



Maintaining Data Science at Scale With Model Monitoring
This article covers model drift, how to identify models that are degrading, and best practices for monitoring models in production. For additional insights and best practices beyond what is provided in this article, including steps for correcting model drift, see Model Monitoring Best Practices: Maintaining Data Science at Scale.”
A growing number of decisions and critical business processes rely on models produced with machine learning and other statistical techniques. (e.g., claims processing, fraud detection, and loan approval). These models are inherently probabilistic, and each model’s behavior is learned from data.
Once in production, a model’s behavior can change if production data diverge from the data used to train the model. Said differently, a model’s behavior is determined by the picture of the world it was “trained” against — but real-world data can diverge from the picture it “learned.” This is similar to how you’d train a mouse to perfectly navigate a maze; the mouse would not perform as well when placed into a new maze it had not seen before.
Creating additional risk, models often depend on data pipelines and upstream systems that span multiple teams. Changes or errors in those upstream systems can change the nature of data flowing into the models, often in silent but significant ways.
The phenomenon of models degrading in performance is called “drift.” Regardless of the cause, the impact of drift can be severe, causing financial loss, degraded customer experience, and worse.
Models Degrade over Time
Models can degrade for a variety of reasons: changes to your products or policies can affect how your customers behave; adversarial actors can adapt their behavior; data pipelines can break; and sometimes the world simply evolves. The most common reasons fit under the categories of Data Drift and Concept Drift.
Data Drift: Data drift occurs when production data diverges from the model’s original training data. Data drift can happen for a variety of reasons, including a changing business environment, evolving user behavior and interest, modifications to data from third-party sources, data quality issues, and even issues in upstream data processing pipelines. For example, if readings from an industrial sensor started changing over time due to mechanical wear and tear, that would lead to data drift.
Concept Drift: Concept drift occurs when the expectations of what constitutes a correct prediction change over time even though the distribution of the input data has not changed. For example, loan applicants who were considered as attractive prospects last year (when the training dataset was created) may no longer be considered attractive because of changes in a bank’s strategy or outlook on future macroeconomic conditions. Similarly, people’s interest in product categories has changed during the COVID pandemic, leading to stocking failures as many retail prediction models continued to predict based on training data for pre-COVID consumer interest.
As an illustrative example of concept drift, consider how a sentiment model created thirty years ago may falsely classify the sentiment of various words and phrases, as the way we speak, words that we use, and slang that we develop constantly change over time:

For models to work in such situations, it is necessary to monitor the model’s performance with respect to expectations about its results as they are today – captured through recent ground truth data – and not on past expectations from the model’s old training datasets.
Approaches to Identifying Model Degradation
Given the potential of significant negative impact from model degradation (e.g., consider the speed at which a bank could lose money due to a degraded loan default model), it is critical to detect model drift as soon as possible. Here are some recommendations for detecting model degradation before outdated models can cause serious impact to your business.
Checking Model Predictions: One common methodology for detecting model degradation involves checking if the model’s predictions are no longer valid or accurate. For example, a large insurance company identified that it was spotting far fewer fraudulent claims than it had in the past. The anomalous results led the company to review the accuracy more closely, once actual results (i.e., ground truth data) were available.
On the output side, many models produce some sort of score or set of scores, which often represent a probability estimate. If the score distribution produced by the model changes unexpectedly, that implies model degradation. This could be caused by a change to the model inputs that reflect some change in the outside world, or a change in the systems that the model depends on (e.g., for feature extraction). In either case, observing the change in score distributions is the first step in identifying the problem.
It is also important to assess if you can use ground truth data when assessing a model. As nice as real-time ground truth feedback may be, some use cases involve months or years of lag time to know the ground truth of a prediction, if they’re available at all. For instance, you may not know whether customers who are predicted to default on a 30-year mortgage are actually defaulting for many years. But you can use the distribution analysis and other techniques outlined above, if using ground truth data is not feasible.
