Bringing Machine Learning to Agriculture




At The Climate Corporation, we aim to help farmers better understand their operations and make better decisions to increase their crop yields in a sustainable way. We’ve developed a model-driven software platform, called Climate FieldView™, that captures, visualizes, and analyzes a vast array of data for farmers and provides new insight and personalized recommendations to maximize crop yield. FieldView™ can incorporate grower-specific data, such as historical harvest data and operational data streaming in from special devices, including (our FieldView Drive) that are installed in tractors, combines, and other farming equipment. It incorporates public and third-party data sets, such as weather, soil, satellite, elevation data and proprietary data, such as genetic information of seed hybrids that we acquire from our parent company, Bayer.
With our platform, farmers can understand the impact of a particular fertilization strategy and adjust as needed. They can spot potential problem areas, such as a plot of land that’s affected by crop disease, earlier so they can quickly take action. Farmers can identify which seeds they should plant in which zones of their farm to get the most out of every acre.
These recommendations aren’t just good for farmers’ wallets; they’re also good for the environment. For example, our models can show farmers how to increase their production while using less fertilizer.
Accelerating Knowledge Gain in Agriculture
The introduction of machine learning to the agricultural domain is relatively new. To enable a digital transformation in agriculture we must experiment and learn quickly across the entire model lifecycle. To that end, we have formed a company strategy and architecture to accelerate the entire model pipeline from conception to commercialization.

Figure 1: The Model Lifecycle
- Data - Bring structure and organization to the company's data assets to enable EDA (Exploratory Data Analysis)
- Feature Engineering - Create, share, and discover features across the company through a set of reusable tools, libraries, and infrastructure.
- Model Building - Train and validate models at scale efficiently and effectively
- Execution - Get insights into the hands of our customers by making the transition from discovery to production as fast as possible
- Monitoring - Ensure models are behaving as expected and understand when it's time to improve
This article focuses on accelerating model development.
Accelerating machine learning model development revolves around two main factors: the ability to acquire new knowledge and to find knowledge generated by others. By making it simple and easy to discover new insights and leverage the insights of others, a network effect is created to accelerate future discovery.
Every experiment we run, every feature we generate, and every model we build must be discoverable and usable for every scientist in the company. Secondly, because of the variety and volume of data we must bring together -- everything from the genome of the seed, the weather, the soil type, management practices, satellite and drone imagery (see Figure 2.)-- the data and training infrastructure must be flexible, scalable while eliminating time consuming tasks that don't add to the knowledge acquisition cycle. Our objective is to let data scientists be data scientists instead of data or infrastructure engineers.
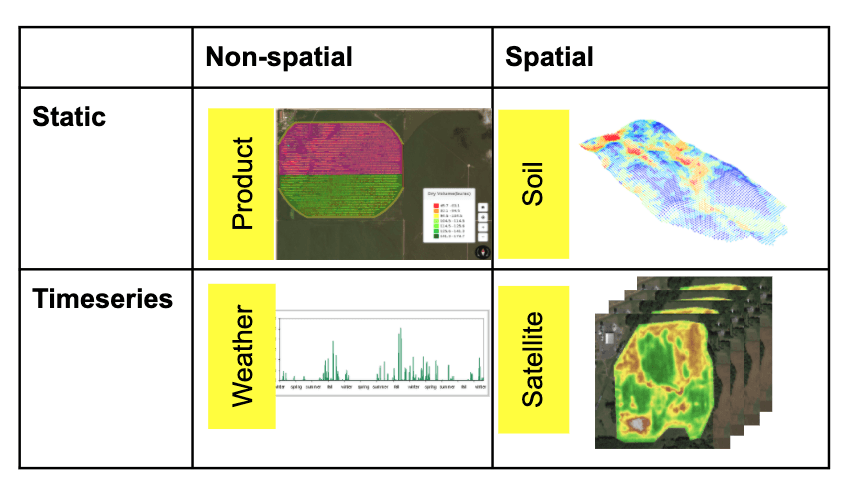
Figure 2: The Variety of data at The Climate Corporation
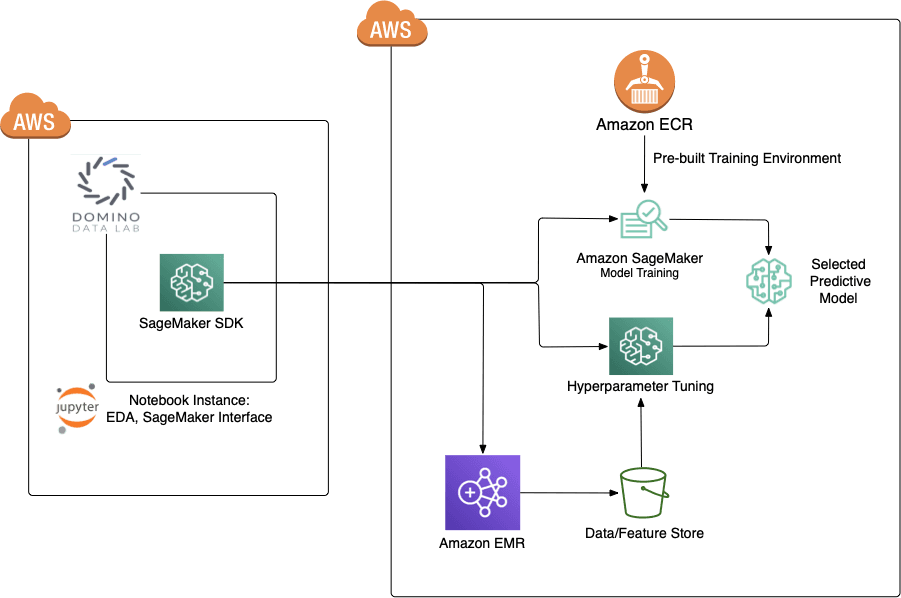
We chose to leverage the best features of Domino Data Lab, Amazon Web Services (AWS), and the open source community to solve this knowledge acceleration problem.
