Transformers — self-attention to the rescue




If the mention of "Transformers" brings to mind the adventures of autonomous robots in disguise you are probably, like me, a child of the 80s: Playing with Cybertronians who blend in as trucks, planes and even microcassette recorders or dinosaurs. As much as I would like to talk about that kind of transformers, the subject of this blog post is about the transformers proposed by Vaswani and team in the 2017 paper titled "Attention is all you need" . We will be covering what transformers are and how the idea of self-attention works. This will help us understand why transformers are taking over the world of machine learning and doing so not in disguise.
What are Transformers Models?
Transformers are a type of artificial neural network architecture that is used to solve the problem of transduction or transformation of input sequences into output sequences in deep learning applications. If you want to now more about deep learning you can take a look at our previous blog post where we covered some popular deep learning frameworks.
You may be wondering what we mean by input and output sequences. Well, perhaps thinking of some applications may help. Think for example of speech recognition, protein structure prediction or machine translation. Let us concentrate in the latter: Given a sentence in English (sequence input) we want to find the translation into Japanese (sequence output) that has the same meaning (or as close as possible) as the original sentence. So the input sentence "Optimus Prime is a cool robot" would require us to produce the output "コンボイはかっこいいロボットです" (Yes, Optimus Prime is called Convoy/コンボイ in Japanese).

Simply translating word by word in the order of appearance may result in an output that a human Japanese speaker would consider ungrammatical. For instance, in Japanese the verbs are placed at the end of the utterance, whereas this never happens in English. One of the main questions in sequence transduction is the learning of representations for both the input and output sequences in a robust manner, so that no distortions are introduced. You do not want to mistranslate an important message.
An approach to tackle this challenge is the use of recurrent neural networks (RNNs). Unlike feed forward neural nets, where inputs and outputs are considered to be independent of each other, the output of an RNN depends on the prior elements of a given sequence. This is sometimes dubbed as "memory". Great as the results of RNNs may be, there are limitations in their use, for example finding out the length of the output sequence may be challenging given the fixed-sized input/output vector architecture of RNNs. A better approach is the use of a transformer.
The magic of machine translation works thanks to two components in the architecture: the encoder and decoder. The former is the element that receives each component of the input sequence, encoding (hence the name) it into a vector carrying the context information about the whole sequence. This is sent to the decoder whose job is to understand the context and resolve the output meaningfully.

Since the important information of the original sequence is carried in the context vector, we can see this as the most important part of the architecture. Similarly, it may be the cause of a "traffic jam" in the system. This is where the concept of attention comes into play. Originally proposed in 2015 by Minh-Thang Long, it enables your model to focus on the significant parts of the input sequence as required.
Paying Attention
As we can see, "memory" alone in the model (such as in an LSTM) may not be enough. We need "attention" to help further improve tasks such as machine translation be. Let us take a look at what attention does.
In a sequence-to-sequence model the encoder passes only the last hidden state as the context to the decoder. When attention is used, the encoder passes not only the last hidden state, but actually all of them. This means that the decoder may have a bit more work to do than before. This extra processing is needed as now every hidden state received is associated with a given part of the input sequence. In our sample sentence "Optimus Prime is a cool robot" the first hidden state is related to the word "Optimus", the second to the word "Prime", the third one to "is" and so on. In this way, the decoder gets to do more, but also receives much more information.
