Life Sciences Why disconnected RWE platforms are costing you time, money, and credibilityBy Christopher McSpiritt6 min read
Life Sciences Modernizing science with SSH: Local tools, global compute, reproducible resultsBy Matt Tendler5 min read
Life Sciences Building trust in AI for drug development: A roadmap for FDA-ready innovationBy Christopher McSpiritt12 min read
PerspectiveDomino operationalizes the NVIDIA Enterprise AI Factory Validated DesignBy Domino5 min read
Perspective21 CFR Part 11: Meeting FDA compliance requirements without sacrificing speedBy Domino13 min read
Product UpdatesNew! Domino Nexus now supports versioned file storage with Domino DatasetsBy Leila Nouri5 min read
Responsible AINavigating the EU AI Act: Strategies for compliance and business growthBy Leila Nouri5 min read
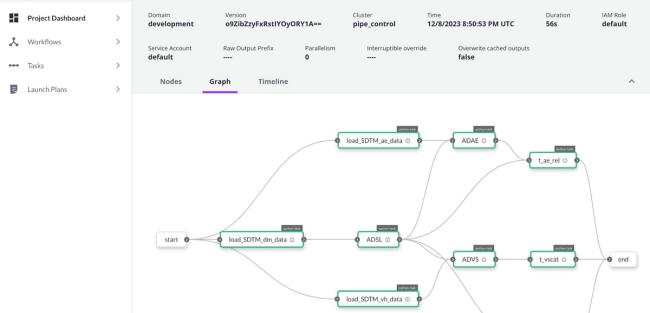
AnnouncementIntroducing Domino Flows: AI orchestration for life sciences made simpleBy Brian Vogl7 min read