Domino Excels at Usability and Discovery
At The Climate Corporation, we have taken the prebuilt Domino containers and extended them to work within our environment. Everything from Identity and Access Managements (IAM) policies to common package installation, to connectivity to Spark on Amazon EMR is ready for use by the scientist. With the click of a button they have an environment ready to go, and Domino provides a simple extension point for scientists to customize the environment without needing to know the intricacies of Docker.
Domino shines in reproducibility and discovery. Every single run of a project is recorded and recallable. Experimentation and collaboration are built into the core of the platform. The true knowledge acceleration however, occurs by discovery of others research on the platform. With a simple keyword search a scientist can scan projects, files, collaboration comments, prior runs, user created tags and more to find other relevant research or subject matter experts.
Amazon Sagemaker, Spark on Amazon EMR, and Petastorm speed knowledge acquisition
As previously mentioned, our domain contains a large amount of data of a variety of shapes and sizes, we need a data format and training platform that can handle this complexity and scale. We want the platform to be simple and to work with multiple frameworks and with our existing infrastructure. We needed an "evolvable architecture" which would work with the next deep learning framework or compute platform. The choice of model framework or between 1 machine or 50 machines shouldn't require any additional work and should be relatively seamless for the scientist. Likewise, a set of features should be reusable by other frameworks and technologies without expensive format conversions.
Why Sagemaker?
- Ready to run and extensible training containers
If you have ever tried to build a TensorFlow environment from scratch you know how difficult it is to get the correct versions of all the dependencies and drivers working properly. Now we can simply choose one of the pre-built environments or even extend a container to add Petastorm or other libraries like we did here.
- Instant training infrastructure
By simply changing the configuration in your API call to SageMaker, you can create training infrastructure with varying combinations of CPU, GPU, memory and networking capacity that gives you the flexibility to choose the appropriate mix of resources. This ability enhances the efficiency of operational management and optimizes the cost of experimentation.
The built-in ability to try multiple combinations of hyperparameters in parallel instead of performing these tests in serial greatly accelerates the model building process by improving the efficiency of experimentation.
Why Petastorm?
Our scientists and teams are familiar with working in Spark on EMR and using data with our existing feature store and data warehouse. Petastorm makes it easy to create interoperable datasets that can be used for multiple purposes without having to learn a new set of tooling or write datasets in multiple formats (ie. TFRecord and Parquet). By creating a thin layer over parquet, Petastorm data can be used in Spark SQL queries or work in a deep learning training workflow without modification. And because it's parquet, we get all the benefits of parquet, including self-describing schema and IO optimizations. For a complete understanding of the benefits of Petastorm, check out this blog.
Putting it All Together
Here are excerpts from an example workflow using Domino, Petastorm and SageMaker using the MNIST dataset. The full example is available here.
- Create a project in Domino and launch a workspace:
- Create our Petastorm features:
- Train on SageMaker with five machines:
- Key part of our entry_point script where we read the petastorm dataset and transform it into tensors.
- The results of the run are saved in my Domino workspace automatically for repeatability and the model persisted to Amazon S3 for later promotion to production by other parts of our infrastructure stack.
What's next?
By following this pattern of aligning the infrastructure with the model lifecycle and focusing on accelerating the knowledge acquisition process through the democratization of data, features, model, and experimentation, we have been able to rapidly increase the number of models deployed and the time it takes to deploy them year after year. The next bold step for us will be to cut down the feature engineering challenges around combining the various types of temporal, spatial and non-spatial data in a way that is easy for our scientists to use in training models. We have the infrastructure to iterate rapidly on a model once the training set is created, but we want to further eliminate the data engineering task from the role of a data scientist, and let them be a data scientist.