Checking (Input) Data Drift: One of the most effective approaches to detecting model degradation is monitoring the input data presented to a model to see if they have changed; this addresses both data drift and data pipeline issues. There are several effective approaches to checking input data, including:
- Reviewing descriptive statistics, data types (e.g., strings, integers, etc.), data ranges, and data sparsity/missing data, and then comparing them to the original training data. Drastic changes in input data distributions may highlight serious model degradation.
- Defining metrics to track the difference between data used to train the model versus data that are being presented to the model to score. If the difference crosses a threshold or is drifting significantly, that is a strong indicator of model drift and degradation.
Note that some features are more important (predictive) than others. Important features that have drifted a small amount may be cause for retraining, while features with low/no predictive power can drift a lot with negligible impact on the overall model. It is important to identify the most important features to a model when you set up your monitoring, so you are tracking them closely.
Checking Concept Drift: Similarly to data drift distribution analysis, you can analyze concept drift using the same methods. Typically, you would compare the distribution of the labels of your training set versus those of your production data in real-time. You can also check that a) the input values fall within an allowed set or range, and b) that the frequencies of each respective value within the set align with what you have seen in the past. For example, for a model input of “marital status” you would check that the inputs fell within expected values such as “single”, “married”, “divorced”, and so on.
Organizational Best Practices for Monitoring Models
Approaches to model monitoring vary widely across companies - often even within a single company’s data science department! Typically, data science leaders carry the burden of monitoring model drift and model health as ultimately their teams are responsible for the quality of predictions that models are making. Data scientists then spend a significant amount of time analyzing models in production instead of doing new research. Some data scientists, in an effort to reduce manual effort, then develop ad hoc monitoring solutions for each model, leading to a proliferation of disparate, inconsistent, poorly maintained and half-baked monitoring solutions.
Other companies require that the IT department be responsible for production model monitoring. This puts both a time and education burden on already overburdened IT departments. Traditional IT tools and experiences apply to monitoring infrastructure, uptime, and latency, and do not translate well to model monitoring, which is more dependent on statistical methods.
