Visual Logic Authoring vs Code




At some point in their careers, almost every data scientist has written code to perform a series of steps, and thought, “It would be great if I could build these transformations visually rather than by writing code.”
This is the goal of “visual authoring” tools, which aim to enable less technical people to develop analyses. This post describes some of the pitfalls of visual authoring tools, and argues that while they offer an enticing vision, they are ultimately inadequate in the context of real workflows in an enterprise environment. As an alternative approach, we have seen organizations achieve more sustained acceleration of their analytical work by using open source programming languages, investing in training for less-technical users, and using good collaboration and knowledge management tools to make existing work more accessible.
Shortcomings of visual tools
1. Diffing, collaborating, and knowledge management
One property of text that we often take for granted is how easy it is to diff. In any environment where change management is important, being able to compare different versions of your work is critical. In contrast, if your canonical representation of your logic is a diagram, it can be much harder to tell what has changed. There are two common “solutions” for diffing visual logic.
- Some applications will give you a graphical comparison that basically shows you two pictures. That is rarely useful, because it is difficult to distinguish “layout” changes from changes to actual logic or behavior.
- Other applications will let you diff an underlying representation of your logic (e.g., XML). This provides a text-based view, but it is often noisy and full of text about the visual layout rather than your logic, so it is usually inscrutable.
Beyond diffing, many real-world workflows are trivial text-based files but hard with visual tools. For example, if two people work on the same document individually and their work needs to be merged, how can you do that with a visual document? It is also easy to insert comments in, and search text, and more.
2. Vendor/IDE Lock-in
Visual authoring tools have their own proprietary IDEs, which means you will be limited to using them if you want to continue to maintain or improve your analyses. Working with code? It simply consists of text files, so take your pick in how to maintain and edit them.
3. Documentation & “Googleability”
Let's say you're trying to figure out how to make your analysis do some particular operation or data transformation. Most programming languages have active communities online to help you accomplish this. Searching for and reusing code online is easy because the internet is built on text. A simple Google search for most challenges will point you to a StackOverflow page that contains your answer.
This is a much greater challenge for visual tools, because their authoring environments are more proprietary (and thus less popular online). Assuming you could even find an answer to your question, actually using it would be its own challenge — not like copying and pasting a text snippet of code.
4. Extensibility and access to an open ecosystem
Because most visual authoring tools are proprietary (point #2 above), you are often limited to using the “visual widgets” or “recipes” they have already built. This makes it harder to take advantage of the constant evolution in open source packages and libraries accessible from code.
5. Modularity, reuse, refactoring
Code allows you to create functions, modules, packages, etc., which you can use again to accelerate future development and thus avoid reinventing the wheel. Better still, real programming languages have great development tools that allow you to refactor your work easily (e.g., rename things safely), search the codebase, and import existing work you want to leverage quickly.
Some visual tools allow you to package and reuse visual components, but not all of them do. When considering a visual authoring tool, it is important to determine whether visual documents will remain manageable as your library of work grows.
6. Environment efficiency for power users
Finally, it is worth noting that while visual tools are easier for less technical users to work with, that often comes at the price of crippling more sophisticated power users. Power users typically customize their workspaces and IDEs to maximize environment efficiency. Keyboard shortcuts, debuggers, syntax highlighting, and auto-complete are examples of features that allow them to work rapidly within text-based environments.
To retain top performers and maximize their output, it may make sense to empower technically advanced researchers rather than cater to less technical ones.
Exceptional cases
A few visual tools have achieved such a strong presence in the market that they have overcome some of these limitations. For example, Informatica or Ab Initio are massive, mature products that are used widely in enterprise. However, most new attempts at visual logic authoring do not have the same level of adoption and product maturity.
Second-class coding
To address some of the shortcomings above — especially the lack of extensibility and access to open source packages and libraries — many visual authoring tools offer ways to use bits of code within visual flows or pipelines. Most commonly, this takes the form of a new type of visual “widget” that allows you to write arbitrary code, and then uses that to transform its inputs.
