Domino 5.0: share and reuse trusted data sources to drive model quality




Introducing data sources in Domino 5.0
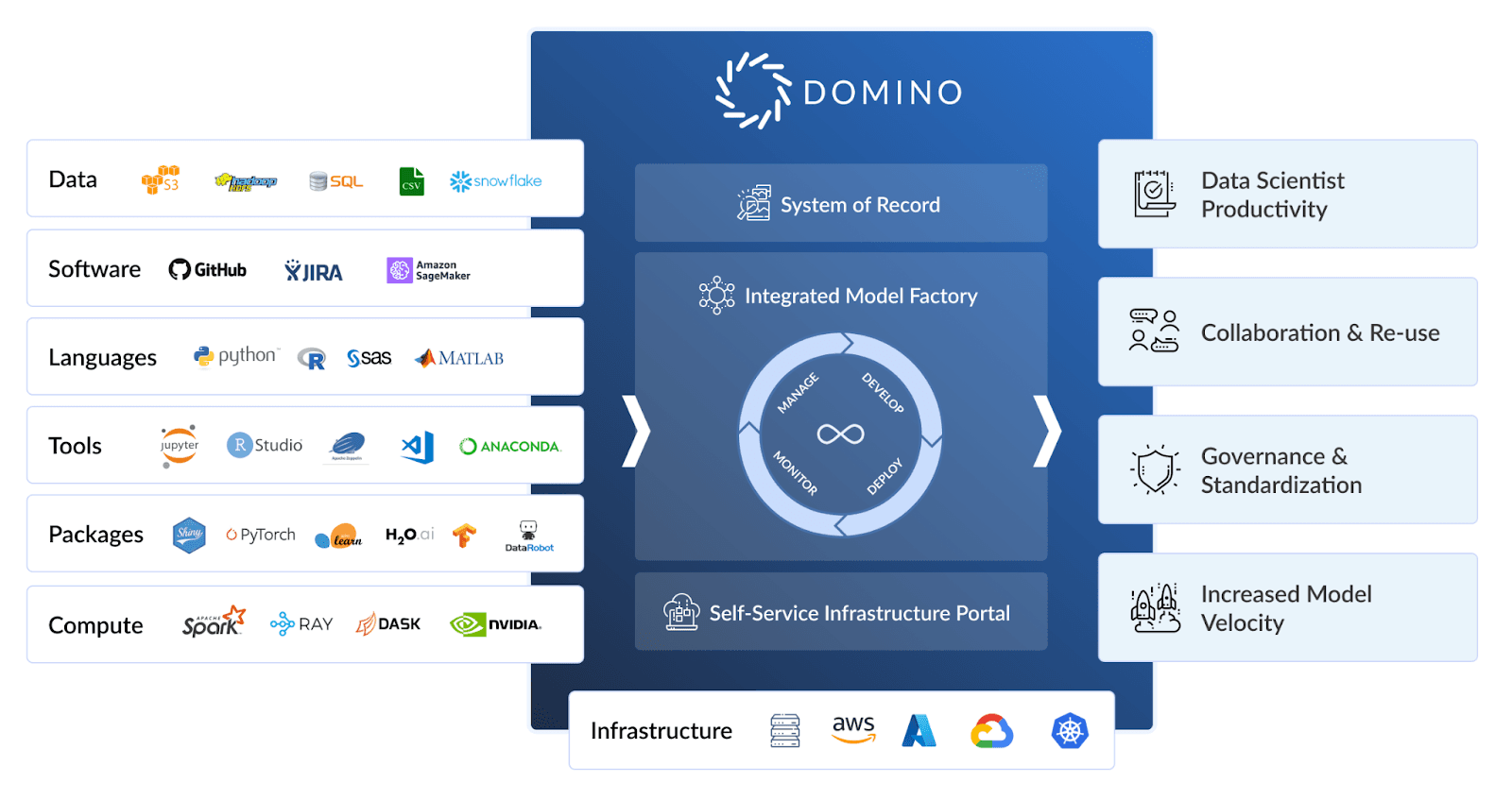
Data scientists waste time figuring out where to find the data they need, getting access to it, and configuring the right tools to connect to it. Domino 5.0 streamlines that entire process with data connectors that let data science teams securely share and reuse common data access patterns.
