Getting Data with Beautiful Soup




Data is all around us, from the spreadsheets we analyse on a daily basis, to the weather forecast we rely on every morning or the webpages we read. In many cases, the data we consume is simply given to us, and a simple glance is enough to make a decision. For example, knowing that the chance of rain today is 75% all day makes me take my umbrella with me. In many other cases, the data provided is so rich that we need to roll up our sleeves and we may use some exploratory analysis to get our heads around it. We have talked about some useful packages to do this exploration in a previous post.
However, the data we require may not always be given to us in a format that is suitable for immediate manipulation. It may be the case that the data can be obtained from an Application Programming Interface (API). Or we may connect directly to a database to obtain the information we require.
Another rich source of data is the web and you may have obtained some useful data points from it already. Simply visit your favourite Wikipedia page and you may discover how many gold medals each country has won in the recent Olympic Games in Tokyo. Webpages are also rich in textual content and although you may copy and paste this information, or even type it into your text editor of choice, web scraping may be a method to consider. In another previous post we talked about natural language processing and extracted text from some webpages. In this post we are going to use a Python module called Beautiful Soup to facilitate the process of data acquisition.
Web scraping
We can create a program that enables us to grab the pages we are interested in and obtain the information we are after. This is known as web scraping and the code we write requires us to obtain the source code of the web pages that contain the information. In other words, we need to parse the HTML that makes up the page to extract the data. In a nutshell, we need to complete the following steps:
- Identify the webpage with the information we need
- Download the source code
- Identify the elements of the page that hold the information we need
- Extract and clean the information
- Format and save the data for further analysis
Please note that not all pages let you scrape their content and others do not offer a clear cut view on this. We recommend that you check the terms and conditions for the pages you are after and adhere to them. It may be the case that there is an API you can use to get the data, and there are often additional benefits for using it instead of scraping directly.
HTML Primer
As mentioned above, we will need to understand the structure of an HTML file to find our way around it. The way a webpage renders its content is described via HTML (or HyperText Markup Language), which provides detailed instructions indicating the format, style, and structure for the pages so that a browser can render things correctly.
HTML uses tags to flag key structure elements. A tag is denoted by using the < and > symbols. We are also required to indicate where the tagged elements start and finish. For a tag calledmytag, we denote the beginning of the tagged content as<mytag>and its end with</mytag>.
The most basic HTML tag is the <html> tag, and it tells the browser that everything between the tags is HTML. The simplest HTML document is therefore defined as:
<html></html>The document above is empty. Let us look at a more useful example:
<html>
<head>
<title>My HTML page</title>
</head>
<body>
<p>
This is one paragraph.
</p>
<p>
This is another paragraph. <b>HTML</b> is cool!
</p>
<div>
<a href="https://blog.dominodatalab.com/"
id="dominodatalab">Domino Datalab Blog</a>
</div>
</body>
</html>We can see the HTML tag we had before. This time we have other tags inside it. We call tags inside another tag "children," and as you can imagine, tags can have "parents". In the document above <head> and <body> are children of <html> and in turn they are siblings. A nice family!
There are a few tags there:
<head>contains metadata for the webpage, for example the page title<title>is the title of the page<body>defines the body of the page<p>is a paragraph<div>is a division or area of the page<b>indicates bold font-weight<a>is a hyperlink, and in the example above it contains two attributeshrefwhich indicates the link's destination and an identifier calledid.
OK, let us now try to parse this page.
Beautiful Soup
If we save the content of the HTML document described above and opened it in a browser we will see something like this:
This is one paragraph.
This is another paragraph. HTML is cool!
Domino Datalab Blog
However, we are interested in extracting this information for further use. We could manually copy and paste the data, but fortunately we don't need to - we have Beautiful Soup to help us.
Beautiful Soup is a Python module that is able to make sense of the tags inside HTML and XML documents. You can take a look at the module's page here.
Let us create a string with the content of our HTML. We will see how to read content from a live webpage later on.
my_html = """
<html>
<head>
<title>My HTML page</title>
</head>
<body>
<p>
This is one paragraph.
</p>
<p>
This is another paragraph. <b>HTML</b> is cool!