Unfortunately, this approach is never more than a band-aid. It permits you to use a couple of code snippets, but it never addresses the fundamental limitations of a visual authoring environment described above. Typically, the code “editor” is grafted onto the main visual editor, and lacks the features necessary for a good authoring experience (e.g., auto-complete, debugging, keyboard shortcuts).
More generally, this approach works well for short snippets, but will not scale to accommodate any substantive logic, nor does it address the core limitations of a proprietary tool that lacks robust ways to compare and collaborate on work products.
What about the users who cannot write code?
The main argument for visual authoring tools is that they are more accessible to less technical analysts, folks who cannot work with code. In our experience, however, most analysts can pick up code more easily than people expect. Code can be daunting when you are starting from scratch, staring at a blank document with no idea what to do. In practice, however, most work involves modifying something that already exists, or borrowing patterns from existing work. From our experience working with a variety of analysts in different industries, we have seen many users who “didn’t code,” but with a little training, were able to open an existing script, make some changes, and borrow patterns from it to use in their own new projects.
Visual documentation
The main argument for visual tools is that they make analysis more accessible to non-technical users. The second argument is that they provide nice documentation of the steps in an analysis. However, code can also provide this benefit of documentation. Rather than grafting “code editors” into primarily visual tools, we have seen companies that are successful with solutions that use code as the fundamental expression of logic, and generate visualization on top of that to aid, say, documentation. This inverts the model of the visual authoring tool: code comes first; visual representation follows.
An example: Drake
As just one example of this approach, consider Drake. Drake allows you to express data transformation and manipulation steps as scripts — it even lets you use R, Python, or other languages for parts of your transformation — but it can also generate a graphical view of your pipeline from that script.
For example, you could have a Drake script that uses Python, Ruby, and Clojure to perform different transformations in a pipeline. Because it is entirely text-based, it is easily diffable and manageable. In addition, Drake also allows you to generate a visual representation of the pipeline. We made a Domino project with an example pipeline (originally from the Drake Github repo) that transforms several input datasets to create several output datasets. Running the script will execute all the transformations to generate the derived outputs, as well as a visualization of its steps:
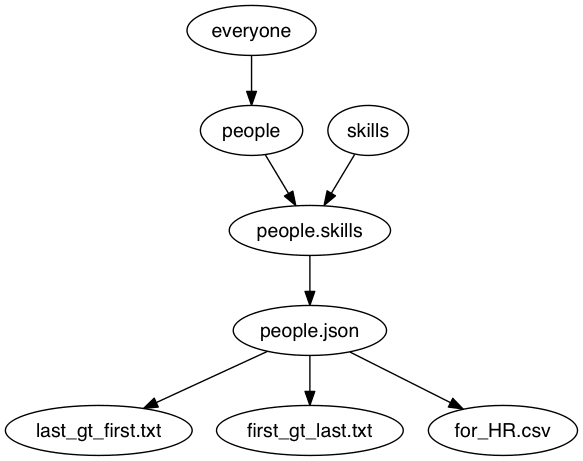
Best of all, because Drake simply runs as a script, you can also run Drake pipelines on Domino, so you can get version control of your scripts, intermediate datasets, and final derived datasets!
Concluding Advice
Analytical organizations are constantly trying to increase their capacity and the pace at which they deliver project work. In our experience, it is shortsighted to invest in a visual logic authoring tool to achieve that goal, with the intention of equipping less technical users to develop analyses. Instead, we have seen companies achieve enormous success when they invest in tooling around text-based logic expression. With a small amount of training for less technical analysts and great knowledge management and collaboration tools (so that folks can find, reuse, and build upon existing patterns and work), you can move faster and avoid building yourself into a corner with a proprietary tool that frays at the edges when you need to collaborate in an enterprise setting.