Domino Data Sources provide a mechanism to create and manage connection properties to a supported external data service. Connection properties are stored securely and there is no need to install data source-specific drivers or libraries. A tightly coupled library provides a consistent access pattern for both tabular- and file-based data.
With Domino 5.0, teams of data scientists can register and configure access to their external data sources, such as Amazon Redshift, Amazon S3, and Snowflake. Once the data source has been registered in Domino, teams can begin to utilize the Data Access Python Library to list and get objects from the registered external data source, or even query tabular data directly into Pandas dataframes!
Data Sources in Domino democratizes access to data by eliminating DevOps barriers related to driver installation, specific libraries, and more. Team collaboration is enhanced through data source connector sharing with colleagues. IT teams will be pleased that the capability supports per-user and service account credentials to maximize flexibility while maintaining the highest levels of data security.
How it works
From the perspective of a data scientist in Domino, configuring a new connector to a data source can be done in a few clicks. In Domino, navigate to the “Data” section on the left-hand navigation bar and select “Connect to External Data”.
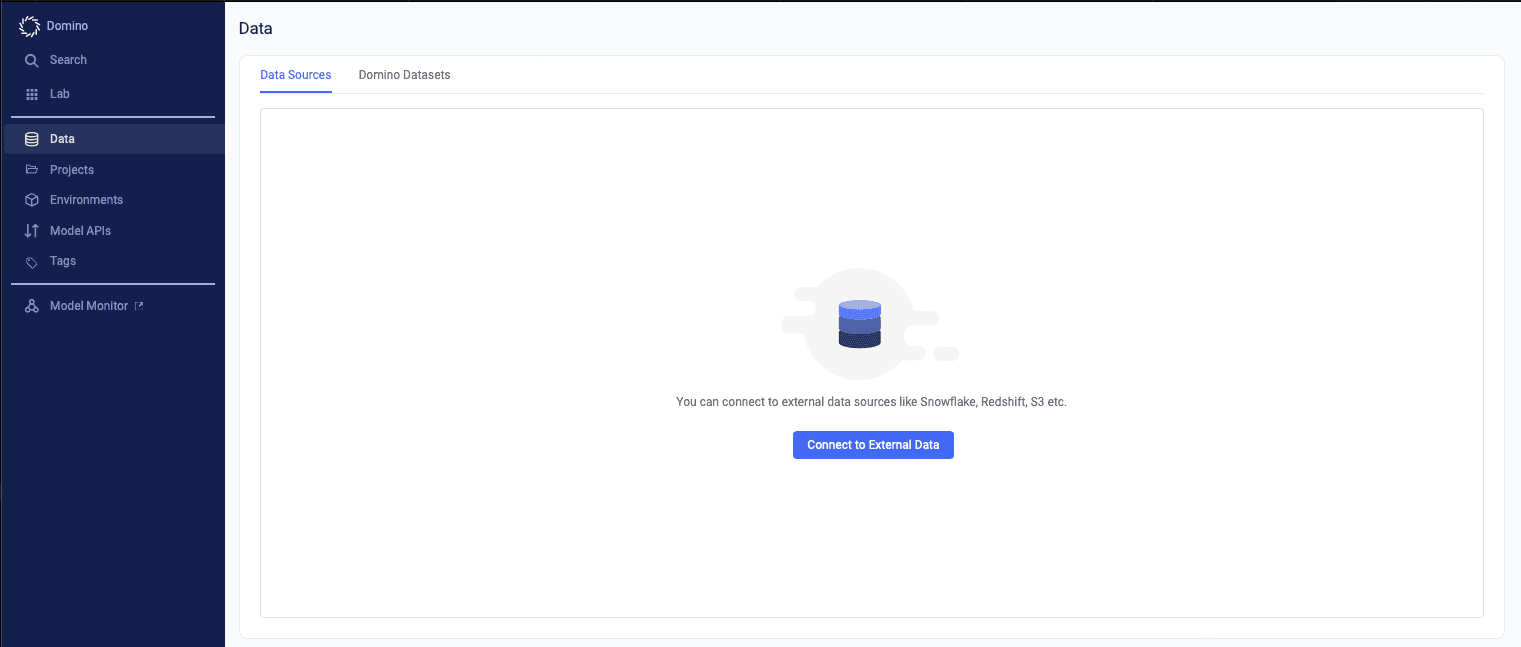
Once the modal window appears, select the type of data store from the dropdown menu. For the purposes of this demonstration, we will be using Amazon S3.