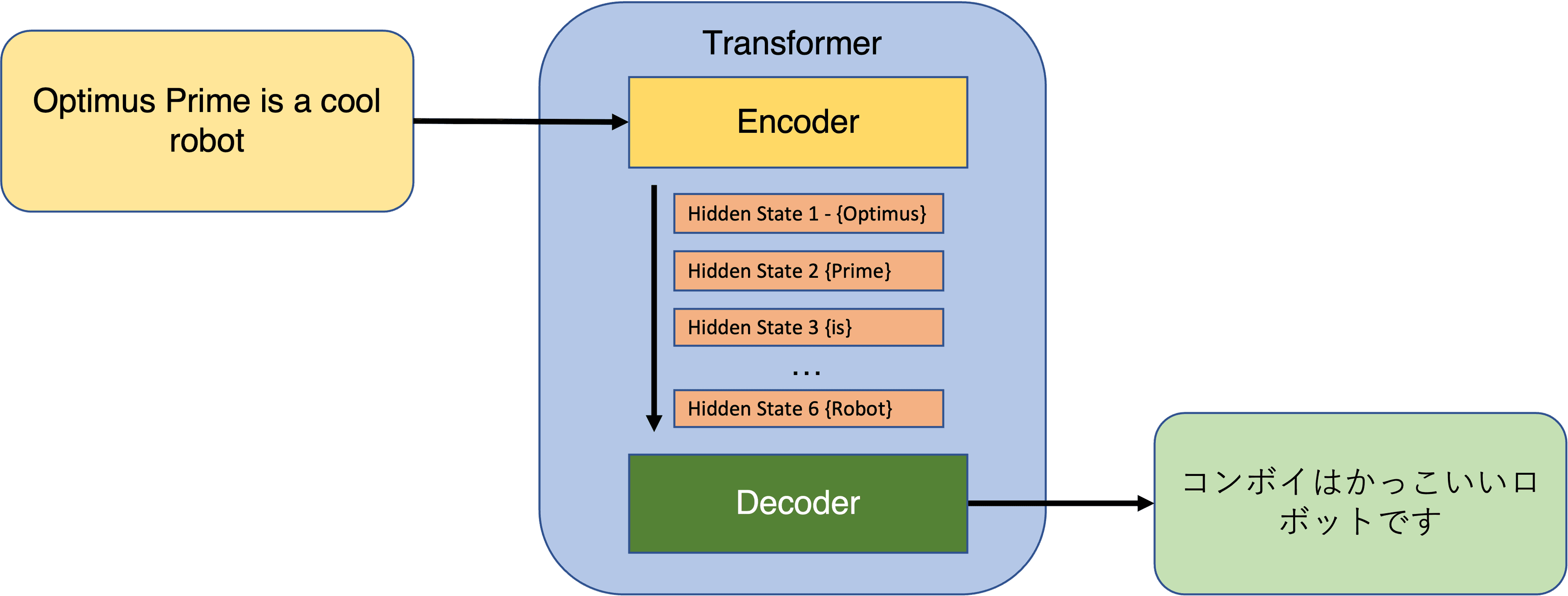
The job of the decoder is now to calculate the weight for each hidden state received by the encoder. This is done with the decoder's own hidden state, in other words, the output of the previous time step in the model. The aim is to provide greater importance to hidden states with higher weight values, and this is our new context vector. We can then use this context as input to the decoder’s feed forward neural net to obtain the output sequence we are after. In turn the output sequence is used as the hidden state of the decoder that is sued in the calculation of weights in the next time step.
Looking Inwards - The Role of Self-Attention
While attention is an important trick up the sleeve of the decoder, we may ask whether the encoder has any tricks of its own. The answer is yes and it is called self-attention. Like attention, self-attention tracks associations from the input sequence, but this time it is the encoder who keeps track of other items to achieve a better encoding. For instance, take the following input sentence:
"Bumblebee plays some catchy music and dances along to it".
If we only track the relationship of words that are close together, we can easily identify that the word "catchy" refers to the "music". If the tracking is only done between two consecutive words, we may end up in a situation where the word "it" at the end of the sentence loses its reference. To a human reader the "it" in the sentence is clearly referring to "music". In a situation with low self-attention however a translating machine may not know this.

In self-attention, the encoder looks for clues in the other elements of the sentence as it processes them. In this way self-attention can be used to extract understanding of each of the processed elements in the sequence. After embedding each element for processing, we need three other components:
- Key: Value \((k:v)\): A key is label for an element in our sequence, used to distinguish it from the others. Each key has an associated value
- Query \((q)\): When we request specific information, we query the keys and select the best match for our request

The understanding extraction is done with the following steps:
- Calculate three arrays called query \(q\), key \(k\) and value \(v\) from matrices created at training time.
- Obtain a score for each element in the input sequence given by the dot product \(q\cdot k\). Note that for the sentence above we would be calculating the score for query "bumblebee" with each of the values ["bumblebee", "plays", "some", "catchy", ...]. The score is scaled by dividing each result with a value \(\sqrt(d_k )\). A typical value is 8, but others can be used.
- Ensure that the scores are normalised, positive and add up to 1. This can be done by applying a softmax function.
- Multiply the value vector \(v\) by the normalised score from the previous step.
- Finally add up all the results into a single vector and create the output of the self-attention. The result is passed to the feed forward neural network.
Transformers and their Applications
A transformer is a neural network architecture that exploits the concepts of attention and self-attention in a stack of encoders and decoders. In the original paper by Vaswani et al. the proposed architect used 6 encoders and 6 decoders. The first encoder would take the input vectors and process them with the self-attention layer before passing it to the feed forward neural net. In a typical architecture each encoder is composed of two parts: self-attention layer and feed forward neural net. Similarly, each decoder is composed of three parts: Self-attention layer, decoder attention layer and feed forward neural net. Once the work of the first encoder is done the result is passed to the next encoder and so on until the final encoder sends the information to the decoders and a similar process ensues.
