“Unit testing” for data science




An interesting topic we often hear data science organizations talk about is “unit testing.” It’s a longstanding best practice for building software, but it’s not quite clear what it really means for quantitative research work — let alone how to implement such a practice. This post describes our view on this topic, and how we’ve designed Domino to facilitate what we see as relevant best practices.
If we knew what we were doing...
To get started, we believe the term “unit testing” isn’t applicable to all types of data science work. That’s because “testing” implies there is a correct answer to the thing you’re testing: a priori, you know what the result should be.
If you are creating a “fahrenheit to celsius conversion” function, you can look up the correct answers and verify that an input of 32 degrees fahrenheit should output 0 degrees celsius.
But we don’t have the luxury of knowing the right answer when we start out working on a new model or analysis. Let’s say you on an insurance data science team, and are building a model to predict the probability of default when someone applies for a loan; or the likelihood that a customer will churn; or the expected claims that will be filed by someone applying for insurance. There is no “correct” answer to a prediction that you can know ahead of time. Of course you have validation data sets, so you measure model performance in various ways. But whether or not a model is “good” or is “improved” is often a matter of interpretation.
Or as Einstein said:
If we knew what it was we were doing, it would not be called research, would it?
There is plenty of data science work that involves building core library functions where there is a clearly defined correct answer — and by all means those functions should be unit tested.
But usually when people ask about "unit testing for data science," they mean something else — and we think it’s all about quality control. The ultimate goal of unit testing in software is to ensure that your code hasn’t introduced problems before you use it somewhere it will have a larger impact. We see this kind of quality control being important in two places in typical data science workflow.
Human gatekeeping
If you or a colleague has made changes to some code and want to replace the old version, how do you know it hasn’t introduced any problems (let alone that it’s improved)? Unit tests help ensure this for software, along with code reviews of course. For data science work, we’ve found it critical to let reviewers inspect results from experiments.