First, you need to add some basic information about the Amazon S3 bucket that you are going to be connecting to.
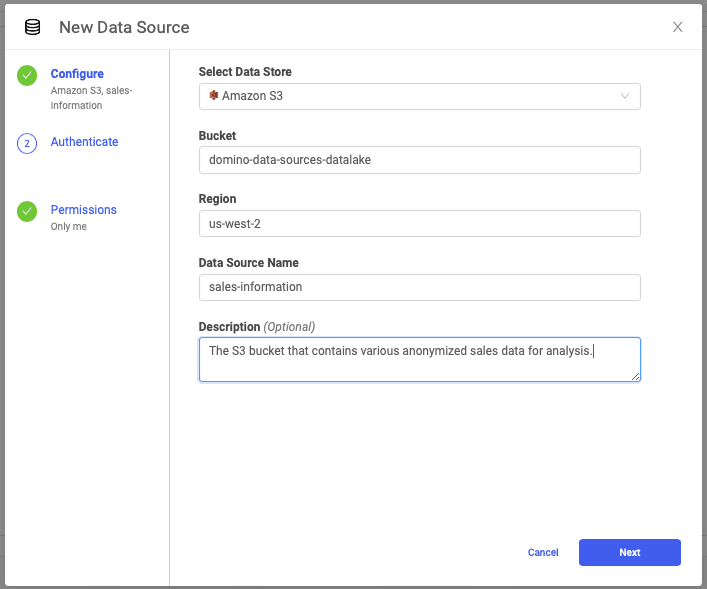
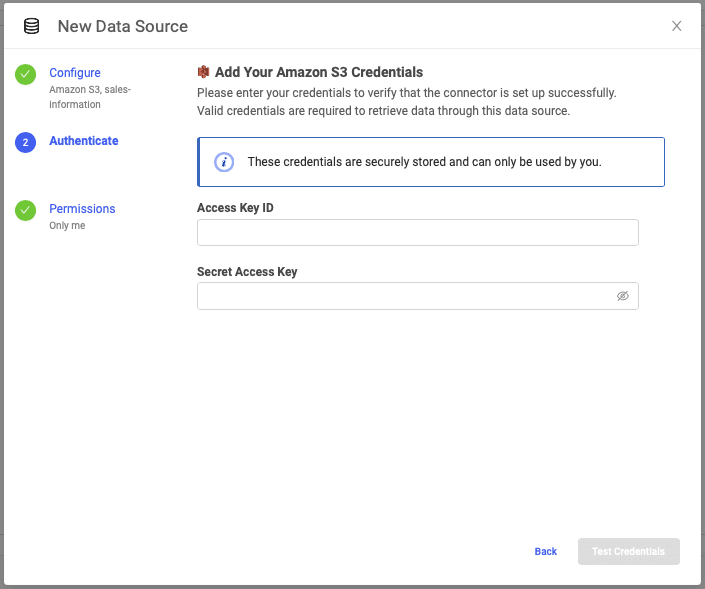
Next, you need to add your AWS credentials to Domino. This process is completely secure, and the credentials are only viewable by you. Not even a Domino administrator has the ability to view your credentials.
