Simplify data access and publish model results in Snowflake using Domino




Introduction
Arming data science teams with the access and capabilities needed to establish a two-way flow of information is one critical challenge many organizations face when it comes to unlocking value from their modeling efforts.
Part of this challenge is that many organizations seek to align their data science workflows to data warehousing patterns and practices. This means trading off granularity and latency of data for structures that make it easier to write queries that aggregate, filter and group results for reporting purposes.
Data Science works best with a high degree of data granularity when the data offers the closest possible representation of what happened during actual events – as in financial transactions, medical consultations or marketing campaign results.
That said, there are many advantages to ensuring that data scientists have full access to not only read from, but also be able to write to data warehouse structures. Building pipelines that enable data scientists to be both consumers and producers of information makes it far more likely that modelling efforts reach the end user in a way that they can transform business operations – i.e. create value from the data science efforts.
Domino Data Lab and Snowflake: better together
Domino integrates with Snowflake to solve this challenge by providing a modern approach to data. These modern patterns enable data scientists to draw information from data warehouses, crucially writing model scores and derived data back into data warehouses for end users to be able to access via their reporting and business query tools.
Using Domino dataset capabilities, bring data from Snowflake into an environment that makes disconnected datasets such as CSVs or real-time information pooled from an API connection available.
Domino offers a powerful scheduling function that makes it possible to orchestrate a full workflow, taking data from Snowflake alongside other sources, running model code and writing the results such as predictive scores back into Snowflake for end user consumption—keeping all results in one place and stored together with existing data stores.
Setting up a Domino environment to work with Snowflake.
Domino is natively based on a Kubernetes architecture that enables container-based images to easily be deployed to scalable configurable compute resources. Data Scientists can access docker instructions that allow them to specify their tools and libraries of choice.
To configure an environment for access in Domino, we simply add a connector to that environment via a docker file instruction.
- Login to Domino to find yourself in the “Lab” inside Domino
- Select “Environments” on the sidebar
- Either choose an existing environment to edit or create a new environment
- In Dockerfile instructions, add your chosen Snowflake connector – e.g., Python, R or others such as SQL Alchemy
- Python with PANDAS: RUN pip install snowflake-connector-python[pandas]
- SQLAlchemy: RUN pip install snowflake-sqlalchemy
Authentication by user/account details
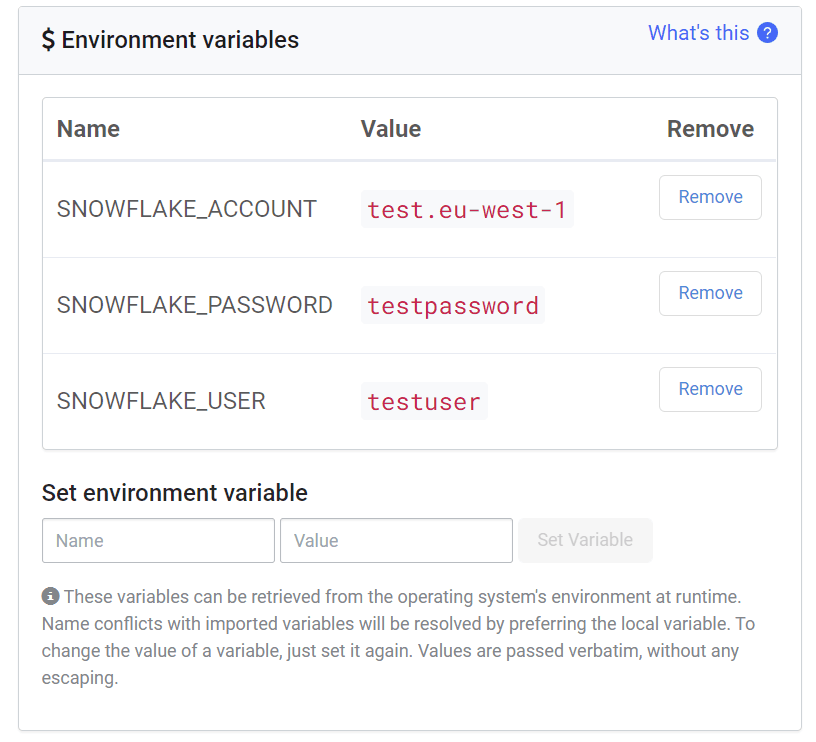
Users store their credentials as environment variables at the project level to enable each project to authenticate with Snowflake. These variables are easily changed and allow each project to have its own independent connection to Snowflake or even multiple Snowflake accounts.