</p>
<div>
<a href="https://blog.dominodatalab.com/"
id="dominodatalab">Domino Datalab Blog</a>
</div>
</body>
</html>"""We can now import Beautiful Soup and read the string as follows:
from bs4 import BeautifulSoup
html_soup = BeautifulSoup(my_html, 'html.parser')Let us look into the content of html_soup, and as you can see it looks boringly normal:
print(html_soup)<html>
<head>
<title>My HTML page</title>
</head>
<body>
<p>
This is one paragraph.
</p>
<p>
This is another paragraph. <b>HTML</b> is cool!
</p>
<div>
<a href="https://blog.dominodatalab.com/" id="dominodatalab">Domino Datalab Blog</a>
</div>
</body>
</html>But, there is more to it than you may think. Look at the type of the html_soup variable, and as you can imagine, it is no longer a string. Instead, it is a BeautifulSoup object:
type(html_soup)bs4.BeautifulSoupAs we mentioned before, Beautiful Soup helps us make sense of the tags in our HTML file. It parses the document and locates the relevant tags. We can for instance directly ask for the title of the website:
print(html_soup.title)<title>My HTML page</title>Or for the text inside the title tag:
print(html_soup.title.text)'My HTML page'Similarly, we can look at the children of the body tag:
list(html_soup.body.children)['\n',
<p>
This is one paragraph.
</p>,
'\n',
<p>
This is another paragraph. <b>HTML</b> is cool!
</p>,
'\n',
<div>
<a href="https://blog.dominodatalab.com/" id="dominodatalab">Domino Datalab Blog</a>
</div>,
'\n']From here, we can select the content of the first paragraph. From the list above we can see that it is the second element in the list. Remember that Python counts from 0 , so we are interested in element number 1:
print(list(html_soup.body.children)[1])<p>
This is one paragraph.
</p>This works fine, but Beautiful Soup can help us even more. We can for instance find the first paragraph by referring to the p tag as follows:
print(html_soup.find('p').text.strip())'This is one paragraph.'We can also look for all the paragraph instances:
for paragraph in html_soup.find_all('p'):
print(paragraph.text.strip())This is one paragraph.
This is another paragraph. HTML is cool!Let us obtain the hyperlink referred to in our example HTML. We can do this by requesting all the a tags that contain an href:
links = html_soup.find_all('a', href = True)
print(links)[<a href="https://blog.dominodatalab.com/" id="dominodatalab">Domino Datalab Blog</a>]In this case the contents of the list links are tags themselves. Our list contains a single element and we can see its type:
print(type(links[0]))bs4.element.TagWe can therefore request the attributes href and id as follows:
print(links[0]['href'], links[0]['id'])('https://blog.dominodatalab.com/', 'dominodatalab')Reading the source code of a webpage
We are now ready to start looking into requesting information from an actual webpage. We can do this with the help of the Requests module. Let us read the content of a previous blog post, for instance, the one on "Data Exploration with Pandas Profiler and D-Tale"
import requests
url = "https://blog.dominodatalab.com/data-exploration-with-pandas-profiler-and-d-tale"
my_page = requests.get(url)A successful request of the page will return a response 200 :
my_page.status_code200The content of the page can be seen with my_page.content. I will not show this as it will be a messy entry for this post, but you can go ahead and try it in your environment.
What we really want is to pass this information to Beautiful Soup so we can make sense of the tags in the document:
blog_soup = BeautifulSoup(my_page.content, 'html.parser')Let us look at the heading tag h1 that contains the heading of the page:
blog_soup.h1<h1 class="title">
<span class="hs_cos_wrapper hs_cos_wrapper_meta_field hs_cos_wrapper_type_text" data-hs-cos-general-type="meta_field" data-hs-cos-type="text" id="hs_cos_wrapper_name" style="">
Data Exploration with Pandas Profiler and D-Tale
</span>
</h1>We can see that it has a few attributes and what we really want is the text inside the tag:
heading = blog_soup.h1.textprint(heading)'Data Exploration with Pandas Profiler and D-Tale'The author of the blog post is identified in the div of class author-link, let's take a look:
blog_author = blog_soup.find_all('div', class_="author-link")
print(blog_author)[<div class="author-link"> by: <a href="//blog.dominodatalab.com/author/jrogel">Dr J Rogel-Salazar </a></div>]Note that we need to refer to class_ (with an underscore) to avoid clashes with the Python reserved word class. As we can see from the result above, the div has a hyperlink and the name of the author is in the text of that tag:
blog_author[0].find('a').text'Dr J Rogel-Salazar 'As you can see, we need to get well acquainted with the content of the source code of our page. You can use the tools that your favourite browser gives you to inspect elements of a website.