Domino addresses this by automatically logging results when you run code, and letting you inspect those results. Results could be quantitative statistics like the F1-score, p-value, AUC, etc. Or they could be visual results, like an ROC curve. After iterating, when you have a version you like and want to review (or have a colleague review), you can compare them:
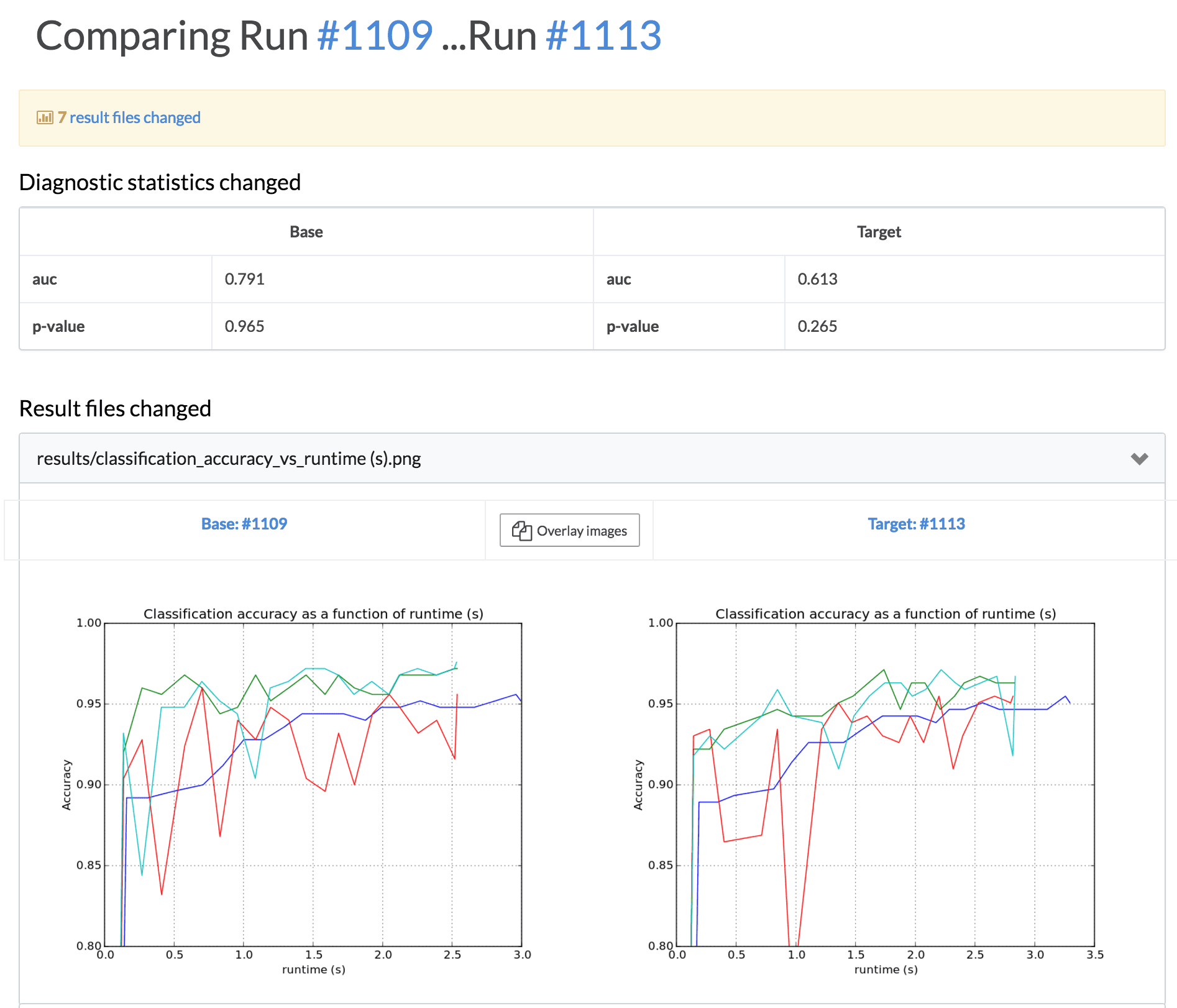
This “review” process can be used as a formal gate before merging a proposed change back into a project.
In the absence of a known “right” answer, we have found that quality control is best achieved through human inspection of results (both quantitative and visual).
Automatic deployment
Another common use case for unit testing in software is to ensure things work properly before deployment to a production environment.
In our case, Domino lets you deploy predictive models as APIs, so that other software systems can easily consume them. And one powerful feature we offer is the ability to schedule retraining tasks: you can run code that retrains your model on new data and automatically redeploys your updated model to production.
In a situation like this, you may want the deployment to fail if your updated model fails to meet certain conditions. To handle that, Domino will abort the deployment if your retraining script throws an error. This allows you to build any gatekeeping checks you want in your programming language of choice. For example, in R:
library(randomForest)library(jsonlite)df <- read.csv("./winequality-red.csv", h=T, sep = ";")df$quality <- factor(df$quality)cols <- names(df)[1:11]clf <- randomForest(df$quality ~ ., data=df[,cols], ntree=50, nodesize=4, mtry=8)runChecks <- function(clf) {finalErr <- clf$err.rate[length(clf$err.rate)]if (finalErr > 15) {stop("error rate too high")}}runChecks(clf)save(clf, file="classifier.Rda")Our code here will train the model, then execute the runChecks function, which will fail if the error rate of the new model is too large.
Domino lets us schedule this “retrain.R” script and automatically deploy the resulting updated model as long as the scripts finish running successfully.
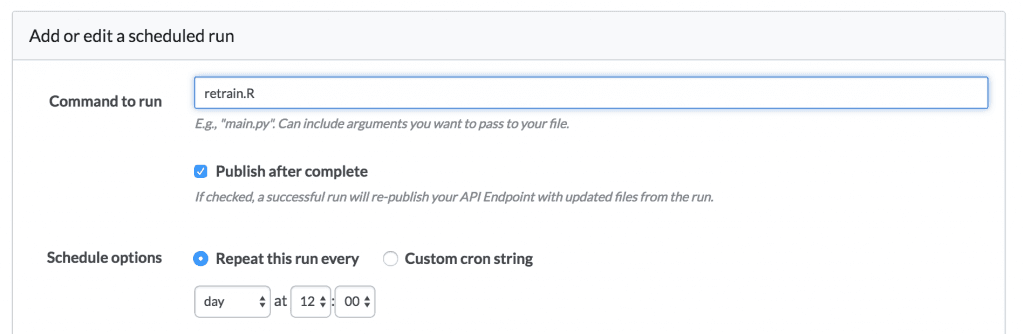
In this way, you can write your own “tests” to ensure that new models aren’t deployed unless they pass your checks, however you define them.
Conclusion
We think “unit testing” is a misguided term for data science workflows. Instead, we prefer to talk about how to achieve quality control and gatekeeping, both for humans and automated deployment processes. Given the nature of quantitative research — complex and without “right answers” known upfront — we think the best way to achieve these goals is to allow visual inspection and comparison of results by humans, and to let users define their own gatekeeping checks for automated deployments.