You can quickly verify that the credentials working by clicking “Test Credentials”. After validation, you can save the new data connector and begin to use it in Domino.
Navigate to a project in Domino now and click on the “Data” section. You will see a list of data connectors that you have access to. In our case, select the Amazon S3 connector that you configured earlier.
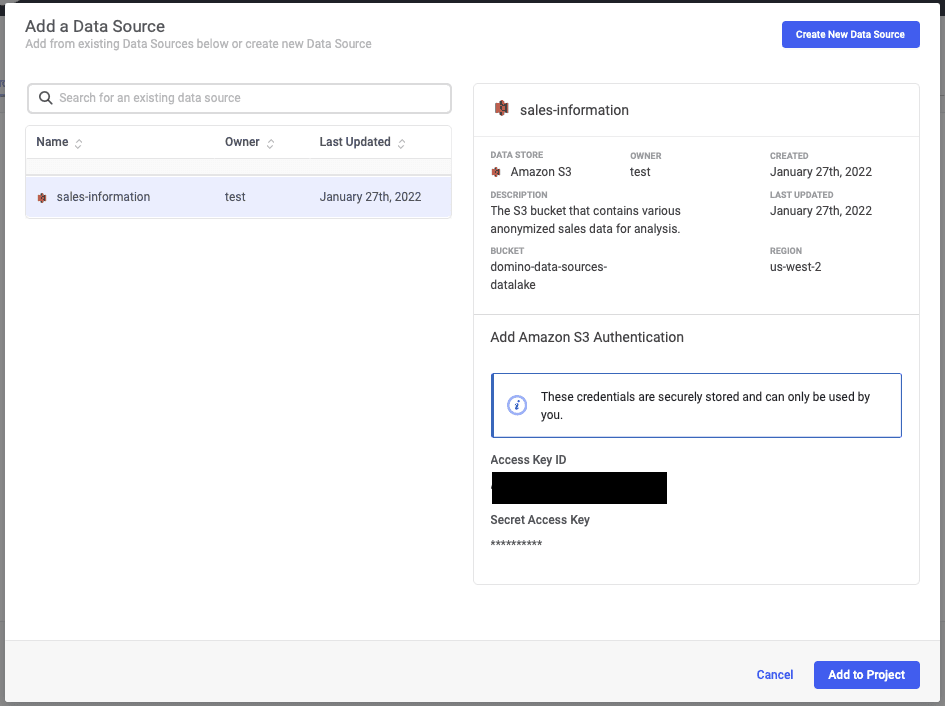
After you have selected the connector to the data source, click “Add to Project” and then start a workspace to begin using it.
As you will see in the screenshot below and the above demo video, you can work with files in Amazon S3 directly via the Domino SDK.
In this example, I am creating a connection to Amazon S3 and then using JupyterLab to download the sales data CSV file that is in my S3 bucket for use in Domino.