Let's say that we are now interested in getting the list of goals given in the blog post. The information is in a <ul> tag which is an unordered list, and each entry is in a <li> tag, which is a list item. The unordered list has no class or role (unlike other lists in the page):
blog_soup.find('ul', class_=None, role=None)<ul>
<li>Detecting erroneous data.</li>
<li>Determining how much missing data there is.</li>
<li>Understanding the structure of the data.</li>
<li>Identifying important variables in the data.</li>
<li>Sense-checking the validity of the data.</li>
</ul>OK, we can now extract the entries for the HTML list and put them in a Python list:
my_ul = blog_soup.find('ul', class_=None, role=None)
li_goals =my_ul.find_all('li')
goals = []
for li_goal in li_goals:
v goals.append(li_goal. string)
print(goals)['Detecting erroneous data.',
'Determining how much missing data there is.',
'Understanding the structure of the data.',
'Identifying important variables in the data.',
'Sense-checking the validity of the data.']As mentioned before, we could be interested in getting the text of the blog post to carry out some natural language processing. We can do that in one go with the get_text() method.
blog_text = blog_soup.get_text()We can now use some of the techniques described in the earlier post on natural language with spaCy. In this case we are showing each entry, its part-of-speech (POS), the explanation for POS and whether the entry is considered a stop word or not. For convenience we are only showing the first 10 entries.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(blog_text)
for entry in doc[:10]:
print(entry.text, entry.pos_,
spacy.explain(entry.pos_),
entry.is_stop) SPACE space False
Data PROPN proper noun False
Exploration PROPN proper noun False
with ADP adposition True
Pandas PROPN proper noun False
Profiler PROPN proper noun False
and CCONJ coordinating conjunction True
D PROPN proper noun False
- PUNCT punctuation False
Tale PROPN proper noun FalseReading table data
Finally, let us use what we have learned so far to get data that can be shown in the form of a table. We mentioned at the beginning of this post that we may want to see the number of gold medals obtained by different countries in the Olympic Games in Tokyo. We can read that information from the relevant entry in Wikipedia.
