The role of containers on MLOps and model production




Container technology has changed the way data science gets done. The original container use case for data science focused on what I call, “environment management”. Configuring software environments is a constant chore, especially in the open source software space, the space in which most data scientists work. It often requires trial and error. This tinkering may break dependencies such as those between software packages or between drivers and applications. Containers provided a way for analytical professionals to isolate environments from each other, allowing analysts to experiment and freeze golden-state environments. Container orchestration has the following benefits in data science work:
- Remove central IT bottlenecks in the MLOps life cycle.
- Better collaboration for data scientists when sharing code and research.
- Old projects can be instantly reproduced and rerun.
Getting models into production is a critical stage in the MLOps life cycle. What role does container technology play in getting ML/AI models into production? In order to answer this question, I’ll lean on an example from the Domino Data Science Platform. Quick background for those who aren’t familiar with Domino: it’s a platform where data scientists run their code (e.g., R, Python, etc), track their experiments, share their work and deploy models. Domino runs on-prem or on all major clouds.
In our example, consider an organization that requires model research happen on-prem for security purposes. However, this organization wishes to deploy the production model to AWS SageMaker to meet the IT requirements of their customer organization. Domino can use containers and its SageMaker Export functionality to meet the needs of this organization. I encourage you to review the blog, How to Export a Model from Domino for Deployment in Amazon SageMaker, posted on the AWS Partner Network, for a more thorough dive into SageMaker Export.
In this case, Domino would be installed on-prem and coordinate collaborative research as usual via containerized experiments, all run via on-prem hardware leveraging a library of container environments, which are also stored on-prem and managed by Domino. After the model has been validated, instead of deploying to the same on-prem server farm that Domino leveraged for the research, Domino packages the entire model environment into a SageMaker-compatible container that is exported to AWS SageMaker for deployment.
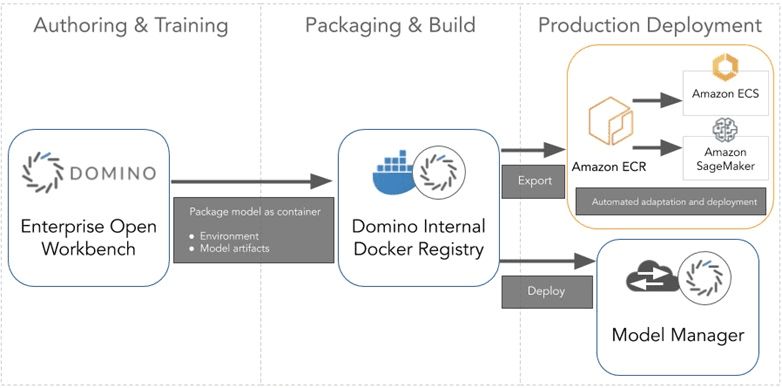
Figure 1 – Options for deploying and hosting models created in Domino.
This is the kind of flexibility that modern organizations are requiring. They want to avoid being locked into any one architecture. Just like containers initially offered flexibility and freedom to data scientists configuring environments, they can also provide organizations flexibility and freedom in working across platforms and architectures. As data science continues to harden the MLOps pipeline with principles such as CI/CD and model validation, it is easy to believe that containers will play a key role in that evolution as well.