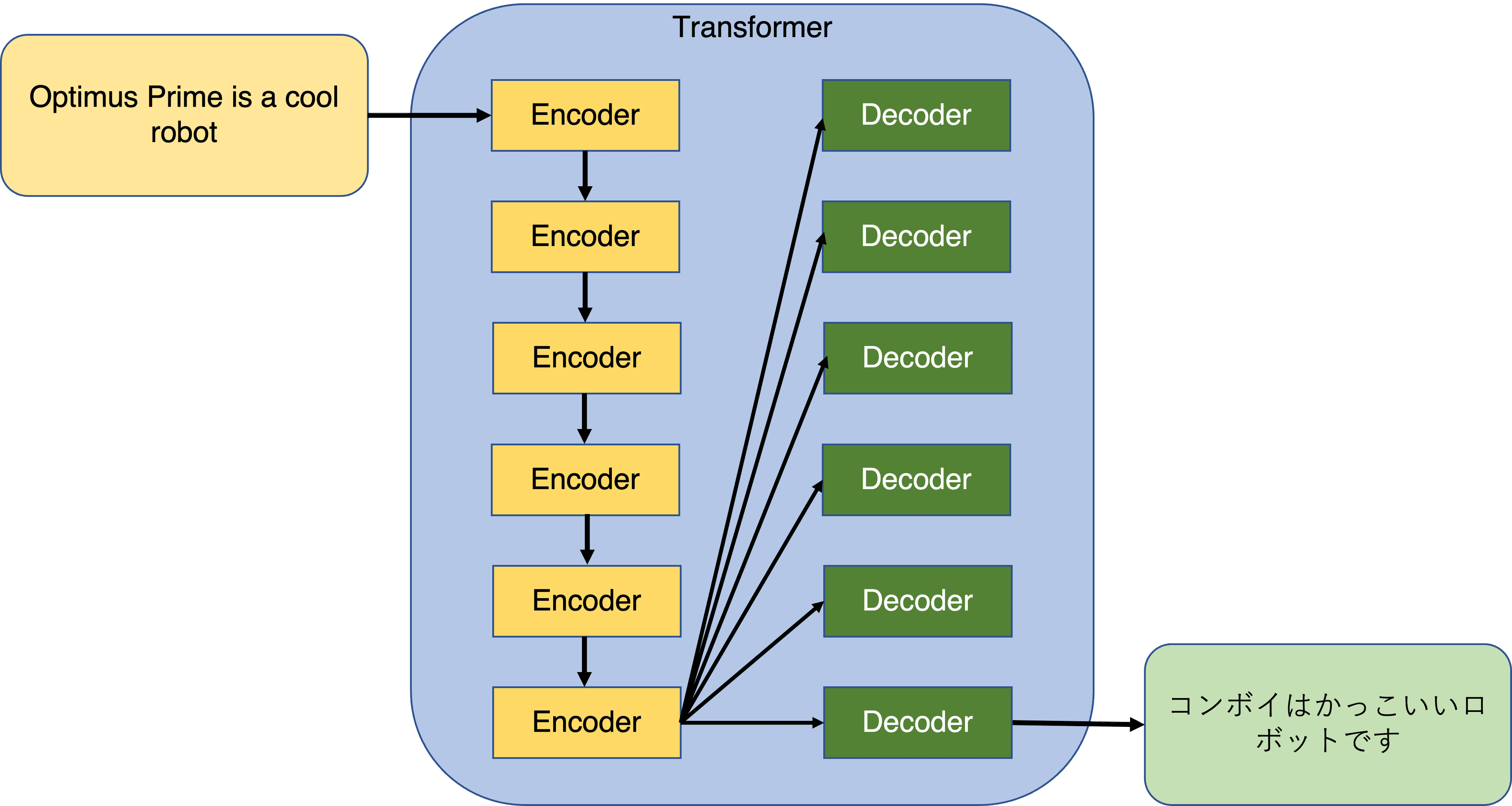
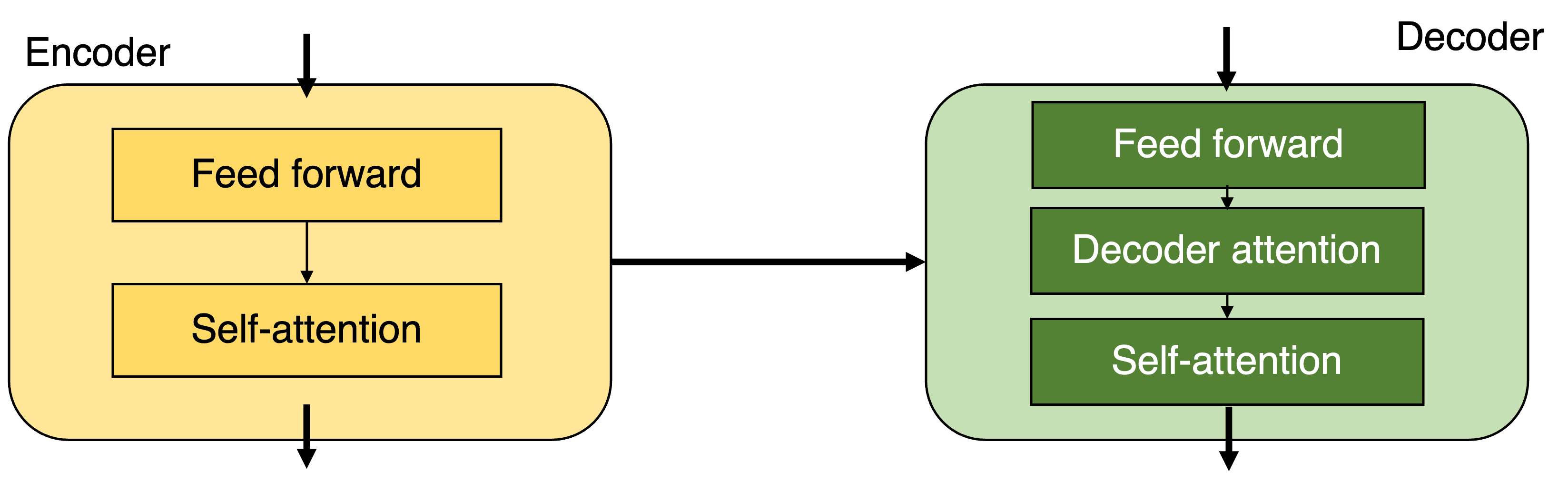
An important advantage of the transformer architecture over other neural networks, such as RNNs is that the presence of context around a word over a longer distance is done in a more efficient way. Furthermore, unlike RNNs the input data needn't be processed sequentially, enabling for parallelisation.
Transformers are rapidly become the tool of choice in natural language processing (NLP) with some pre-trained models such as "Bidirectional Encoder Representations from Transformers" or BERT, and "Generative Pre-trained Transformer 3" or GPT-3 grabbing headlines. GPT-3 can generate new text based on the training data provided and it is said to be powering over 300 applications such as search, conversation, text completion, and more (see here).
Although we have been giving examples of transformers in terms of machine translation, and indeed the architecture was originally developed for that purpose, there are applications for machine vision too. Take a look for instance at this post on image recognition at scale. Just as an NLP transformer uses words to learn about sentences, a machine vision transformer uses pixels to achieve a similar outcome for images.
In the same way that GPT-3 generates new text, the machine vision counterpart would aim to generate new images based on the input provided. That is exactly what Jiang et al. have demonstrated with the use of a two-transformer model: When provided with faces of more than 200,000 celebrities, the model was able to generate new facial images with a moderate resolution.
Other applications are surfacing, and one that we mentioned earlier on in this post is the prediction of protein structures. The publication of AlphaFold in 2021 demonstrated the "first computational method that can regularly predict protein structures with atomic accuracy even in cases in which no similar structure is known." The potential provided by transformers starts to open up the possibilities for multimodal processing, where applications will be able to use multiple types of data, combining media such as images and video, with language. See for example the proposal of VATT or Video-Audio-Text Transformer by Akbari et al.
Accessing Models