While users can also hardcode variables into their own coding files, using environment variables is a more secure and more flexible option.
To add environment variables to a project:
- Choose a “Project” from the Domino workbench and select “Project Settings” on the sidebar
- Under “Environment Variables” select “Add a New Environment Variable”
- For this example, we will set SNOWFLAKE_ACCOUNT, SNOWFLAKE_PASSWORD and SNOWFLAKE_USER
- SNOWFLAKE_ACCOUNT: The subdomain of your Snowflake Computing URL
i.e https://test.eu-west-1.snowflakecomputing.com/console#/data/databases becomes “test.eu-west-1” as account - SNOWFLAKE_USER: Your Snowflake user credential
- SNOWFLAKE_PASSWORD: Your Snowflake password
- SNOWFLAKE_ACCOUNT: The subdomain of your Snowflake Computing URL
Retrieving information from Snowflake to work with in Domino
Domino provides data scientists with the ability to run code either in workspace environments that provide IDEs such as Jupyter, R Studio or VS Code or conversely to create a job that runs a particular piece of code.
In this example, we use Jupyter and the python connector to retrieve information from Snowflake in the Domino environment to perform some simple profiling on our dataset.
Create a connection to Snowflake using the connector library and Snowflake environment variables setup at project stage
import snowflake.connector
import os
# Connect to Snowflake via Python Connector
ctx = snowflake.connector.connect(
user=os.environ['SNOWFLAKE_USER'],
password=os.environ['SNOWFLAKE_PASSWORD'],
account=os.environ['SNOWFLAKE_ACCOUNT'])
cs = ctx.cursor()Now that we’ve created a Snowflake connection, we write a query to access the “DOMINO_TESTING” database and the table “wine_red” to print results to our Jupyter instance
cs.execute("USE DATABASE DOMINO_TESTING")
results = cs.execute("SELECT TOP 10 * from wine_red")
for rec in results:
print('%s, %s' % (rec[0], rec[1]))cs.closeTo make the data more workable, we’re now going to create a query that writes results into a pandas DataFrame
#Write Snowflake Results into a Pandas Container
import pandas as pd
# Create a cursor object from previous connector and select database
cs = ctx.cursor()
cs.execute("USE DATABASE DOMINO_TESTING")
# Execute a statement that will generate a result set.
sql = "SELECT * from wine_red"
cs.execute(sql)
# Fetch the result set from the cursor and deliver it as the Pandas
DataFrame.df = cs.fetch_pandas_all()
dfWith the data now loaded inside Domino as a data frame, we can query the data repeatedly without causing call backs to the Snowflake instance and manipulate the data as we see fit, such as adding columns to group or categorize the information.
To store Snowflake query results as a permanent object inside a Domino project, we output the results as a CSV file after creating a data frame object to our data directory inside the Domino project.
#Write Snowflake Results into a CSV Output File.
df.to_csv('/mnt/data/wine_red_snowflake.csv', index=False)Writing data from Domino into Snowflake
Once a model has been developed, the model needs to be productionized either via an app, an API or in this case, writing model scores from the prediction model back into Snowflake so that business analyst end users are able to access predictions via their reporting tools.
In this example, we take the results of a churn model that has run a set of predictions on customer data to identify those most likely to churn. We’ll show three ways to write data from Domino into Snowflake:
- Creating a table in Snowflake based on a model output generated as a CSV file
- Overwriting a table in Snowflake based on the model output file
- Appending the new results to an existing Snowflake table.
We will do this using SQLAlchemy in Python which we set up earlier in our environment.