Another approach requires the creation of a new role inside the organization. An ML Engineer is part data scientist and part software engineer, and needs to be proficient with DevOps and model monitoring best practices to alleviate the burden on data science and IT teams. As the number of models in production grows, so does the number of ML Engineers that a company needs to hire and retain.
Model Monitoring with Domino
Given the criticality of data science models to your business, you need to have a production monitoring system in place. Without observability, maintaining an end-to-end model lifecycle is an impossibility. You do not want to be caught unaware of critical production models deteriorating beyond acceptable levels.
Domino Model Monitor (DMM) provides a single pane of glass for automated model monitoring and proactive alerting across all your production models. With this model health dashboard, it is reasonable for IT to assume much of the responsibility for monitoring data science models. DMM can send alerts to the IT team, data scientists, as well as other interested parties, so model degradation identification becomes integrated into your workflows.
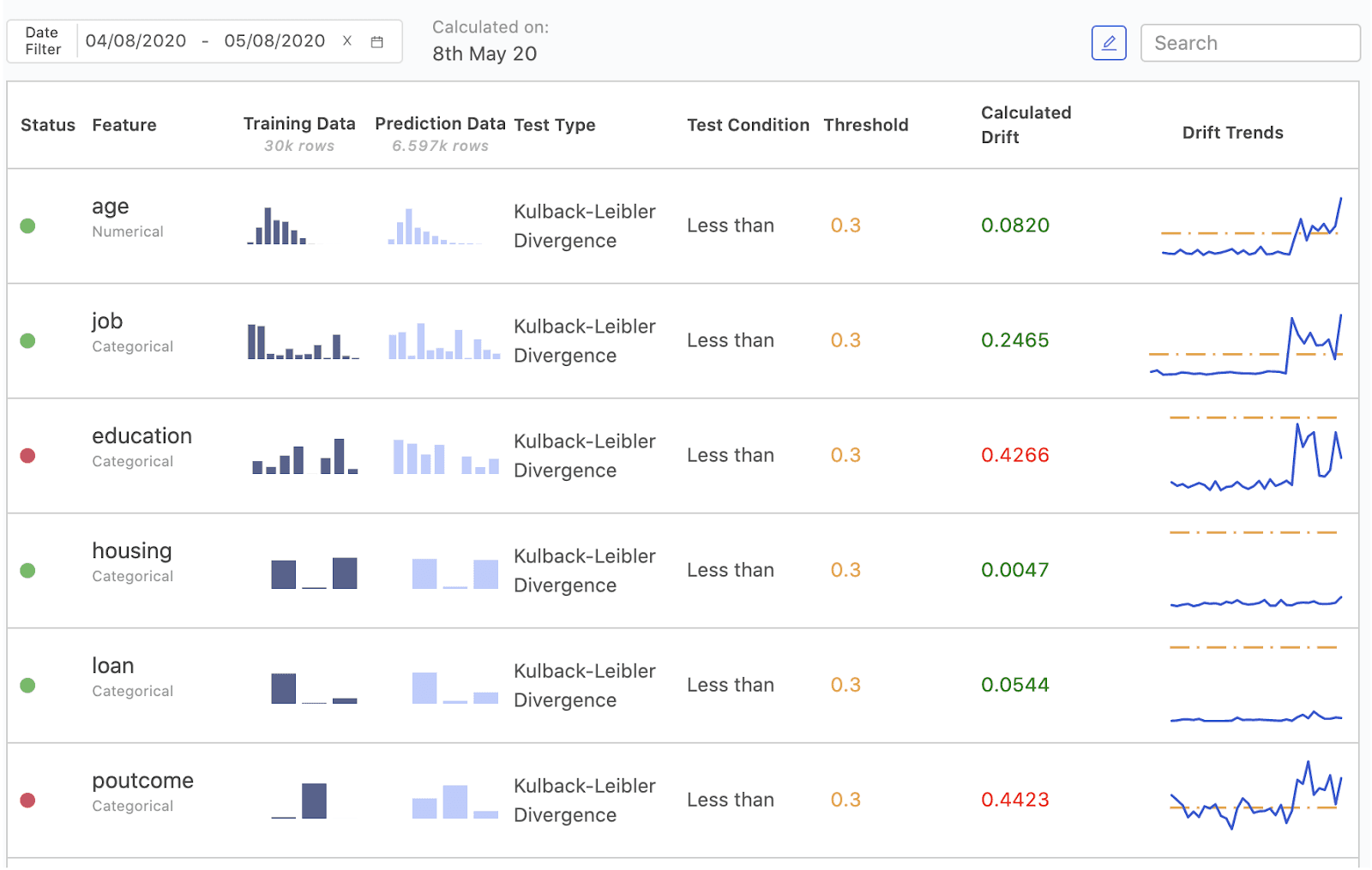
DMM detects and tracks data drift in the model’s input features and output predictions. If you have ground truth data for the model, DMM can ingest it to calculate and track the model’s prediction quality using standard measures such as accuracy, precision, and more.
DMM checks if the characteristics of the predictions versus the target data that were used to train the model are significantly different. DMM also tracks the difference between data that were used to train the models versus the data that are being presented to the models to score.
By setting up scheduled checks, using APIs to ingest data, and configuring alert notification recipients in DMM, you can continuously monitor hundreds of models in a standardized way across your organization. APIs enable integration into existing business processes, as well as a programmatic option for auto retraining. DMM enables both your IT department and data scientists to be more productive and proactive around model monitoring, without requiring excessive data scientist time.
Conclusion
As your company moves more machine learning systems into production, it is necessary to update your model monitoring practices to remain vigilant about model health and your business’ success in a consistent, efficient manner. Approach monitoring ML models the same way you would think about getting your annual physical check-up or getting periodic oil changes for your car. Model monitoring is a vital operational task that allows you to check that your models are performing to the best of their abilities.
In addition to providing recommendations for establishing best practices for model monitoring, Model Monitoring Best Practices: Maintaining Data Science at Scale, offers advice on how to estimate its impact, analyze the root cause, and take an appropriate corrective action.