url = 'https://en.wikipedia.org/wiki/2020_Summer_Olympics_medal_table'
wiki_page = requests.get(url)
medal_soup = BeautifulSoup(wiki_page.content, 'html.parser')Using the inspect element functionality of my browser I can see that the table where the data is located has a class. See the screenshot from my browser:
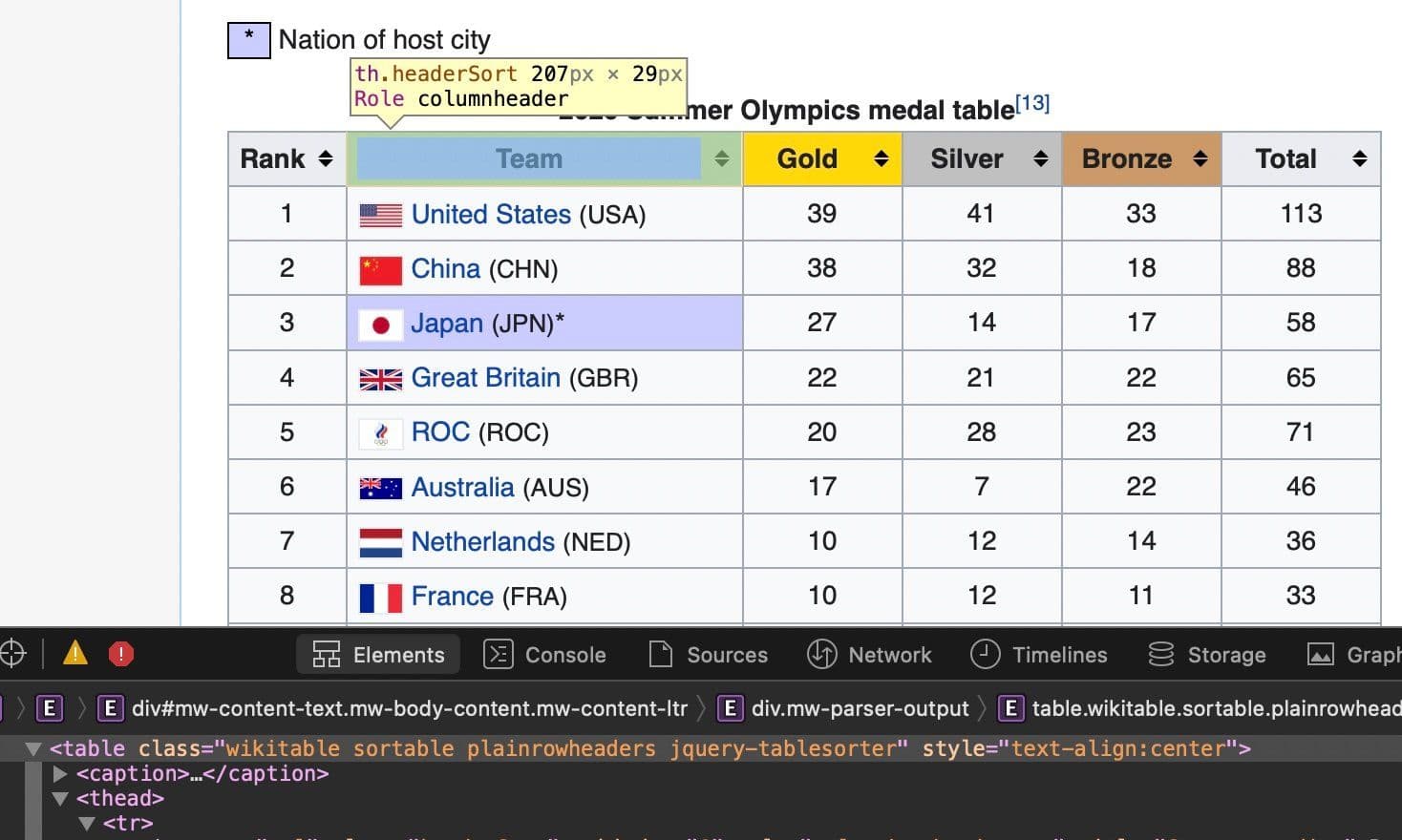
medal_table = medal_soup.find('table',
class_='wikitable sortable plainrowheaders jquery-tablesorter')In this case, we need to iterate through each row (tr) and then assign each of its elements (td) to a variable and append it to a list. One exception is the heading of the table which hasthelements.
Let us find all the rows. We will single out the first one of those to extract the headers, and we'll store the medal information in a variable called allRows:
tmp = medal_table.find_all('tr')
first = tmp[0]
allRows = tmp[1:-1]Let us look a the first row:
print(first)<tr><th scope="col">Rank</th><th scope="col">Team</th><th class="headerSort" scope="col" style="width:4em;background-color:gold">Gold</th><th class="headerSort" scope="col" style="width:4em;background-color:silver">Silver</th><th class="headerSort" scope="col" style="width:4em;background-color:#c96">Bronze</th><th scope="col" style="width:4em">Total</th></tr>As you can see, we need to find all the th tags and get the text, and furthermore we will get rid of heading and trailing spaces with the strip() method. We do all this within a list comprehension syntax:
headers = [header.get_text().strip() for
header in first.find_all('th')]
print(headers)['Rank', 'Team', 'Gold', 'Silver', 'Bronze', 'Total']Cool! We now turn our attention to the medals:
results = [[data.get_text() for
data in row.find_all('td')]
for row in allRows] print(results[:10])[['1', '39', '41', '33', '113'], ['2', '38', '32', '18', '88'], ['3', '27', '14', '17', '58'], ['4', '22', '21', '22', '65'], ['5', '20', '28', '23', '71'], ['6', '17', '7', '22', '46'], ['7', '10', '12', '14', '36'], ['8', '10', '12', '11', '33'], ['9', '10', '11', '16', '37'], ['10', '10', '10', '20', '40']]Hang on... that looks great but it does not have the names of the countries. Let us see the content of allRows:
allRows[0]<tr><td>1</td><th scope="row" style="background-color:#f8f9fa;text-align:left"><img alt="" class="thumbborder" data-file-height="650" data-file-width="1235" decoding="async" height="12" src="//upload.wikimedia.org/wikipedia/en/thumb/a/a4/Flag_of_the_United_States.svg/22px-Flag_of_the_United_States.svg.png" srcset="//upload.wikimedia.org/wikipedia/en/thumb/a/a4/Flag_of_the_United_States.svg/33px-Flag_of_the_United_States.svg.png 1.5x, //upload.wikimedia.org/wikipedia/en/thumb/a/a4/Flag_of_the_United_States.svg/44px-Flag_of_the_United_States.svg.png 2x" width="22"/> <a href="/wiki/United_States_at_the_2020_Summer_Olympics" title="United States at the 2020 Summer Olympics">United States</a> <span style="font-size:90%;">(USA)</span></th><td>39</td><td>41</td><td>33</td><td>113</td></tr>Aha! The name of the country is in a th tag, and actually we can extract it from the string inside the hyperlink:
countries = [[countries.find(text=True) for countries in
row.find_all('a')]
for row in allRows ]
countries[:10][['United States'], ['China'], ['Japan'], ['Great Britain'], ['ROC'], ['Australia'], ['Netherlands'], ['France'], ['Germany'], ['Italy']]You can see from the table in the website that some countries have the same number of gold, silver and bronze medals and thus are given the same rank. See for instance rank 36 given to both Greece and Uganda. This has some implications in our data scraping strategy, let look at the results for entries 35 to 44 :
results[33:44][['34', '2', '4', '6', '12'],
['35', '2', '2', '9', '13'],
['36', '2', '1', '1', '4'],
['2', '1', '1', '4'],
['38', '2', '1', '0', '3'],
['39', '2', '0', '2', '4'],
['2', '0', '2', '4'],
['41', '2', '0', '1', '3'],
['42', '2', '0', '0', '2'],
['2', '0', '0', '2'],
['44', '1', '6', '12', '19']]Our rows have five entries, but those that have the same ranking actually have four entries. These entries have a rowspan attribute as shown in the screenshot for rank 36 below:
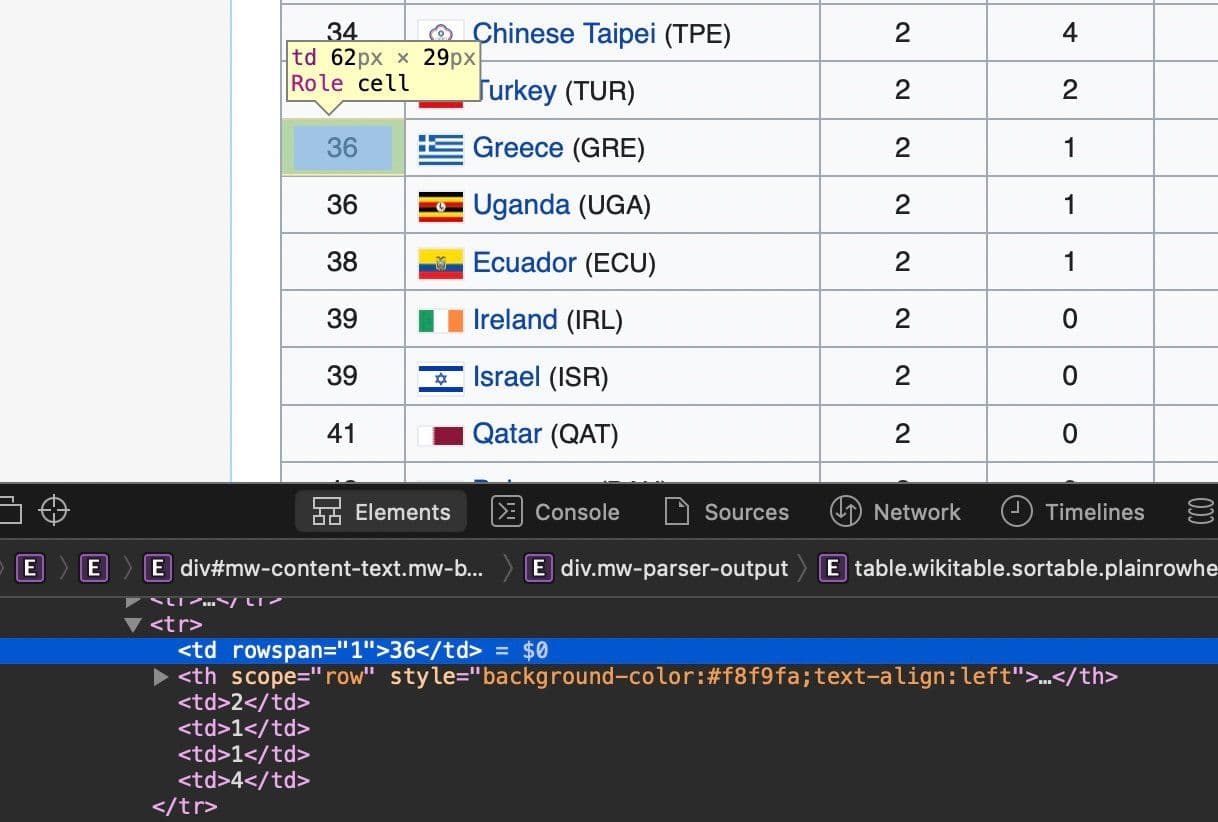
Let us find the entries that have a rowspan attribute and count the number of countries that share the same rank. We will keep track of the entry number, the td number, the number of countries that share the same rank and rank assigned:
rowspan = []
for num, tr in enumerate(allRows):
tmp = []
for td_num, data in enumerate(tr.find_all('td')):
if data.has_attr("rowspan"):
rowspan.append((num, td_num, int(data["rowspan"]), data.get_text()))print(rowspan)[(35, 0, 2, '36'),
