Polars - A lightning fast DataFrames library




We have previously talked about the challenges that the latest SOTA models present in terms of computational complexity. We've also talked about frameworks like Spark, Dask, and Ray, and how they help address this challenge using parallelization and GPU acceleration.
The Polars project was started in March 2020 by Ritchie Vink and is a new entry in the segment of parallel data processing. If you are already wondering if Polars is yet another Dask, let me reassure you that nothing could be further from the truth. Where Dask tries to parallelize existing single-threaded libraries (think NumPy and Pandas), Polars has been written from the ground up with performance and parallelization in mind. There are also two key elements that make the framework quite unique.
The advantages of using Polars
First and foremost, Polars is written in Rust - a language designed for performance and safety, which is close to "the metal." This gives the framework an edge when it comes to performance because the Rust programming language allows full control over features that matter most in this context, namely - memory access and CPU multithreading. Moreover, Rust brings the added benefit of doing both in a safe manner, catching problems at compile time instead of throwing hazardous errors at runtime. It goes without saying that because Polars is developed in Rust, it can be used both in Python and Rust.
Secondly, Polars is underpinned by Apache Arrow - a framework that provides a standardized column-oriented memory structure and in-memory computing. Arrow's memory format is tailored for efficient flat and hierarchical data operation and addresses the poor performance we observe in Pandas, especially data ingestion and data export.
A key benefit of using Apache Arrow is that its IPC files can be memory-mapped locally, which allows you to work with data bigger than memory and to share data across languages and processes. The emphasis here is on sharing. For example, if you are going from Pandas to Spark you are essentially performing a copy and convert operation (via Parquet) even if all the data is manipulated locally. This serialisation/deserialisation is similar to the dreaded Spark shuffle operation, which we know introduces a substantial overhead and experienced Spark developers try to avoid at all costs. Arrow, on the other hand, keeps all the data in a shared-memory object store and makes it available across process boundaries. This zero-copy approach makes sharing data between processes and languages lightning fast.
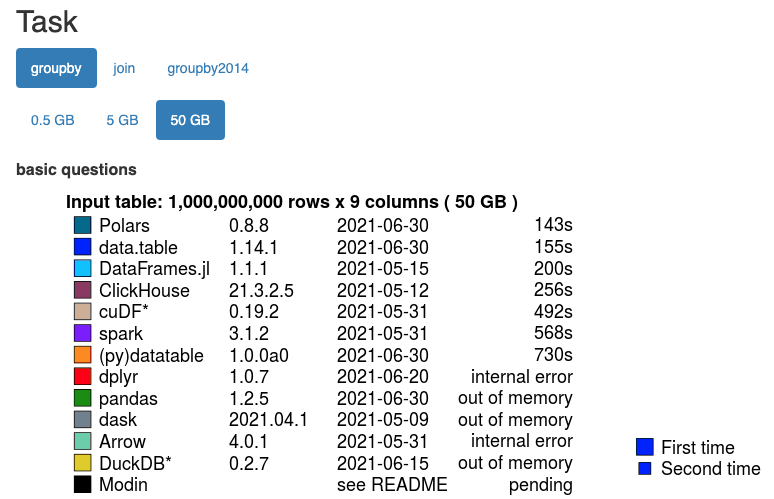
The efficient memory organisation, cache handling, and under-the-hood optimisation give Polars a substantial performance edge in comparison to other entries in the segment. A recent independent benchmark by H2O.ai shows that Polars outperforms the other participants on the 50GB test for both groupby and join operations.
Using Polars from Python
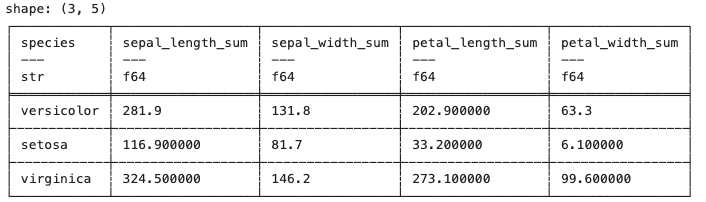
Because Polars relies on Arrow, it leverages Arrow's columnar data format. Interestingly, Polars features both eager and lazy APIs. The eager API's experience is similar to what you'd expect from Pandas, while the lazy API is more SQL-like and more similar to the Spark API. The lazy API is of particular interest because it applies preemptive optimisation against the entire query, thus improving performance and decreasing memory footprint. The go-to example for this type of optimisation would be a chain of FILTER clauses in standard SQL. A typical unoptimised approach runs all statements sequentially, resulting in a number of data frames where each filtering operation materialises a new memory structure. Polars, on the other hand, can transparently merge all the individual filtering conditions and apply the filtering in a single pass during the data reading phase.
import polars as pl
df = pl.read_csv("iris.csv")
print(df.filter(pl.col("sepal_length") > 5)
.groupby("species")
.agg(pl.all().sum()))As we already mentioned, Polars is written in Rust. It does, however, provide a Python wrapper and has interoperability with NumPy and Pandas. Let's first look at the eager API. The following example is taken from the official documentation for the project.