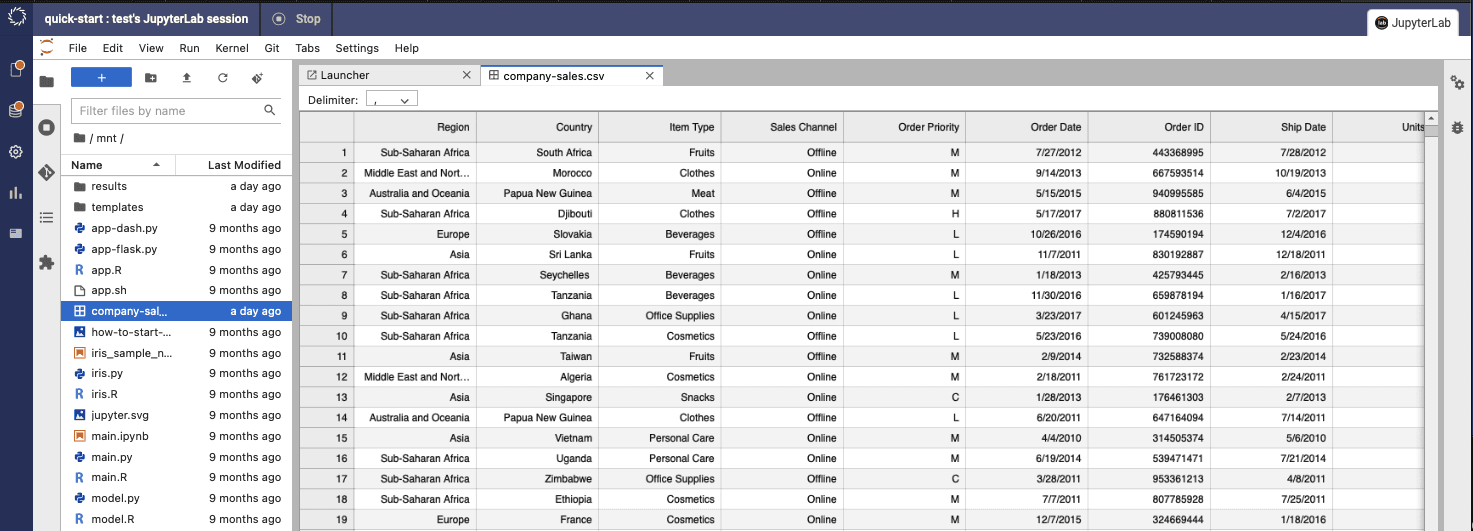
Now that the data is in our Domino workspace, we can continue writing code to extract and use that data!
Powerful Technology Behind the Scenes
Now that we have covered how this works in practice, let’s explore the technical details.
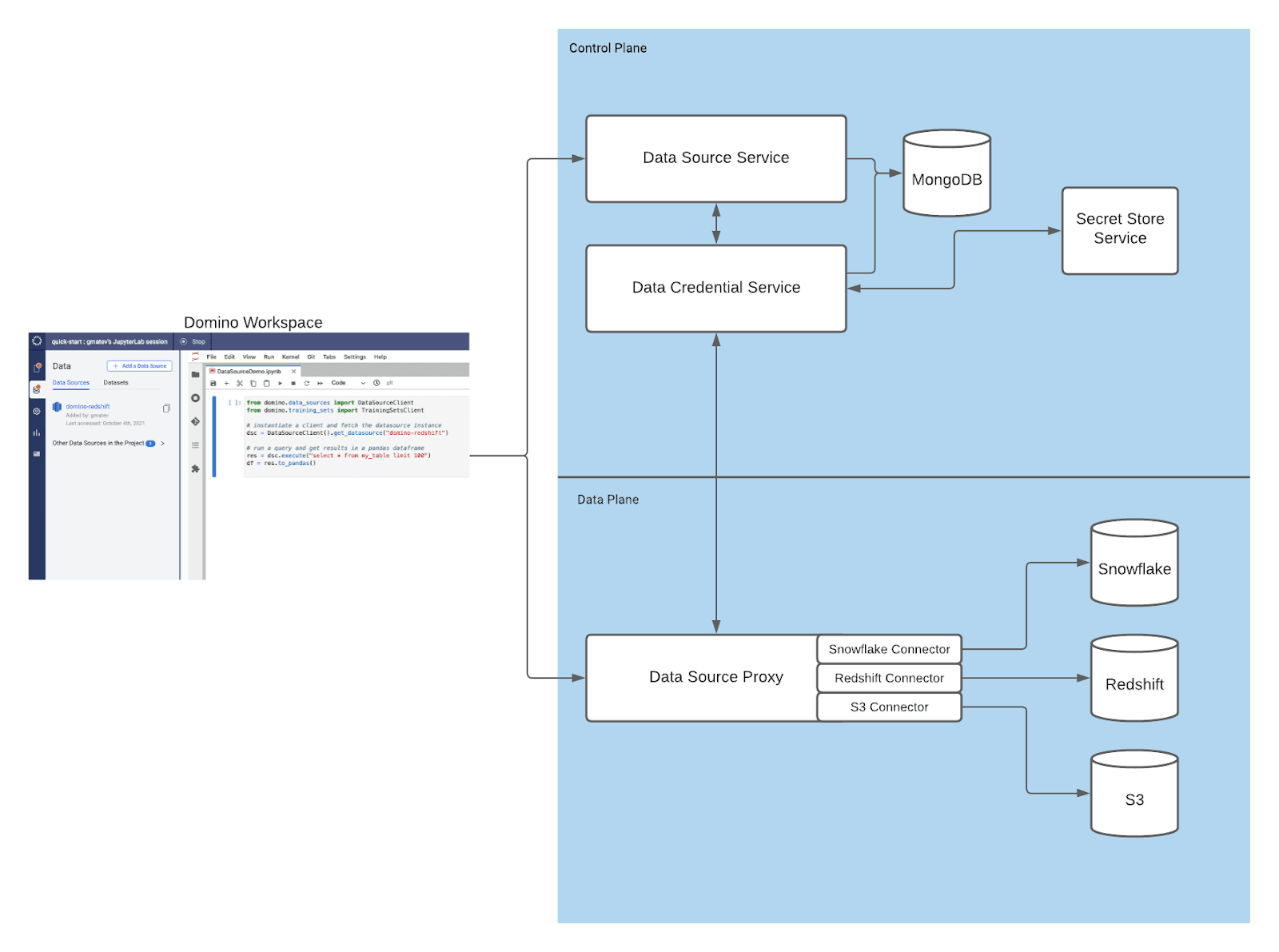
While there is a lot to unpack in the above screenshot, we can start to break this down in sections. Starting from when a user starts their workspace in Domino and begins using the Python library to establish a connection to the external data source, we have numerous components that aid in facilitating this connection for the user.
When a user initiates a query from their workspace or job, a connection is initially made from the running workspace container to the Data Source Service, which is responsible for managing the data source metadata and facilitating the connection to the downstream services. The service will perform a lookup in MongoDB to gather metadata about the data source. MongoDB does not contain any information about credentials, but rather metadata about the data source that will help downstream services establish the connection.
When you add credentials for the data source, they are stored as an access key and secret key in an instance of Hashicorp Vault that is deployed with Domino. We retrieve those credentials securely via the data credential service and pass them into the Data Source Proxy Service – a stateless microservice that acts as a middleman between the upstream services and the data sources the user would like to access, such as Snowflake, Amazon S3, or Redshift. Now that the request has the appropriate metadata and credentials, it is routed to the highly available Data Source Proxy Service to connect to Amazon S3 (in our example).
The various connectors that are produced by Domino utilize vendor-specific Go SDK’s that help facilitate the required prerequisites to connect to the various data sources, such as database drivers. This abstracts the complexity of connecting to data sources away from the data scientist in Domino so that they can use a familiar way to connect to their data each and every time.
Conclusion
Access to the appropriate data is a critical part of any data science project. Historically in Domino and other platforms it was difficult for a user or a team of data scientists to set up, configure, and maintain the credentials and drivers required for connectivity to various data sources. This was especially true for non-power users. With Domino Data Sources, the struggle to get up and running with your data has been alleviated.
Domino is the Enterprise MLOps platform that seamlessly integrates code-driven model development, deployment, and monitoring to support rapid iteration and optimal model performance so companies can be certain to achieve maximum value from their data science models.