(38, 0, 2, '39'),
(41, 0, 2, '42'),
(45, 0, 2, '46'),
(49, 0, 2, '50'),
(55, 0, 2, '56'),
(58, 0, 4, '59'),
(62, 0, 3, '63'),
(71, 0, 2, '72'),
(73, 0, 3, '74'),
(76, 0, 6, '77'),
(85, 0, 8, '86')]We can now fix our results by inserting the correct rank in the rows that have missing values:
for i in rowspan:
# tr value of rowspan is in the 1st place in results
for j in range(1, i[2]):
# Add value in the next tr
results[i[0]+j].insert(i[1], i[3])Let us check that this worked:
print(results)[33:44][['34', '2', '4', '6', '12'],
['35', '2', '2', '9', '13'],
['36', '2', '1', '1', '4'],
['36', '2', '1', '1', '4'],
['38', '2', '1', '0', '3'],
['39', '2', '0', '2', '4'],
['39', '2', '0', '2', '4'],
['41', '2', '0', '1', '3'],
['42', '2', '0', '0', '2'],
['42', '2', '0', '0', '2'],
['44', '1', '6', '12', '19']]We can now insert the names of the countries too:
for i, country in enumerate(countries):
results[i].insert(1, country[0])Finally, we can use our data to create a Pandas dataframe:
import pandas as pd
df = pd.DataFrame(data = results, columns = headers)
df['Rank'] = df['Rank'].map(lambda x: x.replace('\n',''))
df['Total'] = df['Total'].map(lambda x: x.replace('\n',''))
cols = ['Rank','Gold', 'Silver', 'Bronze', 'Total']
df[cols] = df[cols].apply(pd.to_numeric)
df.head()1 | United States | 39 | 41 | 33 | 113 |
|---|---|---|---|---|---|
2 | China | 38 | 32 | 18 | 88 |
3 | Japan | 27 | 14 | 17 | 58 |
4 | Great Britain | 22 | 21 | 22 | 65 |
5 | ROC | 20 | 28 | 23 | 71 |
df['Gold'].mean()3.6559139784946235 df['Total'].mean()11.612903225806452Summary
We have seen how to parse an HTML document and make sense of the tags within it with the help of Beautiful Soup. You may want to use some of the things you have learned here to get some data that otherwise may be only available in a webpage. Please remember that you should be mindful of the rights of the material you are obtaining. Read the terms and conditions of the pages you are interested in, and if in doubt it is better to err on the side of caution. One last word - web scraping depends on the given structure of the webpages you are parsing. If the pages change, it is quite likely that your code will fail. In this case, be ready to roll up your sleeves, re-inspect the HTML tags, and fix your code accordingly.