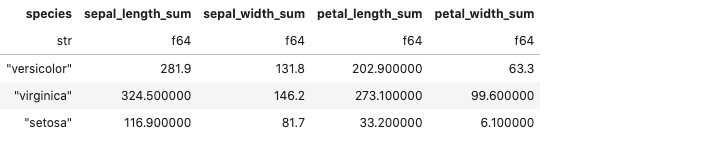
Transforming this to the lazy API is fairly straightforward. All we need to do is start the query with lazy(), as shown below.
(
df.lazy()
.filter(pl.col("sepal_length") > 5)
.groupby("species")
.agg(pl.all()
.sum())
.collect()
)
Notice that you need to trigger the actual execution by using collect() or fetch(). This will sound familiar if you are used to the lazy evaluation in PySpark (i.e. the behaviour of collect() and take())
We can also easily see the impact of query optimisation because Polars can show us the execution plans for individual queries. Let's construct the following query:
q1 = (
pl.scan_csv("iris.csv")
.filter(pl.col("sepal_length") > 2)
.filter(pl.col("sepal_width") > 1.5)
.filter(pl.col("petal_width") > 1)
)
q1.fetch(5)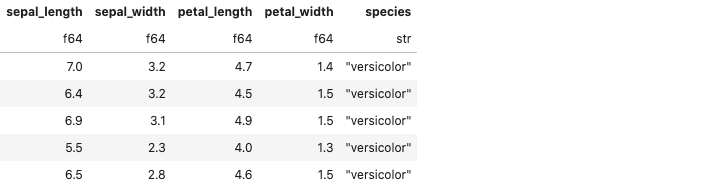
We can now ask Polars to show us the unoptimised execution plan, which looks like this:
q1.show_graph(optimized=False)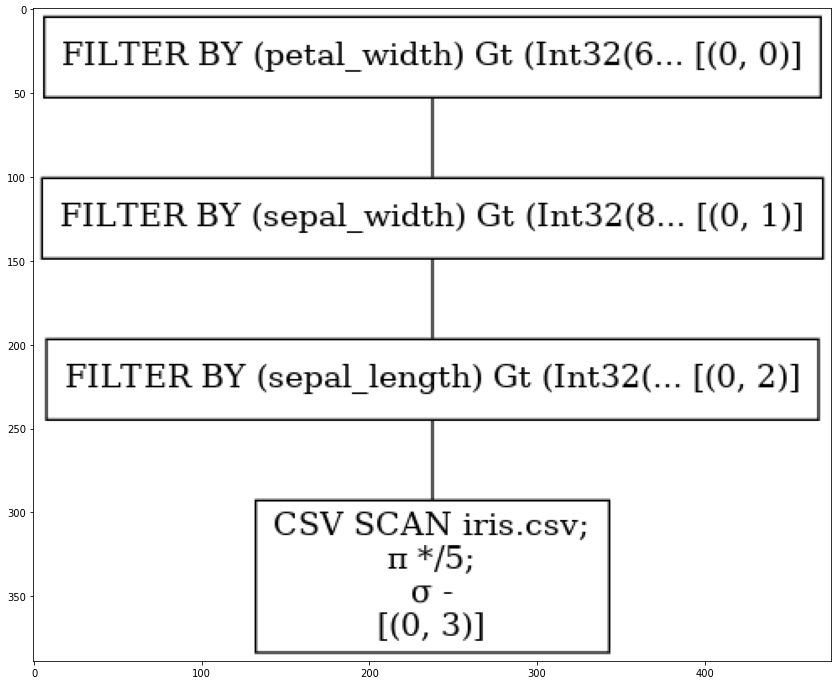
We see that in this case the FILTER BY statements are sequentially applied, resulting in the construction of multiple dataframes. On the other hand, using optimisation changes the plan dramatically:
q1.show_graph(optimized=True)
We see that in the second case the selection is applied at the CSV SCAN level and the unnecessary rows are skipped during the initial data read, thus removing the unnecessary downstream filtering operations.
Summary
The purpose of this article was to introduce Polars as another entry in the accelerated DataFrames space. The project is relatively young, but has been steadily gaining traction, and is definitely something you should consider for your Data Science toolbox. Some of the key enhancements that are currently in the making, according to the Polars creator Ritchie Vink are:
- having an optimal performance for SQL-like queries
- having a declarative predictable API
- being able to do what Pandas can do with a much smaller API surface
Remember, that unlike other projects designed to be drop-in Pandas replacements (e.g. Modin springs to mind), the main design goal of Polars is speed and memory efficiency, not compatibility. People familiar with Pandas will bump into several oddities like the lack of indexing, but nothing you encounter will feel particularly awkward. It is also important to note that Polars DataFrames do not span multiple machines. Where Polars shines is in utilising the multiple cores and memory of a powerful instance. It perfectly fills this unwieldy space where your data is too big for Pandas but too small for Spark.
Additional Resources
You can check the following additional resources:
- Polars Official Documentation - https://pola-rs.github.io/polars-book/user-guide/