Create the SQLAlchemy context using the same environment variables used with the Snowflake Python connector as well as specify the user role, database and schema that we wish to write data into.
import sqlalchemy as sql
import pandas as pd
import os
# Setup our SQLAlchemy Engine and connection to Snowflake
engine = sql.create_engine(
'snowflake://{u}:{p}@{a}/{d}/{s}?role={r}'.format(
u=os.environ['SNOWFLAKE_USER'],
p=os.environ['SNOWFLAKE_PASSWORD'],
a=os.environ['SNOWFLAKE_ACCOUNT'],
r='SYSADMIN',
d='DOMINO_TESTING',
s='PUBLIC'
))Now we load the CSV File into a Pandas data frame and then write that table into the DOMINO_TESTING database in Snowflake. Note that this will fail if there is already an existing table with the name we provide.
data = pd.read_csv('/mnt/data/modelOut.csv')
data.to_sql('modelOutput', engine, index = False)Now we can access our SQL Browser within the Snowflake portal and see that a new table has been generated with 7900 rows.

If we try and run the same query again, we will receive an error indicating that the table already exists.
ValueError: Table 'modelOutput' already existsWith SQLAlchemy we must specify that we wish to either append results (as in write more results to the bottom of the file) or overwrite results (as in drop the table and recreate). Append results to a table or replace the table by specifying the if_exists argument.
To append results to an existing table, such as updating it with a new set of results, we specify ‘append’ as the argument to the if_exists function.
data = pd.read_csv('/mnt/data/modelOut.csv')
data.to_sql('modelOutput', engine, index = False, if_exists='append')
To drop and recreate the table, we specify ‘replace’ as the argument to if_exists
data = pd.read_csv('/mnt/data/modelOut.csv')
data.to_sql('modelOutput', engine, index = False, if_exists='replace')
Automating the deployment of model results to Snowflake inside Domino
Domino offers its users four ways to deploy data science models into production:
- Publishing an API that can be called by other applications to receive predictions on demand
- Publishing a Web Application that lets users consume data science models through interfaces such as Dash or Shiny
- Publishing a Launcher that lets users provide parameters to an underlying code run to receive specific results (i.e date range)
- Publishing a scheduled job that runs an underlying piece of code in the Domino environment on a repeating basis.
With scheduled jobs, Domino is able to seamlessly link with Snowflake and easily extract data from a Snowflake environment, perform a model run and produce the results of that model back into a Snowflake data table for consumption by end users, using the above functions with the Snowflake Python connector or Snowflake SQLAlchemy engine.
Conclusion
Bringing Snowflake and Domino together makes it easier for researchers and data scientists to access the high-quality information and powerful querying capabilities from Snowflake, while taking advantage of Domino’s open, extensible framework. Together, they empower data scientists to access, transform and manipulate data inside any code library they choose to use.
Data scientists can easily publish model results into Snowflake to make prediction scores and classifications available in the database and automate these model runs, enabling organizations to extract more value from their data and create closer collaboration between data science and business experts who make decisions based on the results of the models.
About Snowflake
Snowflake delivers the Data Cloud—a global network where thousands of organizations mobilize data with near-unlimited scale, concurrency, and performance. Inside the Data Cloud, organizations unite their siloed data, easily discover and securely share governed data, and execute diverse analytic workloads. Wherever data or users live, Snowflake delivers a single and seamless experience across multiple public clouds. Snowflake's platform is the engine powering solutions for data warehousing, data lakes, data engineering, data science, data application development, and data sharing.
Learn more about Snowflake.
About Domino Data Lab
Domino Data Lab is the system-of-record for enterprise data science teams. The platform manages the end-to-end process of developing, deploying, and monitoring models. It offers an extensive array of features making experimentation, reproducibility, and collaboration across the data science life cycle easy to manage, helping organizations to work faster, deploy results sooner and scale data science across the entire enterprise.
Integration features
- Easily connect Snowflake instances and data sources to Domino projects
- Easily pull from and push to Snowflake databases to enable dataset snapshots to be stored inside Domino for version control
- Take advantage of Snowflake’s time travel capabilities allowing you to reproduce historical views of data for up to 90 days
- Provide end-to-end automation and orchestration of model results being deployed into Snowflake instances.