As the number of applications grow, access to a variety of frameworks and models is an important consideration when trying to implement transformers in our work. At the time of writing, a lot of transformer models are made available via open-source projects. For instance, BERT has been made available by Google Research here . An important exception is GPT-3 which is currently only available via OpenAI's API product offering.
Given the widespread use of frameworks like TensorFlow, PyTorch or Keras it is not surprising that they already provide transformer models:
- TensorFlow offers a number of text processing tools for text classification, text generation, or translation. Take a look here. Some tutorials are also available, for instance this one to translate Portuguese into English
- PyTorch offers a library called PyTorch-Transformers with state-of-the-art pre-trained models, including BERT, GPT and GPT-2 (earlier iterations of GPT-3)
- Keras users have made available some code samples for text classification, time series classification or speech recognition with transformers
For a variety of pre-trained models you can take a look at Hugging Face and their transformers library with more than 100 models to choose from including BERT, RoBERTa (from Facebook), XLNet (from Carnegie Mellon University), DistilBERT (from HuggingFace themselves), DeBERTa (by Microsoft), Megatron-BERT or Megatron-GPT2 (both from NVIDIA).
Summary
Transformers have come to revolutionise the world of sequence-to-sequence modelling and started to percolate into a number of exciting applications where their encoder-decoder model provides advantages over other neural network architectures. Hinging on the concepts of attention and self-attention, transformers are able to provide wider range of context in a given sequence, improving results for important natural language processing tasks such as speech recognition or machine translation.
Further more, in comparison to other sequential models, transformers are able to provide improved results as we are able to use parallelisation, letting us make the most of our GPUs pushing performance with great results. The next thing to do is to go and start having some fun with transformers; who knows, this may be much more fun than playing with robots in disguise.