work similarly under the hood. Regardless, the curve of their performance curve shows that as that number grows performance is going to suffer considerably.
When we plot the minimum, median, and maximum values, there are no surprises. The pattern we see above is repeated across all of the packages:
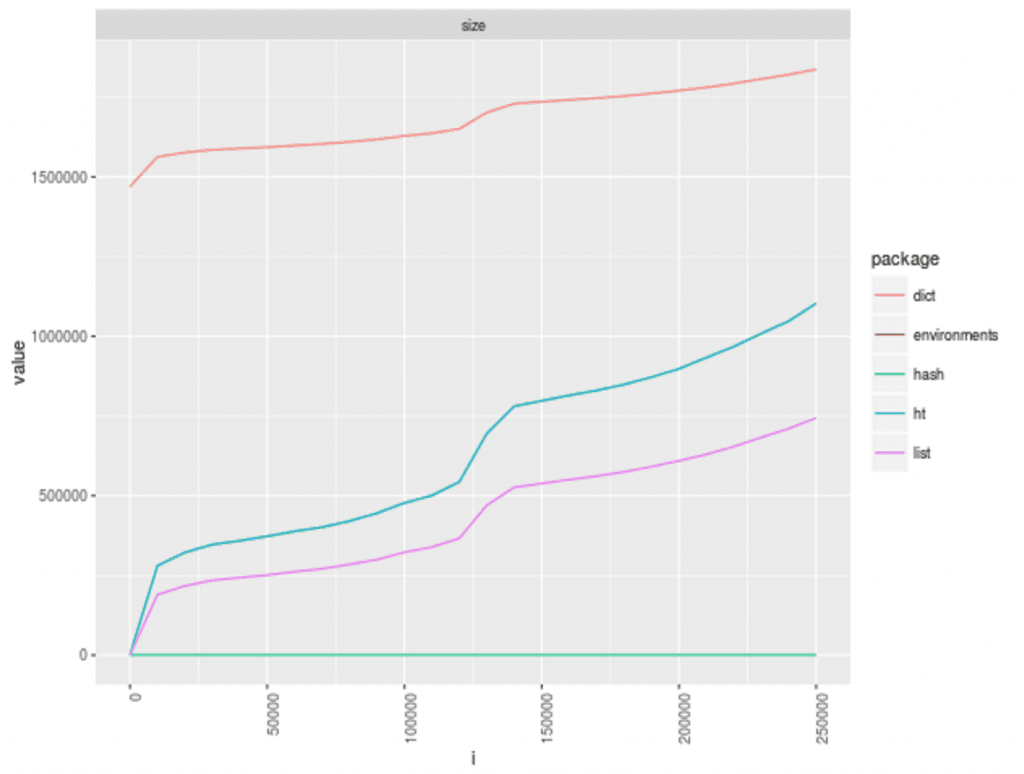
Another aspect of performance is the amount of memory that the data structure uses when storing data. We used R's UPDATE: We replaced R's object.size() function to determine memory utilization.object.size() for the object_size function from Hadley's pry package. For reasons unknown to the author, the ht and hash packages returned a constant size, as illustrated by the two lines at the bottom of the chart. There was also an issue with object_size returning an error for hash objects, and an issue has filed in the appropriate github.
Looking at the chart, you'll note that dict and list() both see significant increases in memory usage at two points in the experiment. The similarity of their respective memory consumption and performance curves is a pretty strong hint that the dict package is implemented as a list()! However, you will note that now using pryr's object_size we see that dict objects take up a significantly higher amount of RAM. I will be looking into this, because this doesn't seem like a correct behavior.
The experimental data was pulled from Hadley Wickham's [baby names dataset on github].
Since object.size() appeared not to work with the ht and hash packages, we used reproducibility engine in Domino to capture the runtime statistics of the experiments. This provided us with a rough idea of the amount of memory used.
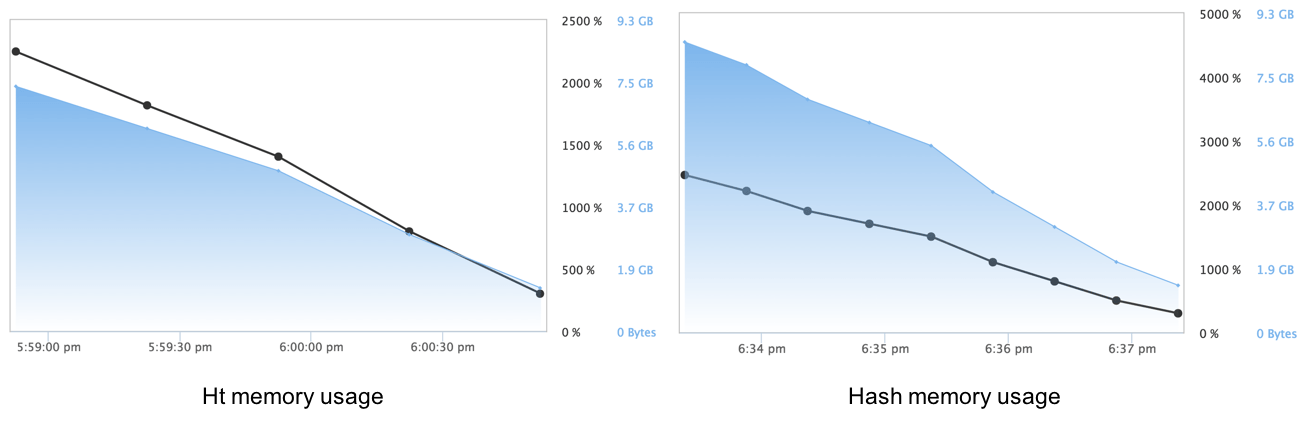
The memory utilization profile of the packages is nearly identical, implying that they too may use the same underlying infrastructure of the R Base Package.
Summary
Hashtables are an incredibly useful data structure. In R, if you need to store key-value pairs, and your keys are never going to be a complex data structure, the hash package is the clear winner. (UPDATE: In R, if you need to store key value pairs, and your keys are always going to be valid R symbols, the built-in new.env(hash=TRUE) is the clear winner!) If you are going to need complex keys, the ht package provides somewhat similar performance to hash, with the added ability to use complex keys.
Banner image titled “dictionary” by Yamanaka Tamaki. Licensed under CC BY 2.0.