Git Integration in Domino




We recently released new functionality that provides first-class integration between Domino and git. This post describes the new feature, and describes our perspective on the unique requirements of version control in the context of data science—as distinct from software engineering—workflows.
The Problem
On a now famous tweet, Isaac Wolkerstorfer once said: “git gets easier once you get the basic idea that branches are homeomorphic endofunctors mapping submanifolds of a Hilbert space.” Although he clarified in a Quora answer that the statement is firmly tongue in cheek, by the proliferation of the meme and the thousands of Google results one finds when searching for that string, it's clear the answer resonated.
In a recent poll of data scientists, over 85% responded affirmatively that they were leveraging git in their workflow. An overwhelming number of data scientists reached out directly and shared a sentiment that they used git, but only in a cargo cult fashion. Commands are memorized and repeated as an incantation to the reproducibility gods, that they may smile upon this project and let the results and findings survive and thrive. We think there’s a better way.
Domino’s Git Integration
The integration of Domino data science platform deeply leverages both the power of git and our reproducibility engine technology. This integration supports many workflows and is being used today by Fortune 50 customers to allow their data science teams to get value from their existing investment in software, pipelines, and git infrastructure.
Three highlights of this integration include:
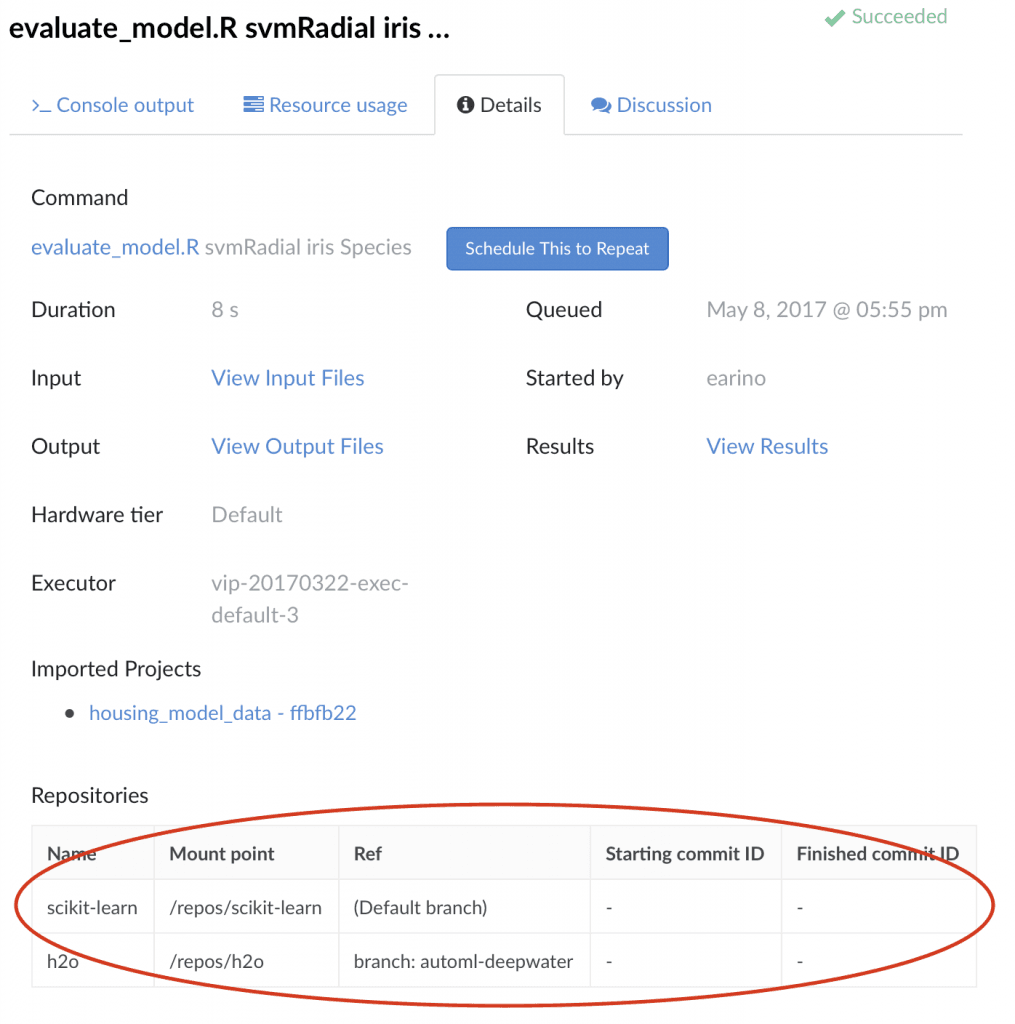
Ability To Check Out Multiple Repositories at exact Commit Hashes
Any git integration which just let’s you handle a single branch or can only check out HEAD is too limited to be of real use. Domino allows you to add an arbitrary number of repositories, each one can be enabled or disabled independently, and can have the exact commit hash or branch specified upon checkout.
Integration with Reproducibility Engine
For every experiment you execute within Domino, the reproducibility engine keeps a record of exactly which repositories were enabled, and what was their starting and ending commit state. If, during your project, you have to commit and push back changes in the repository, Domino tracks this information and makes it immediately available within the details tab of the experiment.
This functionality extends on our ability to track information about canonical datasets imported into the project, environments, etc. Customers can leverage this information to make informed decisions about what internal tools they are using, and more easily provide a bird’s eye view of the dependencies and packages their teams utilize every day.
Unsaved Work Validation
If a project is integrated with git, and the user has changes inside of their repository, Domino will provide helpful reminders if they attempt to close the experiment without first saving and committing their changes.
Data scientists are not necessarily expert git users. For instance, we learned from working with data science teams that there was confusion about when work was really saved to a git repository.
Domino’s integration isn’t just about making a git repository available, it’s about understanding how data scientists work with git, and providing the tools and workflows that make leveraging enterprise codebases as easy as possible.
Conclusion
The work of data scientists is complex, often spanning multiple disciplines. From software engineering to mathematics and statistics, operations research, physics, and many other fields, data scientists are required to do their work quickly and reproducibly.
Version control systems provide an important tool in the toolbox of reproducibility, but they are designed to track software artifacts. They are not sufficient for the complex interactions between code, data, environments, packages, and external and internal repositories used by data scientists every day.
Data scientists finally have version control and reproducibility designed around the way they work. Whether working on experiments, pipelines, visualizations, models in production, or anything else, Domino’s reproducibility engine, along with its first-class git integration, provides the tools and security data scientists trust to safeguard their work for themselves and future collaborators.